前身となった記事
2つを掛け合わせたような記事です.
タグ同士のリンク情報に加えて,記事内容をベクトル化したものを加えることで,さらに良い推論結果が出せるのではないかということで実践してみることにしました.Heterogeneous Graphをカスタムデータに使ってみたいという方におすすめです.
以下の流れで実装を進めていきます.
- データセットの用意
- テキストデータをベクトル化
- グラフデータを用意する
- 学習
- 評価
実装のnotebookはgithubに挙げてますので,記載していない細かい部分が気になる方はそちらを参照してください.(あまり精査してませんが)
https://github.com/taguch1s/qiita-tag-recommend/tree/main
いろいろ細かい部分はスルーしてとりあえず実装までこぎつけた感じなので,気になる部分がありましたらご教授いただけますと幸いです.
データセットの用意
Qiita api を用いてデータセットを用意します.uploadされていたデータは見つからなかったので参考文献でも触れられていた2つの記事を見つつ自分で作ります.
初めは全件参照してデータセットを作成する予定だったのですが,本文のデータを使用する関係上かなりの量になってしまったので,1年分だけで我慢することにします.
謎に2018年からデータセットを作ってしまいましたが,普通に2023年にすればよかったと後悔しています...
作成したデータをdumpして見てみます.データセット件数は90313件でした.
テキストデータをベクトル化
テキストデータをクリーニング,分かち書き,doc2vecで学習という手順でベクトル化していきます.
クリーニング
機械学習・深層学習による自然言語処理入門 ~scikit-learnとTensorFlowを使った実践プログラミング~ 内で使用されていた前処理に若干追加して使用していきます.
これにコードとurlを除外する処理を追加します.
# cleaning function
# @see https://github.com/Hironsan/natural-language-preprocessings/blob/master/preprocessings/ja/cleaning.py
def clean_text(text):
if '\n' in text:
replaced_text = '\n'.join(s.strip() for s in text.splitlines()[2:] if s != '') # skip header by [2:]
else:
replaced_text = text # no replace
replaced_text = neologdn.normalize(replaced_text) # neologdnによる表記ゆれ統一
replaced_text = replaced_text.lower() # 小文字変換
replaced_text = re.sub(r'[【】]', ' ', replaced_text) # 【】の除去
replaced_text = re.sub(r'[()()]', ' ', replaced_text) # ()の除去
replaced_text = re.sub(r'[[]\[\]]', ' ', replaced_text) # []の除去
replaced_text = re.sub(r'[@@]\w+', '', replaced_text) # メンションの除去
replaced_text = re.sub(r'https?:\/\/.*?[\r\n ]', '', replaced_text) # URLの除去
replaced_text = re.sub(r'[!-/:-@[-`{-~]', r' ', replaced_text) # 半角記号の置き換え
replaced_text = re.sub(r'\d+', '0', replaced_text) #数値を0に置換
replaced_text = re.sub(r' ', ' ', replaced_text) # 全角空白の除去
return replaced_text
def clean_html_tags(html_text):
soup = BeautifulSoup(html_text, 'html.parser')
cleaned_text = soup.get_text()
cleaned_text = ''.join(cleaned_text.splitlines())
return cleaned_text
def clean_html_and_js_tags(html_text):
soup = BeautifulSoup(html_text, 'html.parser')
[x.extract() for x in soup.findAll(['script', 'style'])]
cleaned_text = soup.get_text()
cleaned_text = ''.join(cleaned_text.splitlines())
return cleaned_text
def clean_url(html_text):
"""
\S+ matches all non-whitespace characters (the end of the url)
:param html_text:
:return:
"""
clean_text = re.sub(r'http\S+', '', html_text)
return clean_text
def clean_code(html_text):
"""Qiitaのコードを取り除きます
:param html_text:
:return:
"""
soup = BeautifulSoup(html_text, 'html.parser')
[x.extract() for x in soup.findAll(class_="code-frame")]
cleaned_text = soup.get_text()
cleaned_text = ''.join(cleaned_text.splitlines())
return cleaned_text
def clean_all(text):
text = clean_text(text)
text = clean_html_tags(text)
text = clean_html_and_js_tags(text)
text = clean_url(text)
text = clean_code(text)
return text
# exec cleaning
df.title = df.title.apply(clean_text)
df.body = df.body.apply(clean_all)
綺麗になりました.
