目的
インタプリタやコンパイラを実装しようとするときのディスパッチ手法はいくつかあります。
- スイッチスレッディング
- トークンスレッディング
- 直接スレッディング
などなど。
Wikipedia を見ると解説があります。
C++ 上で実装したときにどの程度性能差があるのか比較してみたいと思いました。
スイッチスレッディングのベンチマークプログラム
プログラムカウンタ変数 pc を設けて、その値によってディスパッチ先処理を切り替えます。
こんな感じでベンチマークプログラムを作ってみました。
// ジャンプ命令。プログラムカウンタに next_pc を設定してディスパッチする。
#define MACRO_jump(next_pc) \
{ \
pc = (next_pc); \
continue; \
}
// 与えられた回数ディスパッチを繰り返す(1000回で丸める)
int test(int n) {
int pc = 0; // 分岐先決定用のプログラムカウンタ
int i = 0; // ディスパッチ回数のカウンタ
for (;;) {
switch (pc) {
case 0:
++i;
MACRO_jump(1);
case 1:
++i;
MACRO_jump(2);
case 2:
++i;
MACRO_jump(3);
:
(略)
:
case 998:
++i;
MACRO_jump(999);
default:
++i;
if (i >= n) {
return i;
}
pc = 0;
}
}
}
各ベンチマークプログラムでの見た目を近づけるために、分岐部分はマクロ化(MACRO_jump)しています。
トークンスレッディングのベンチマークプログラム
プログラムカウンタの値を元に分岐先テーブル上の分岐先アドレスを引いて、そこにジャンプします。
分岐先ラベルのアドレスをテーブルに入れておく前処理が必要です。
&& でラベル位置を void ポインタ化するのは非標準機能(GCC 拡張)なのですが、多くの C++ コンパイラで利用可能らしいです。
// ジャンプ命令。プログラムカウンタに next_pc を設定してディスパッチする。
#define MACRO_jump(next_pc) \
goto *tbl[next_pc]
// 与えられた回数ディスパッチを繰り返す(1000回で丸める)
int test(int n) {
void* tbl[1000] = {0};
// ---- ここから、分岐先テーブルのセットアップ
tbl[0] = &&L0;
tbl[1] = &&L1;
tbl[2] = &&L2;
:
(略)
:
tbl[999] = &&L999;
// ---- ここまで、分岐先テーブルのセットアップ
int i = 0;
L0:
++i;
MACRO_jump(1);
L1:
++i;
MACRO_jump(2);
L2:
++i;
MACRO_jump(3);
:
(略)
:
L999:
++i;
if (i >= n) {
return i;
}
MACRO_jump(0);
}
直接スレッディングのベンチマークプログラム
どの分岐から処理を開始するかを指定して外部から開始する、などという場合にはプログラムカウンタを受け渡しする必要があります。
しかし、処理ループ内部で分岐が閉じている場合には呼び出し側は分岐先ラベルを直接指定でき、プログラムカウンタすら不要です。
// ジャンプ命令。指定された分岐先にディスパッチする。
#define MACRO_jump(next_pc) \
goto L ## next_pc
// 与えられた回数ディスパッチを繰り返す(1000回で丸める)
int test(int n) {
int i = 0;
L0:
++i;
MACRO_jump(1);
L1:
++i;
