経緯
Windows環境で動作しているPythonスクリプトでテキストファイルのソートが必要になりました。
要件としては次のようなものです。
- Windows環境で実行
- 対象ファイルは数GBのCSVファイル
- ソートキーは複数のカラムで数値のカラムもある
Windowsコマンドプロンプトにはsortコマンドがあり、巨大なファイルのソートには対応しています。
しかしLinuxのsortコマンドと違い、区切り文字を指定したり(-t)、数値としてソート(-n)することはできません。
サイズが小さければPythonスクリプトで全データをメモリに読み込んでsorted関数を呼べば済むのですが、サイズが大きい場合はメモリ不足になる可能性があります。
仕方がないのでPythonで巨大なファイルに対応したソート処理を実装することにしました。
処理手順
巨大なデータをソートするにはマージソートの考え方で以下のように処理します。
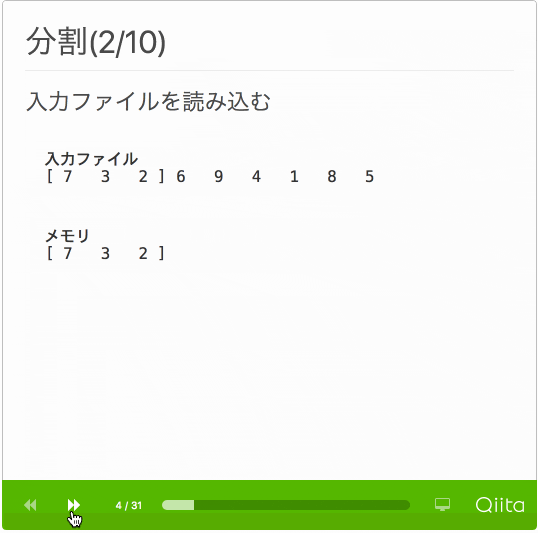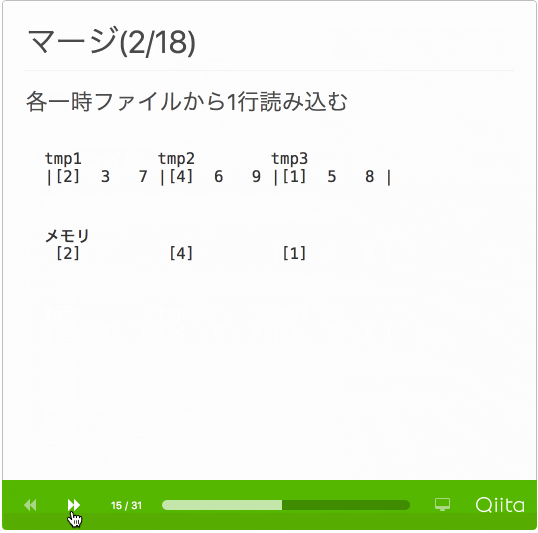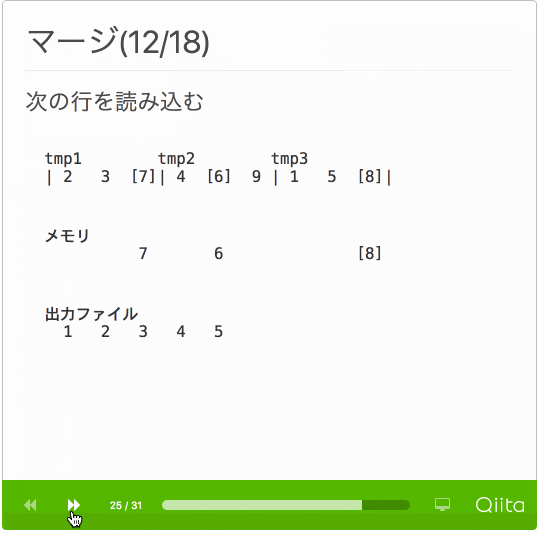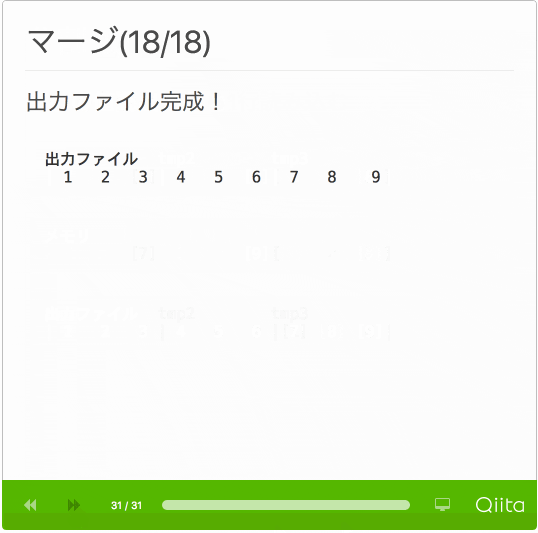
- 分割
- 入力ファイルからメモリに乗る程度の行数を読み込む
- 読み込んだ部分をソートして一時ファイルに書き出す
- 入力ファイルを全て読み込むまで繰り返す
- マージ
- 各一時ファイルから1行ずつ読み込む
- 一番小さい値を出力ファイルへ書き込む
- 全一時ファイルを読み終えるまで繰り返す
動作がわかるように処理手順のスライドを作成しました。
実装方法
分割
ファイルを分割して読み込むにはio.IOBase.readlinesを使用します。
readlinesを引数なしで使うと全行がメモリに読み込まれるので、ファイルサイズが大きい場合にreadlinesを使うことはアンチパターンとして知られています。
しかしreadlinesは引数で読み込むバイト数/文字数を制限することができて、これを使うと巨大なテキストファイルでも分割して読み込むことができます。
>>> from io import StringIO
>>> f = StringIO("11\n22\n3\n4\n5\n666666\n")
>>> f.readlines(5)
['11\n', '22\n']
>>> f.readlines(5)
['3\n', '4\n', '5\n']
>>> f.readlines(5)
['666666\n']
>>> f.readlines(5)
[]
バイナリモードでオープンしているファイルの場合はバイト数、テキストモードの場合は文字数になるようです。
マージ
マージにはheapq.mergeを使用します。
heapq.mergeはソート済みの複数のiterableをマージした結果を返します。
>>> import heapq
>>> list(heapq.merge([1, 3, 4, 7], [2, 5], [6]))
[1, 2, 3, 4, 5, 6, 7]
ソース
gistに上げてあります。
Pythonバージョンは3.6です。
以下はソート部分の抜粋です。
import heapq
import os