分かち書き
分かち書きとdoc2vecは以下の記事を参考に行いました.名詞の表層系のみを対象としていきます.動詞なども採用する際は,表記ゆれを回収するために原型を使用するのがいいらしいです.
import re, regex
import MeCab
#Neologdによるトークナイザー(文書ベクトル作成用・わかちだけ)
path = "/usr/lib/x86_64-linux-gnu/mecab/dic/unidic"
mecab = MeCab.Tagger(path)
#正規表現objectの宣言
re_kana = regex.compile(r'[\p{Script=Hiragana}\p{Script=Katakana}ーA-Za-z]+')
re_num = re.compile('[0-9]+')
def mecab_tokenizer(text : str):
words = []
tokens = mecab.parse(text).split("\n")[:-1]
# 名詞のみ表層形を取得
# https://qiita.com/shimajiroxyz/items/3922d6f7dc8e4b156692
for t in tokens:
if '\t' not in t:
continue
surface, pos = tuple(t.split('\t'))
pos = pos.split(',')
# 数字一文字の除外
if re_num.fullmatch(surface):
continue
#ひらがなまたはカタカナ一文字の除外
if re_kana.fullmatch(surface) and len(surface) == 1:
continue
if pos[0] == '名詞':
words.append(surface)
return words
Qiitaの記事はテキストデータとして長文なので,そのままmecab.parseに入力するとエラー1となってしまいます.
これを回避するために
- 文章をなんらかの単位で分割する
- 初めの何文字かを記事データとする
などの方法が挙げられますが,今回は後者を採用しました.(クリーニングの時点で改行コードを除いてしまったので,いい感じの分割対象が文字数しかない)
一応どこかで使うかもしれないので,文章分割を試したときのコードも書いておきます.
# 長文をそのままmecab.parseに入力するとエラーになるのである程度の文字数で分割します
# 単語の切れ目などにより単語分割されてしまうこともあるが,許容します
def split_text_into_chunks(text, n):
chunks = [text[i:i+n] for i in range(0, len(text), n)]
return chunks
def split_body_into_chunks(df, n):
df['body_chunks'] = df['body'].apply(lambda x: split_text_into_chunks(x, n))
return df
# 1000文字ごとにリストに分割
n = 1000
df = split_body_into_chunks(df, n)
df
# もしくは何文字かで区切ります
df['body'] = df.body.str[:5000]
doc2vec
記事内容とタイトルのテキストデータを結合してdoc2vecで学習させます.文書をベクトル化できるなら手法は何でもいいです.
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
l = df['text'].values.tolist()
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(l)]
model = Doc2Vec(documents, vector_size=100, window=7, min_count=1, workers=4, epochs=50)
model.save('text-embedding')
文書ベクトルしか使用しないので,モデル自体を保存しなくともベクトルだけnpyで保存しても問題ないです.
# save embedding
np.save('text-embeddimg-dv-100', model.dv.vectors)
グラフデータを用意する
NTT communicationsさまのheterogenerous Graphに関する記事と,pytorch-geometricのtutorial2 を参考させてもらい,タグのテキストデータをグラフで利用できる形に変換していきます.
タグのフィルタリング
閾値を下回る登場頻度のものを除外します.今回は5件以上にしました.
# {tag_count_threshod}回以上出現したタグのみを対象にする
import pandas as pd
import os
# load dataset
home = os.environ.get('HOME')
df = pd.read_table(f'{home}/data/qiita_2018_tag.tsv', low_memory=False)
# タグの出現回数をカウント
tag_counts = df['tags'].str.split(expand=True).stack().value_counts()
# 出現回数が5以上のタグを選択
tag_count_threshod = 5
filtered_tags = tag_counts[tag_counts >= tag_count_threshod].index
# タグをフィルタリング
df['filtered_tags'] = df['tags'].apply(lambda x: ' '.join([tag for tag in str(x).split() if tag in filtered_tags]))
print(df['filtered_tags'])
# df = df.drop(['tags'], axis=1)
タグをテキストからidに変換
扱いやすいようにtag_idを設定して,テキストとのmappingを作ってdataframeに入れておきます.
