こんにちは!
今回はPostmanからOpenAIのAPIリクエストを送信して日本語の音声ファイルを英語スピーチに変換してみます。
使うAPIはこちら↓
- Create translation:英語以外のオーディオファイル(flac, mp3, mp4, mpeg, mpga, m4a, ogg, wav, webm)を英語に変換してJSON形式のテキストで返してくれる。
- Create speech:テキストを読み上げてオーディオファイルを返してくれる。日本語も対応している。他の対応言語はこちら。
まずは、Postmanのワークスペース上にコレクションを作ります。
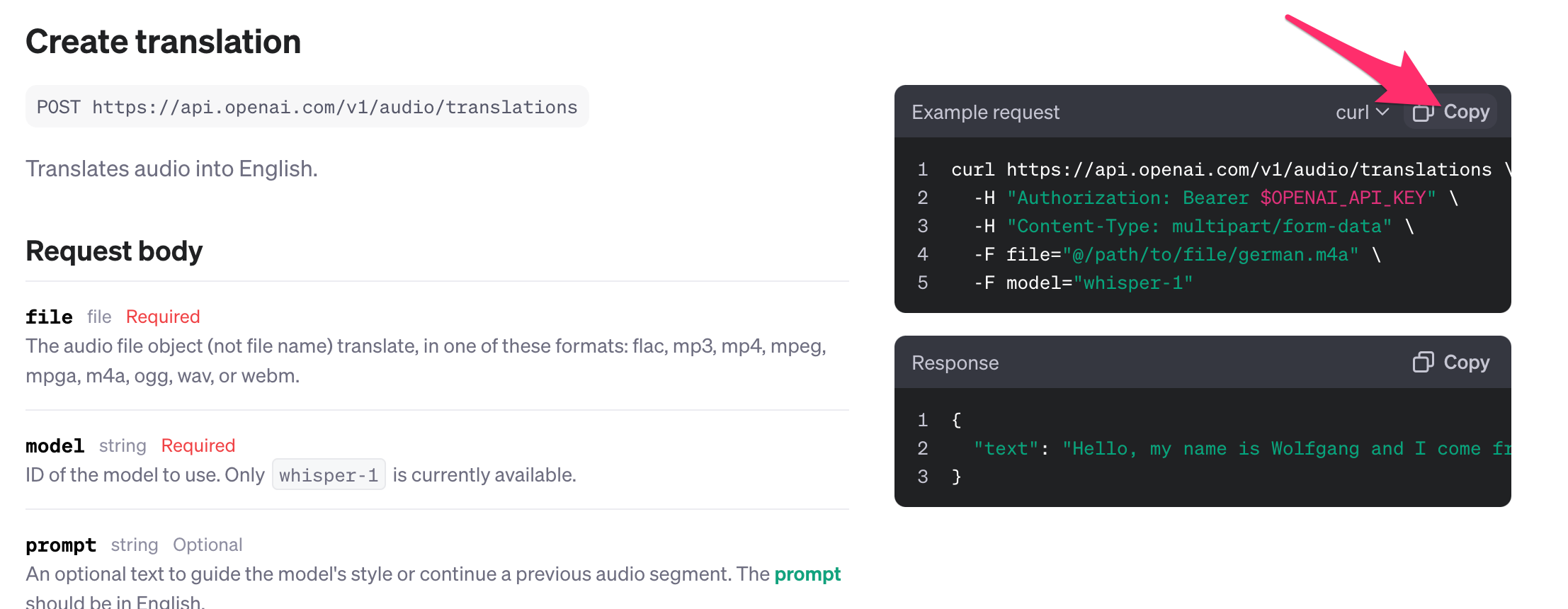
上のOpenAIのページのExample requestの横のCopyアイコンをクリックしてコピーします。
Postmanのワークスペースのインポートをクリックして、インポート画面を開いたらそこにペーストします。


