Apache SolrをベースとしたOSS検索システムFessで、ファイルをクローリングし全文検索を行えるまでの必要最低限の手順を以下に記述します
「ファイルサーバがゴミゴミして何がどこにあるかわからない・・・」なんて時に参考にして、この手軽さを体感してみてください
ダウンロード
以下のURLにアクセスしてfess-serverの最新版(現時点ではfess-server-9.3.1.zip)をダウンロードしてください
起動
ダウンロード、解凍したフォルダの配下の./bin/startup.sh(Windowsの場合はstartup.bat)を実行してください
これでWebサーバが立ち上がりFessの操作ができるようになります
なお停止したい場合はshutdown.shを実行すれば停止します
クローラ設定
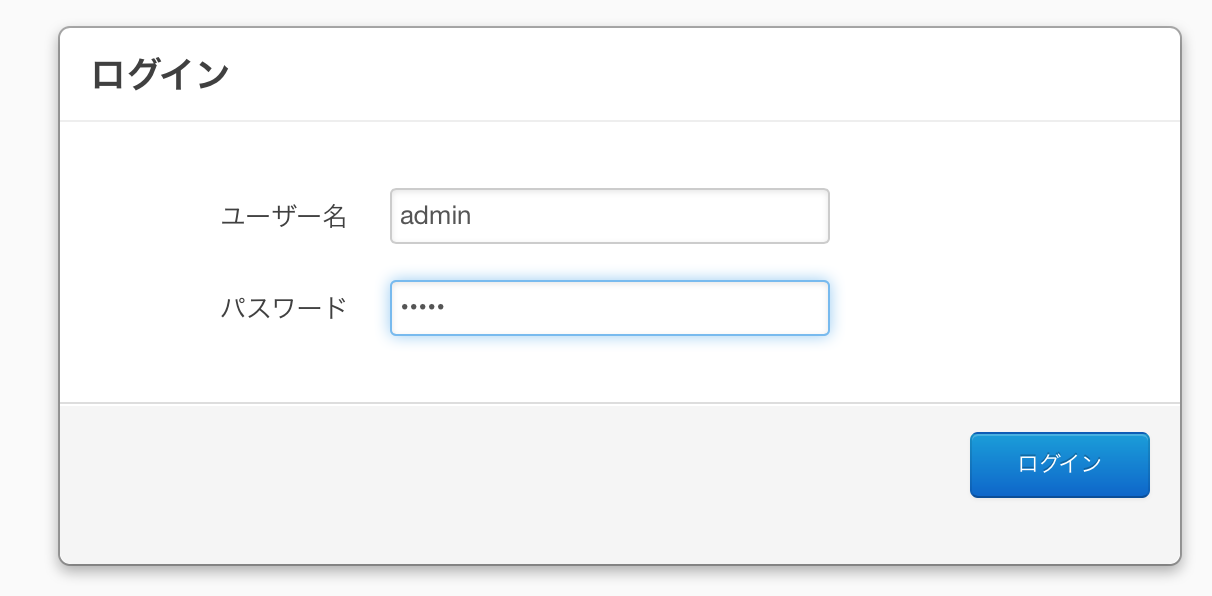
まず http://localhost:8080/fess/admin にアクセスして管理画面にログインしてください
User/Passはadmin/adminです
ログイン後はクロール対象のファイルサーバを指定します
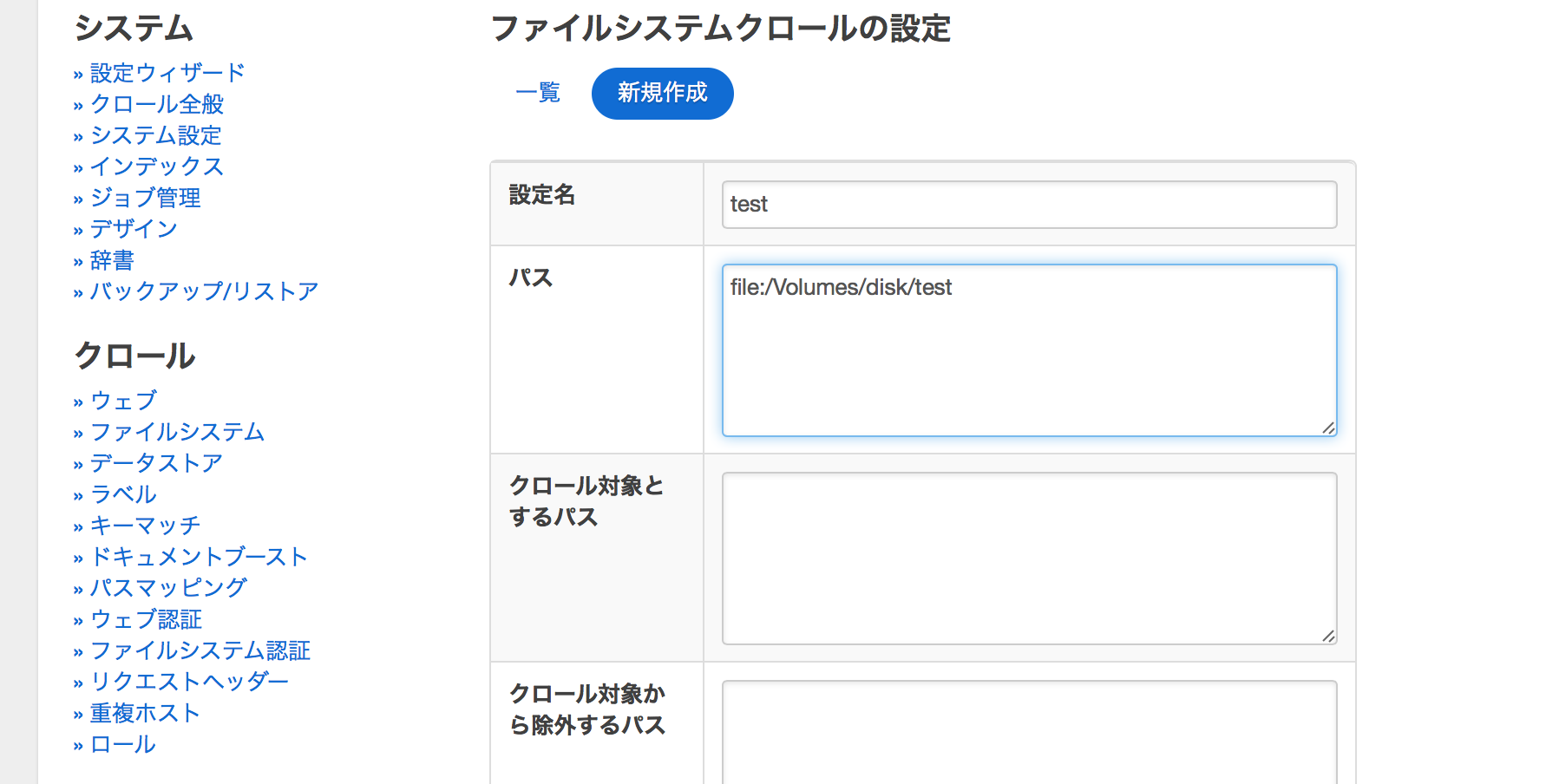
左メニューの「ファイルシステム」→「新規作成」を選択すると入力画面が出るので以下の通り入力し、画面下部の「作成」ボタンを押下してください
設定名: (任意)
パス: file:(フルパス)
※Windowsの場合、ディレクトリのデリミタを「¥」から「/」に置換してください
