今回は RedShift に関する勉強記録となる.なお,記事は適宜更新していく.
基本情報
特徴
- リーダーノードと、コンピューターノードがいる
- データサイズは最大2PB
- 超並列(MPP)、列型志向DBエンジンによる高速SQL処理
- スケールアウト可能(最大128台)
-
PostgreSQLとの互換 - 管理機能がビルトインされている
- バックアップ機能:スナップショットをS3に保存
- Workload Management:実行に長い時間をようするクエリ(ロングクエリ)クラスタ全体のボトルネックとなり、ショートクエリを持たせる可能性がある.WLMで用途ごとに、クエリー並列どの上限を設けた複数のキューを定義することでクエリー処理の制御が可能.
データのロード
S3、DynamoDB、EMRなどからCOPYコマンドを使ってデータをロードするのがよい
S3からのデータロード
1.データを複数のファイルに分割する(圧縮もしとく
2.S3にファイルをアップロードする
3.COPYコマンドを実行してテーブルをロードする
4.データが正しくロードされたことを確認する
ストリームデータは、Firehose->S3->Redshiftにロードするのがよい
逆にRedshiftからS3へのエクスポートもMPPで多数のファイルに分割してエクスポートする
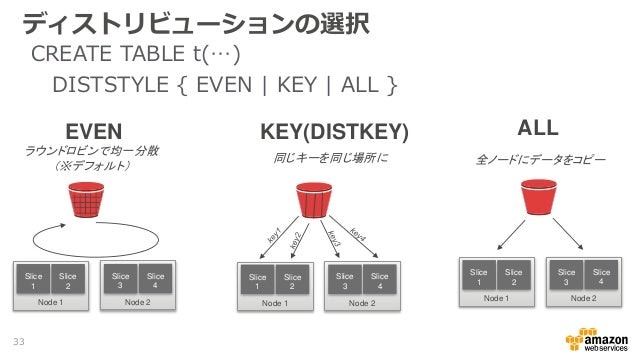
ディストリビューションの選択
CREATE TABLE .... DISTSTYLE {EVEN | KEY | ALL}
- EVEN : ラウンドロビンで均一分散(デフォルト)
- KEY(DISTKEY): 同じキーを同じ場所に
- ALL : 全ノードにデータをコピー
イメージ
AWS Black Belt Online Seminar Amazon Redshift from Amazon Web Services Japan
Redshiftの設計
・ノードスライス:ノード数×CPU数。Redshiftはノードスライごとにデータを格納し、各CPUがげ並列でデータ操作を行うことで超高速に大量のデータを処理できる
・分散キー(DISTKEY):ノードスライスにデータを振り分ける時の基準となる絡むのことをさす。Redshiftは分散キーに指定された各レコードの値のハッシュ値を計算してハッシュ値ごとにノードスライスにデータを分散させる。分散キーはテーブルに対して1つしか設定できない。分散の仕組みは、EVEN、KEY、ALL。
・ソートキー(SORTKEY):データの並び順を決める時の基準となるカラムのこと。そーとキーには最大で400個までカラムを指定できるが、MySQLのように複数のインデックスを貼ることはできない。複合インデックスにカラムを400個指定できるだけ。
分散キーの選定
・分散キーに指定するカラムの値は均等に分散されているか(なぜ?):
分散キーに指定した値が偏っている場合、ノードスライスごとに処理するデータ量に偏りが出てしまい、早く処理が終わってしまうノードスライスがあったとしても、一番データ量の多いノードスライスの処理が終わるまで待ちが発生してしまいます。したがって、各ノードスライスの処理時間が均一になるように分散キーに指定するカラムは値が均一に分散している必要があります。
・ノードスライスの数よりもあたいの種類が多いか(なぜ?):
ノードスライス数よりも分散キーに指定した値の種類が少ない場合、データが割り振られないノードスライスができてしまい分散処理の機能をフルで使うことができません。例えばCPU数が4個でノード数が4のノードスライス16に対して月のようなカラムを分散キーに指定すると4つのノードスライスにデータが割り振られないことになります。なので分散キーには指定するカラムはノードスライスよりも多くなるようなカラムを指定しなければいけません。
・分散キーがWHERE句の1番最初にはいっているか(なぜ?):
分散キーに指定したカラムをWHERE句の最初に指定している場合、データの入っているノードスライスが1つに確定されてしまいます。そのため他のノードスライスで処理する必要がなくなってしまい、分散処理を有効に活用することができません。したがって、WHERE句の最初に指定しないといけないようなカラムは分散キーには適していません。
ソートキーの選定
・ORDER BY, GROUP BYなどのソート処理で指定されるか:
クエリ実行時のソート処理を削減できるため実行時間を短くすることができます。
・WHERE句に指定してゾーンマップを有効にできるか:
Redshiftは1MBごとにデータブロックを作り、ソートキーに指定されたカラムの最小値と最大値をメタデータとして持つゾーンマップという仕組みがあります。ゾーンマップを使うことでデータのあるブロックをピンポイントに検索できるので処理を効率化することができます。