すると、リクエストとして読み込んでくれるので、先ほど作ったコレクションに保存します。
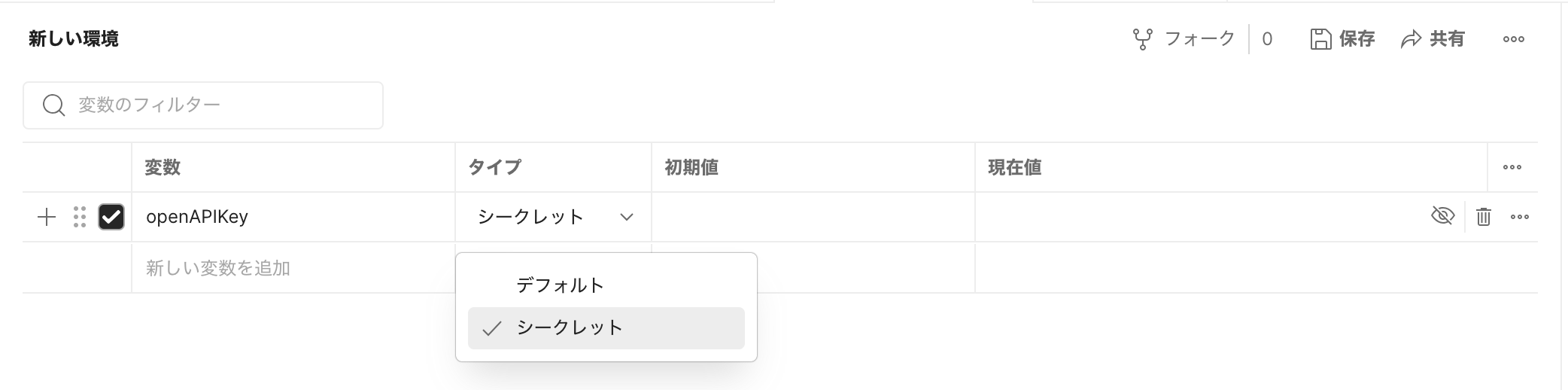
リクエストを送るにはAPIキーが必要なので、OpenAIのダッシュボードのAPI KeysのメニューからAPIキーを作成します。
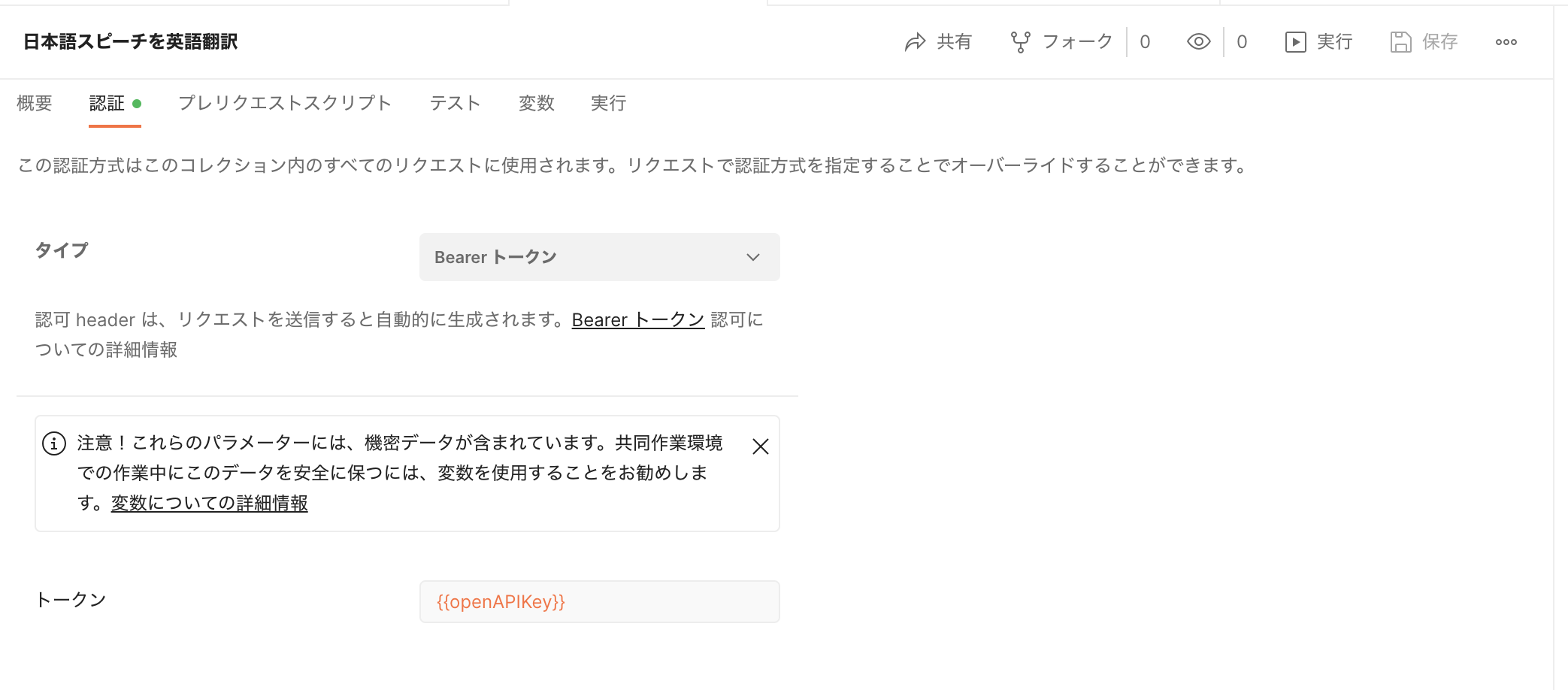
作成したAPIキーはコレクションの認証ページにBearerトークンとして指定します。これでコレクション内のリクエストにはこの認証方法が適用されます。
セキュリティの面からAPIキーは環境変数に登録することをお勧めします。環境変数だとシークレットタイプが選べます。現在値のカラムにAPIキーを入力します。
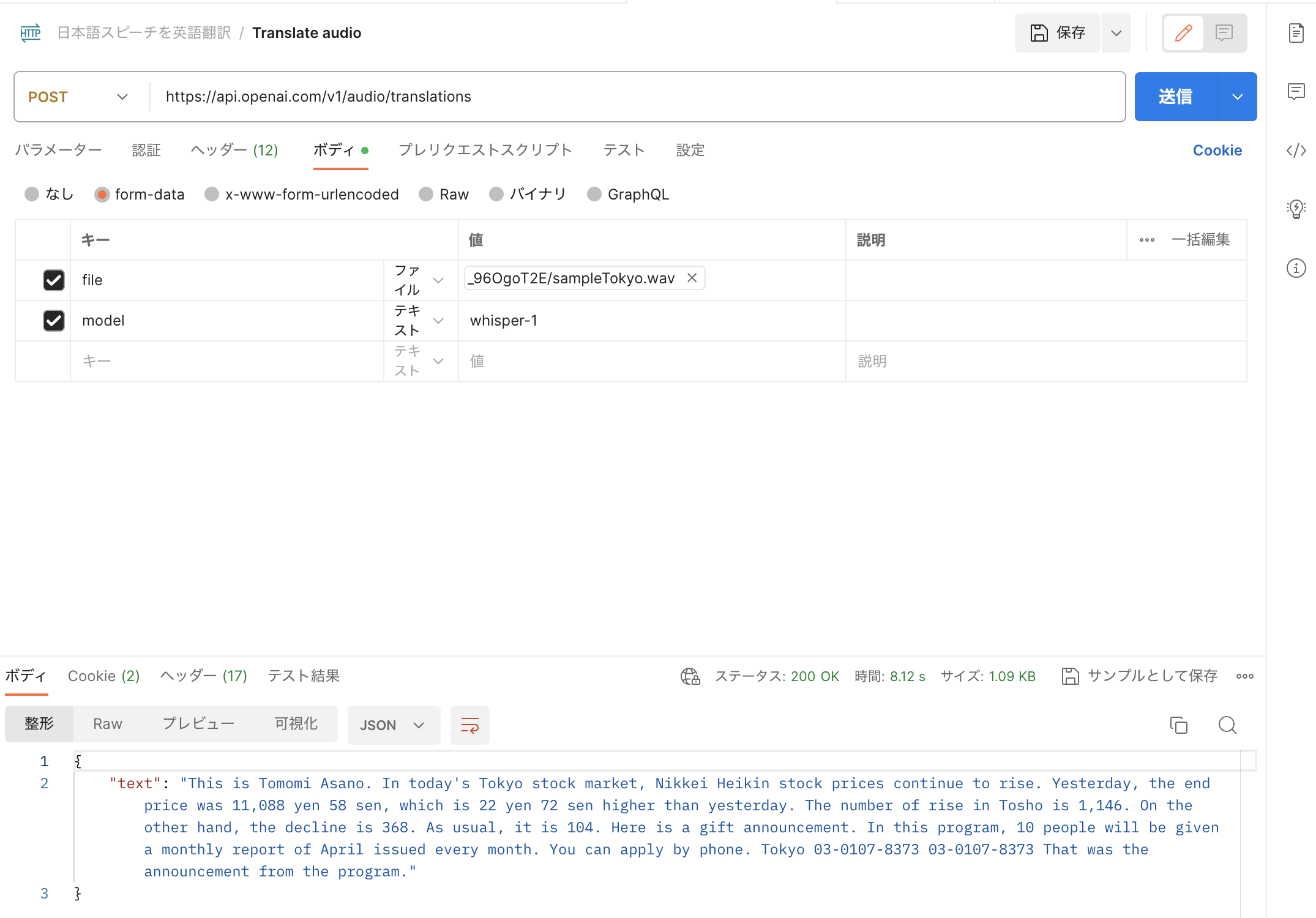
さて早速、適当な音声ファイルを使って試してみましょう。(サンプル音声はここから拾ってきました)
次にやりたいのは、この英語テキストをスピーチ(音声ファイル)にしたいので、Create speechエンドポイントを使います。先ほどと同様の方法で、OpenAIのページからExample requestをコピーしてPostmanのコレクションにリクエストを作成します。
上のCreate translationのリスポンスのテキストをCreate speechリクエストのinputプロパティに指定したいので、ここは"input_text"という変数にします。

さらにCreate translationリクエストのテストタブを開いてリスポンスを環境変数に設定する、というスクリプトを書きます。

これで完成です。Create translationリクエスト→Create speechリクエストの順でリクエストを送信することで、日本語の音声ファイルから英語スピーチを作成することができます。
完成したコレクションはこちら。