# フィルタ後のタグ群をtag_idに振りなおします
tag = df.filtered_tags.str.split(' ').explode().unique()
tag_id = range(0, len(tag))
# idとテキストのmapping 元に戻せるならなんでもOK
df_tag = pd.DataFrame({'tag_id':tag_id, 'tag_text':tag})
df_tag
tag_idとテキストのmappingが出来ました.今回は4811件のタグがあるみたいです.
tag_id tag_text
0 0 Xcode
1 1 iOS
2 2 数学
3 3 最適化
4 4 Node.js
... ... ...
4806 4806 0x
4807 4807 dex
4808 4808 かしゆか
4809 4809 Bootstrap-Table
4810 4810 大晦日ハッカソン
これを使用してタグのテキストデータをtag_idにreplaceしていきます.もっと早い方法がありそうですが,とりあえずのfor文です.
def convert_tag_texts_to_ids(tags:str, df_tag:pd.DataFrame):
tags = tags.split(' ')
tag_ids = []
# テキストからidに変換してlistに格納します
for tag in tags:
tag_id = df_tag[df_tag.tag_text == tag].tag_id.values[0]
tag_ids.append(tag_id)
return tag_ids
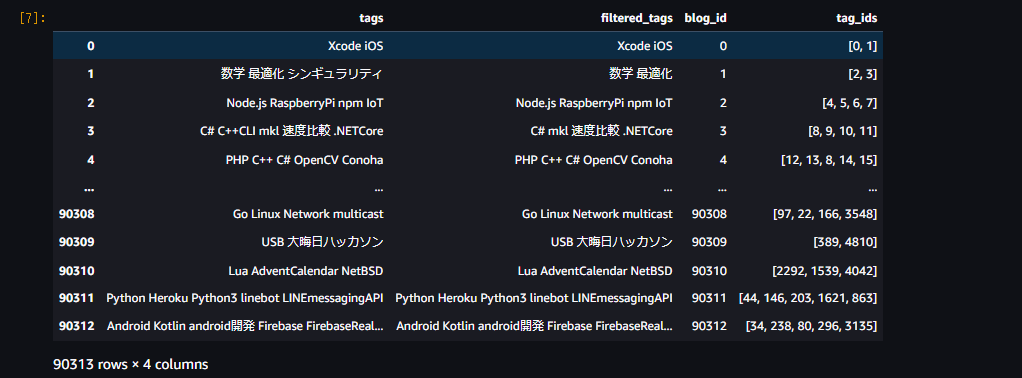
df['tag_ids'] = df['filtered_tags'].apply(convert_tag_texts_to_ids, df_tag=df_tag)
これで 記事のid(blog_id)とtag_idの組み合わせが扱えるようになりました.
blog_idとtag_idの組み合わせ
グラフのedgeを表現するために,blog_idとtag_idの組み合わせを作ります.
df_tagged = df[['blog_id', 'tag_ids']].explode(column='tag_ids')
これでグラフ構造に落とし込めるデータが出来ました.
blog_id tag_ids
0 0 0
0 0 1
1 1 2
1 1 3
2 2 4
... ... ...
90312 90312 34
90312 90312 238
90312 90312 80
90312 90312 296
90312 90312 3135
228046 rows × 2 columns
グラフデータ整形
ここからは参考をなぞっているだけなので,折りたたんでおきます
code
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
from torch import Tensor
from torch.nn import Module
import torch_geometric
import torch_geometric.transforms as T
from torch_geometric.nn import SAGEConv, to_hetero
from torch_geometric.data import HeteroData
from torch_geometric.loader import LinkNeighborLoader
# ブログIDとタグIDのエッジ情報をTensorへ変換
tagged_blog_id = torch.from_numpy(df_tagged['blog_id'].values)
tagged_tag_id = torch.from_numpy(df_tagged['tag_ids'].to_numpy(dtype='int32'))
edge_index_blog_to_tag = torch.stack(
[tagged_blog_id, tagged_tag_id],
dim=0,
)
print("Final edge indices pointing from blogs to tags:")
print("=================================================")
print(edge_index_blog_to_tag)
from torch_geometric.data import HeteroData
import torch_geometric.transforms as T
data = HeteroData()
# Save node indices:
data["blog"].node_id = torch.arange(len(df))
data["tag"].node_id = torch.arange(len(df_tag))
# Add the node features and edge indices:
## 1.学習したtext-embeddingの読み込み
blog_features = np.load('text-embeddimg-dv-100.npy')
blog_features = torch.from_numpy(blog_features).to(torch.float)
## 2.乱数で仮置き
# text_feature_dim = 100
# blog_features = torch.randn(data['blog'].num_nodes, text_feature_dim)
## data setup
data["blog"].x = blog_features # TODO
data["blog", "tagged", "tag"].edge_index = edge_index_blog_to_tag # TODO
## 無向グラフ化
data = T.ToUndirected()(data)
print(data)
assert data.node_types == ["blog", "tag"]
assert data.edge_types == [("blog", "tagged", "tag"),
("tag", "rev_tagged", "blog")]
assert data["blog"].num_nodes == 90313
assert data["blog"].num_features == 100
assert data["tag"].num_nodes == 4811
assert data["tag"].num_features == 0
assert data["blog", "tagged", "tag"].num_edges == 228046
学習
code
# 学習・評価用のデータ分割
transform = T.RandomLinkSplit(
num_val=0.1,
num_test=0.1,
disjoint_train_ratio=0.3,
# neg_sampling_ratio=2,
add_negative_train_samples=False,
edge_types=("blog", "tagged", "tag"),
rev_edge_types=("tag", "rev_tagged", "blog"),
)
train_data, val_data, test_data=transform(data)