したがって、ソートキーをWHERE句の一番最初に指定すると高速で検索処理をすることができます。ソートキーにはCOMPOUND SORTKEYとINTERLEAVED SORTKEYという種類があり、ソートキーの指定順や、WHERE句の指定の仕方によってメリットデメリットがあるのでそれらも考慮する必要があります。
テーブル設計のベストプラクティス
- Redshiftはソートキーに応じたデータをディスクに格納する
- 最新のデータが最も頻繁にクエリ処理される場合、タイムスタンプ列をそーとキーの主要な列として指定する
- 1 つの列に対して範囲フィルタリングまたは等価性フィルタリングを頻繁に実行する場合は、その列をソートキーとして指定する
- テーブルを頻繁に結合する場合は、結合列をソートキーと分散キーの両方として指定します。
- 最適な分散スタイルの洗濯
- クエリを実行する前にデータを適切な場所に配置することで、再分散ステップの影響を最小限に抑える
- 1.ファクトテーブルと 1 つのディメンションテーブルをそれらの共通の列に基づいて分散させる
- 2.フィルタリングされたデータセットのサイズに基づいて最大ディメンションを洗濯する
- 3.フィルタリングされた結果セットで高い濃度の行を選択する
- 4.ALL 分散を使用するように一部のディメンションテーブルを変更する
- COPYによる圧縮エンコードの選択
- テーブルを作成するときに圧縮エンコードを指定できますが、ほとんどの場合、自動圧縮が最も適切な結果になる
制約の定義 - アプリケーションが制約を適用しない場合は、プライマリキーおよび外部キーの制約を定義しないでください。Amazon Redshift は、一意性、プライマリキー、および外部キーの制約を強要することはありません。
最小列サイズの使用 - 列の最大サイズを使わない
- テーブルを作成するときに圧縮エンコードを指定できますが、ほとんどの場合、自動圧縮が最も適切な結果になる
- 複雑なクエリの処理中に、一時テーブルに中間クエリ結果を格納しなければならない場合があります。一時テーブルは圧縮されないので、不必要に大きな列がメモリおよび一時ディスク領域を過剰に消費して、クエリパフォーマンスに影響を与える可能性があります。
日付での日時データ型の使用- Redshift は、DATE および TIMESTAMP データを CHAR または VARCHAR よりも効率的に格納するので、クエリパフォーマンスが向上する
ユースケース
バッドパターン
・OLTP - OLTPデータベースを使用する
・非構造化データ - NoSQLを使用する
・小規模なデータセット - 数百GB未満で実現不可
・バイナリデータ - 画像、ビデオ、音楽
・多くの変換が必要 - EMRを実行し、結果をRedshiftにロードする
グッドパターン
・データを複数のファイルに分割する
・GZIPまたはLZOPを使用してファイルを圧縮する
・COPYコマンドを使用して、S3、DynamoDB、EMRiftから大きなデータセットをロードする
・WHERE文の中で最も使用されている列は、特にソートキーの範囲です
・JOIN、GROUP BY、配布キーとしての最大カーディナリティで最も使用されている列
・長い実行クエリの方が大きいノードが大きい方が良い
例:より少ないdc1.8より大きい
・短い実行クエリの方が多くのノードが優れています
例:より多くのdc1.largeより少ないdc1.8xlargeより少ない
WLM
WLMはクエリーをキューに挿入し、実行の順序を管理します
3つのデフォルトキューがある
・スーパーユーザー:1つの並行クエリ(Linuxでのrootログインのようなもの)
・ワーカー:5つの平行クエリ
・プロセッシング:バックグランドプロセス
運用
バックアップ
S3への自動バックアップをとる
スナップショットは別リージョンにレプリケートできる
暗号化
・RedshiftへのSSLの接続が可能
・S3からロードのデータも暗号化可能
・保存時の暗号化(S3はSSE-S3、RedshiftはHSMとCloudHSM)
スケーリング
・ノードの追加、削除と、ノードタイプの変更も可能
・シングルノードとマルチノードも変更できる
・古いクラスタに設定されたデータは、サイズ変更されたクラスタに収まる必要があります
・新しいクラスタは新しい設定から起動する
耐障害性
・S3スナップショットを使用して新しいAZでRedshiftを復元できます
・ドライブ障害 - わずかな性能低下
・ノード障害 - 自動ノード回復が完了するまでアクセスしない