MACRO_jump(2);
:
(略)
:
L999:
++i;
if (i >= n) {
return i;
}
MACRO_jump(0);
}
測定結果
1 億回ループしたときの実行時間(CPU 時間)を測定してみました。
「1 億回」というと多いようですが、マイ・GuardedHornClausesでのたらい回し関数ベンチマークではこのくらいのオーダーの分岐が発生している(もっと具体的に書くと、tarai(12,11,0) 相当の処理で 115138458 回)ので、割と現実的な数字です。
最適化なし(-O0)の場合
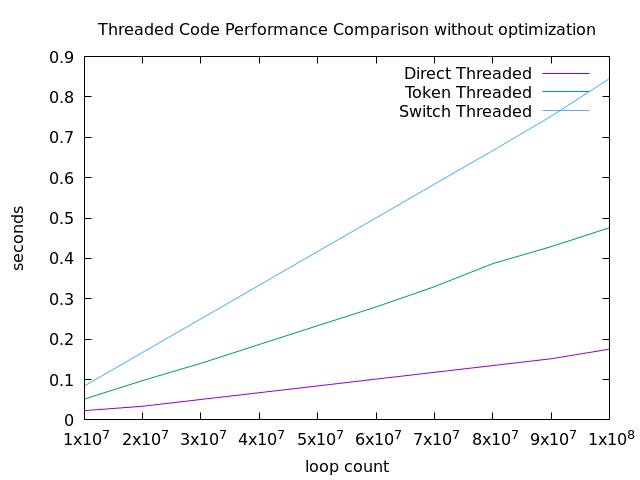
見てのとおり、性能的には
スイッチスレッディング < トークンスレッディング < 直接スレッディング
でした。
最適化あり(-O3)の場合
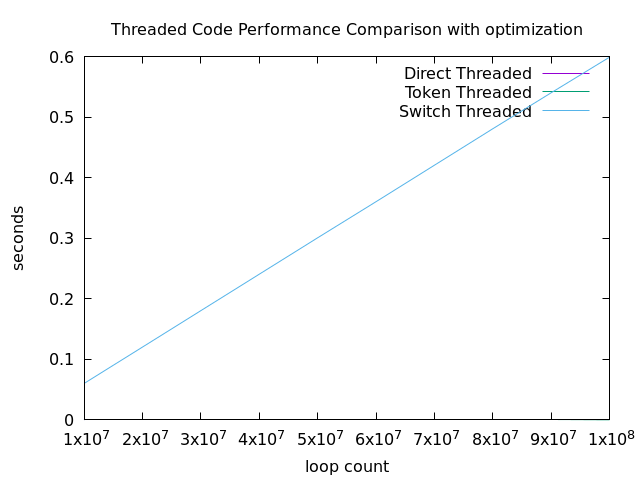
スイッチスレッディングの場合、最適化を有効にすると多少の改善が見えます。
トークンスレッディング、直接スレッディングについては最適化を有効にするとほぼ実行時間が0になってしまいました。
一応、ログスケールで表示すると以下のように確認できます。
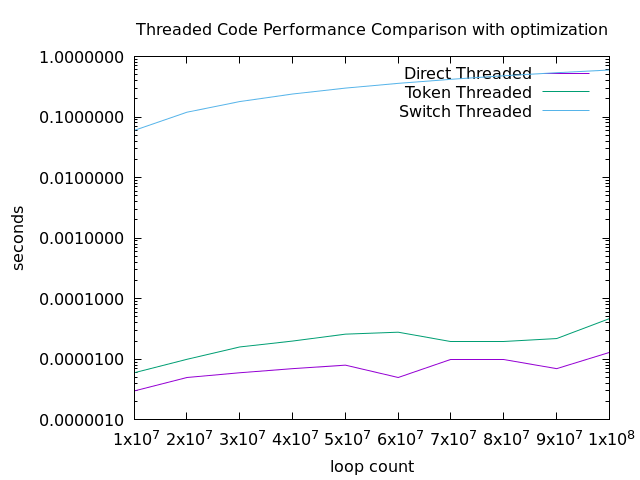
残念ながらスイッチスレッディングにはあまり最適化が奏効しておらず、結果として
スイッチスレッディング <<< トークンスレッディング < 直接スレッディング
のような形になっています。
まとめ
スイッチスレッディングは実装しやすく移植性も高いのですが、実行時間がそれなりにかかることがわかりました。
通常のプログラムだとスイッチ文のコストを気にすることはないのですが、インタプリタのように繰り返し回数が尋常でない場合には処理時間も無視できなくなります。
マイ・GuardedHornClauses はスイッチスレッディングを利用していて、たらい回し関数(tarai(12,11,0)) 実行に 2.2 秒を要していますが、この実行時間には 115138458 回の分岐処理時間も含んでいます。115139000 回のスイッチスレッディング分岐処理ベンチマークを採ってみると 0.68 秒であることから、スイッチスレッディング部分を修正すると最大 0.68 秒処理時間を短縮可能と推測できます。
追記
試しに、現在スイッチスレッデッドで作成しているコンパイラをダイレクトスレッデッド化して効果があるのか検証してみました。
ベンチマーク(g++ -O3) |
スイッチスレッデッド版 | ダイレクトスレッデッド版 |
|---|---|---|
| hanoi(21) | 0.302846 sec. | 0.437475 sec. |
| 11-Queen | 0.990262 sec. | 1.89302 sec. |
| tarai(12, 11, 0) | 2.200770 sec. | 3.42633 sec. |
「ダイレクトスレッデッド化で速くなることはあっても遅くなることはないはず」と信じていただけにとても残念な結果になりました。
上掲のベンチマークプログラム含めていつもは GCC を使っているのですが、思いつきで clang でも試してみました。
ベンチマーク(clang++ -O3) |
スイッチスレッデッド版 | ダイレクトスレッデッド版 |
|---|---|---|
| hanoi(21) | 0.29909 sec. | 0.290790 sec. |
| 11-Queen | 1.21362 sec. | 1.087100 sec. |
| tarai(12, 11, 0) | 2.65602 sec. | 2.304180 sec. |
clang ではダイレクトスレッデッド版の方が若干速くなっています。
ちょっと不思議です。