# 学習用データローダー定義
edge_label_index = train_data["blog", "tagged", "tag"].edge_label_index
edge_label = train_data["blog", "tagged", "tag"].edge_label
train_loader = LinkNeighborLoader(
data=train_data,
num_neighbors=[20, 10],
neg_sampling_ratio=2,
edge_label_index=(("blog", "tagged", "tag"), edge_label_index),
edge_label=edge_label,
batch_size=256,
shuffle=True,
)
# 検証用データローダー定義
edge_label_index = val_data["blog", "tagged", "tag"].edge_label_index
edge_label = val_data["blog", "tagged", "tag"].edge_label
val_loader = LinkNeighborLoader(
data=val_data,
num_neighbors=[20, 10],
edge_label_index=(("blog", "tagged", "tag"), edge_label_index),
edge_label=edge_label,
batch_size=3 * 256,
shuffle=False,
)
# モデル定義
class GNN(Module):
def __init__(self, hidden_channels: int):
super().__init__()
self.conv1 = SAGEConv(hidden_channels, hidden_channels)
self.conv2 = SAGEConv(hidden_channels, hidden_channels)
def forward(self, x: Tensor, edge_index: Tensor) -> Tensor:
x = self.conv1(x, edge_index).relu()
x = self.conv2(x, edge_index)
return x
class Classifier(Module):
def forward(
self, x_blog: Tensor, x_tag: Tensor, edge_label_index: Tensor
) -> Tensor:
edge_feat_blog = x_blog[edge_label_index[0]]
edge_feat_tag = x_tag[edge_label_index[1]]
return (edge_feat_blog * edge_feat_tag).sum(dim=-1)
class Model(Module):
def __init__(self, hidden_channels: int):
super().__init__()
self.blog_lin = torch.nn.Linear(100, hidden_channels)
self.blog_emb = torch.nn.Embedding(data["blog"].num_nodes, hidden_channels)
self.tag_emb = torch.nn.Embedding(data["tag"].num_nodes, hidden_channels)
self.gnn = GNN(hidden_channels)
self.gnn = to_hetero(self.gnn, metadata=data.metadata())
self.classifier = Classifier()
def forward(self, data: HeteroData) -> Tensor:
x_dict = {
"blog": self.blog_lin(data["blog"].x) + self.blog_emb(data["blog"].node_id),
"tag": self.tag_emb(data["tag"].node_id),
}
x_dict = self.gnn(x_dict, data.edge_index_dict)
pred = self.classifier(
x_dict["blog"],
x_dict["tag"],
data["blog", "tagged", "tag"].edge_label_index,
)
return pred
# 学習と評価
def train(model, loader, device, optimizer, epoch):
model.train()
for epoch in range(1, epoch):
total_loss = total_samples = 0
for batch_data in tqdm(loader):
optimizer.zero_grad()
batch_data = batch_data.to(device)
pred = model(batch_data)
loss = F.binary_cross_entropy_with_logits(
pred, batch_data["blog", "tagged", "tag"].edge_label
)
loss.backward()
optimizer.step()
total_loss += float(loss) * pred.numel()
total_samples += pred.numel()
print(f"Epoch: {epoch:04d}, Loss: {total_loss / total_samples:.4f}")
def validation(model, loader, device, optimizer):
y_preds = []
y_trues = []
model.eval()
for batch_data in tqdm(loader):
with torch.no_grad():
batch_data = batch_data.to(device)
pred = model(batch_data)
y_preds.append(pred)
y_trues.append(batch_data["blog", "tagged", "tag"].edge_label)
y_pred = torch.cat(y_preds, dim=0).cpu().numpy()
y_true = torch.cat(y_trues, dim=0).cpu().numpy()
auc = roc_auc_score(y_true, y_pred)
return auc, y_pred, y_true
# パラメータセット
model = Model(hidden_channels=64)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
model = model.to(device)
# 学習・評価
train(model, train_loader, device, optimizer, 6)
auc, y_pred, y_true = validation(model, val_loader, device, optimizer)
評価
ベースラインとして,ランダムで用意したfeatureと,doc2vecで用意したfeatureを比較してみます.