from contextlib import contextmanager
from operator import itemgetter
from tempfile import TemporaryDirectory, mktemp
from typing import IO, Callable, List
def large_sort(input_file: IO, output_file: IO, key: Callable=None, reverse: bool=False, limit_chars: int=1024*1024*64):
with TemporaryDirectory() as tmp_dir:
for lines in _read_parts(input_file, limit_chars):
lines = sorted(lines, key=key, reverse=reverse)
_write_part(lines, tmp_dir)
with _open_tmp_files(tmp_dir) as tmp_files:
for row in heapq.merge(*tmp_files, key=key, reverse=reverse):
output_file.write(row)
def _read_parts(input_file, limit_chars):
lines = input_file.readlines(limit_chars)
while lines:
yield lines
lines = input_file.readlines(limit_chars)
def _write_part(lines, tmp_dir):
tmp_filename = mktemp(dir=tmp_dir)
with open(tmp_filename, "w") as tmp_file:
tmp_file.writelines(lines)
return tmp_filename
@contextmanager
def _open_tmp_files(tmp_dir):
filenames = os.listdir(tmp_dir)
files = [open(os.path.join(tmp_dir, filename), "r") for filename in filenames]
try:
yield files
finally:
for file in files:
file.close()
今回の要件では別のPythonスクリプトから呼び出す関数が欲しかったので不要なのですが、gistのソースではlinuxのsortコマンドを参考にコマンドラインから使えるようにしてあります。
他の案
今回は自作しましたが、他の解決方法もあるので書いておきます。
- CygwinなどのLinuxコマンド使える系環境を使用する
- 今回は実行環境が非エンジニアのPCだったので「Cygwinインストールして」とは言いづらいので却下
- sort.exeと必要なdllだけ抜き出して同梱するということはできそう
- フリーのソートツールを使用する
- 軽く探してみたけどコマンドラインから使えて要件を満たすのが見つからなかった
- 多分ちゃんと探せば見つかりそう
- PowerShellのsortコマンド
- コマンドプロンプトのsortコマンドより高機能らしいけど未確認