ramdom feature
Epoch: 0001, Loss: 0.5177
Epoch: 0002, Loss: 0.4015
Epoch: 0003, Loss: 0.3771
Epoch: 0004, Loss: 0.3581
Epoch: 0005, Loss: 0.3409
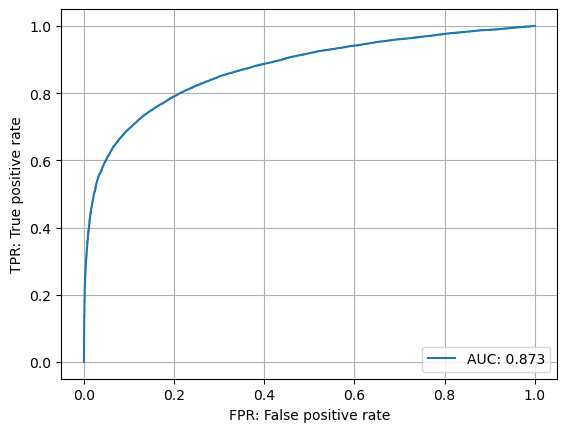
- ランダムなfeatureでもかなりの精度が出る
- 記事とタグの関係性(グラフ情報)だけで完結してるのかもしれない
doc2vec feature
Epoch: 0001, Loss: 0.4902
Epoch: 0002, Loss: 0.3546
Epoch: 0003, Loss: 0.3175
Epoch: 0004, Loss: 0.2909
Epoch: 0005, Loss: 0.2741
確かに改善が見られました
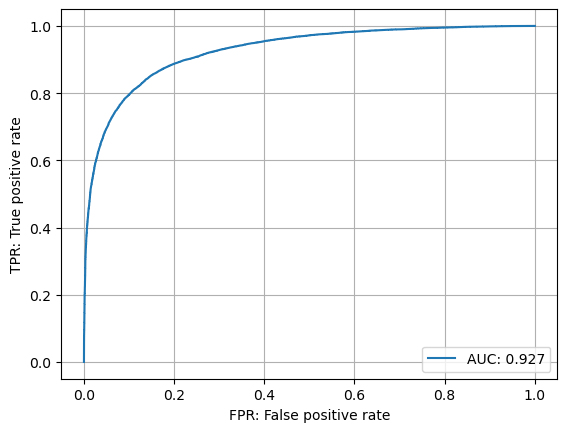
定性評価
WIP
- 学習に使用していないtest_loaderから「記事にまだついていないがつく可能性が高いもの」を推論してまとめてみようと思っていたが,技術力が足りずにまだ調査中
- なぜかtest_loaderにも負例データが入ってしまっているので,扱いにくい
>> test_data["blog", "tagged", "tag"].edge_label
tensor([1., 1., 1., ..., 0., 0., 0.])
所感
- Qiitaのデータは必ずタグが1つ以上ついているので,グラフ構造として利用しやすい
- タグが付いていないデータからの推論は,グラフ構造に入れられないため不可なのかが気になるところ
- blog-tagの2部グラフとして構成したためにグラフから浮いた構造になってしまうのが問題なので,user-blog-tag などの3部グラフにすればよさそう
- 論文3としては出ているようだが,それをコードに落とし込む実力がない 悲しいね
- タグが付いていないデータからの推論はtag-aware-recommendation というタスクが要件を満たせるかも
- contents-based というよりはX(Twitter), StackOverflowなどのuser-basedなものが多いので,Qiitaデータもこっちが向いてるかも