設定自体は以上で終了ですが、設定後はすぐにクローラを動かしたいかと思います
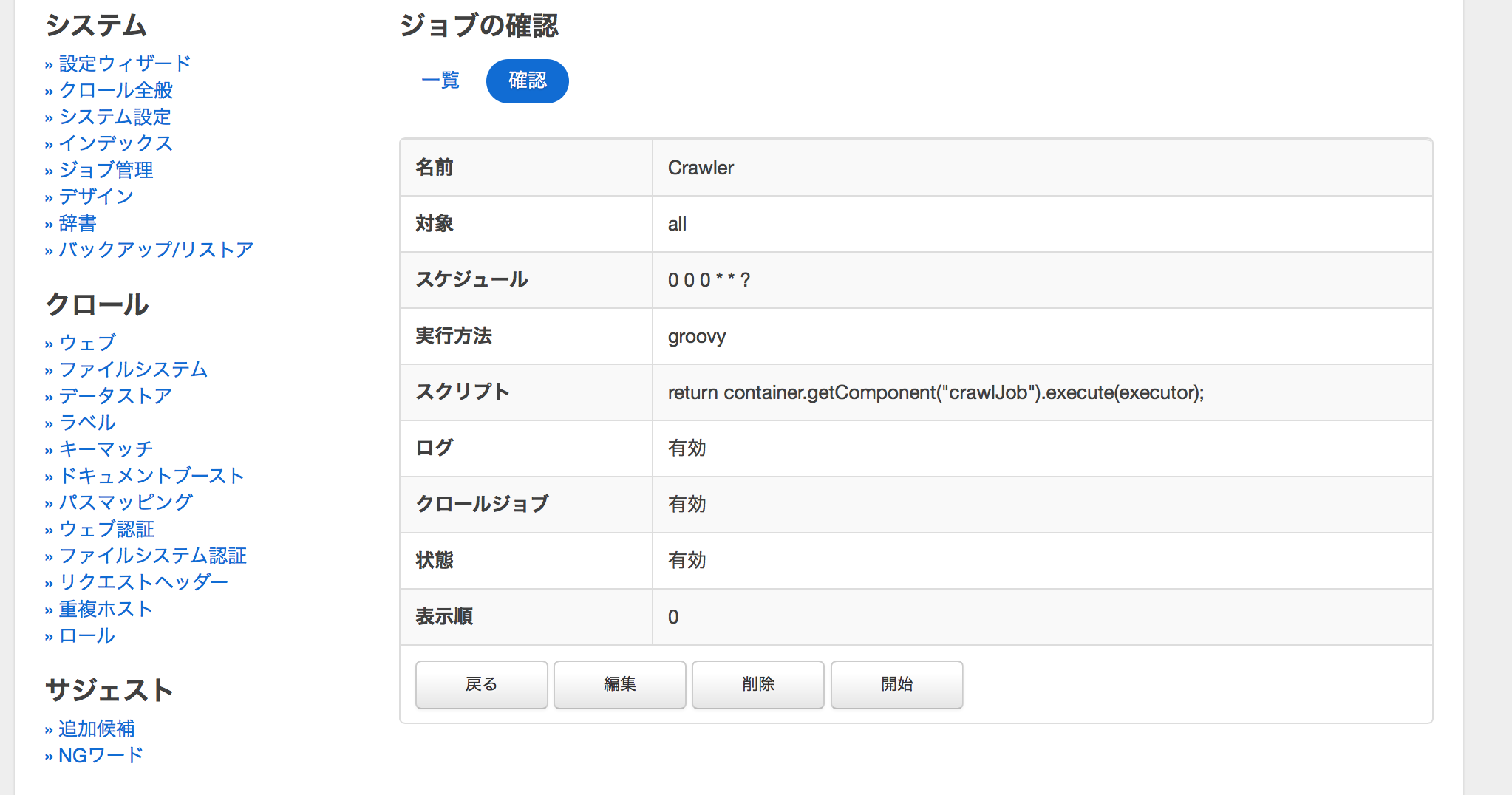
その場合は左メニューの「クロール全般」を選択、一覧内の「Crawler」の詳細ボタンを押下すると下記画面が表示されるので、ここの「開始」ボタンを押下してください
クローラが完了するまでの時間はファイルサーバや通信状態にもよります
大きなファイルサーバだと1日掛かりなんてこともあるので気長に待ってください
なお実行状態は左メニューの「セッション情報」から確認できます
もし2,3日経っても終わらない場合はクローラがスタックしている可能性もあるので再実行や原因追求することをおすすめします(意外と再実行するだけで動くこともありますので・・・)
検索
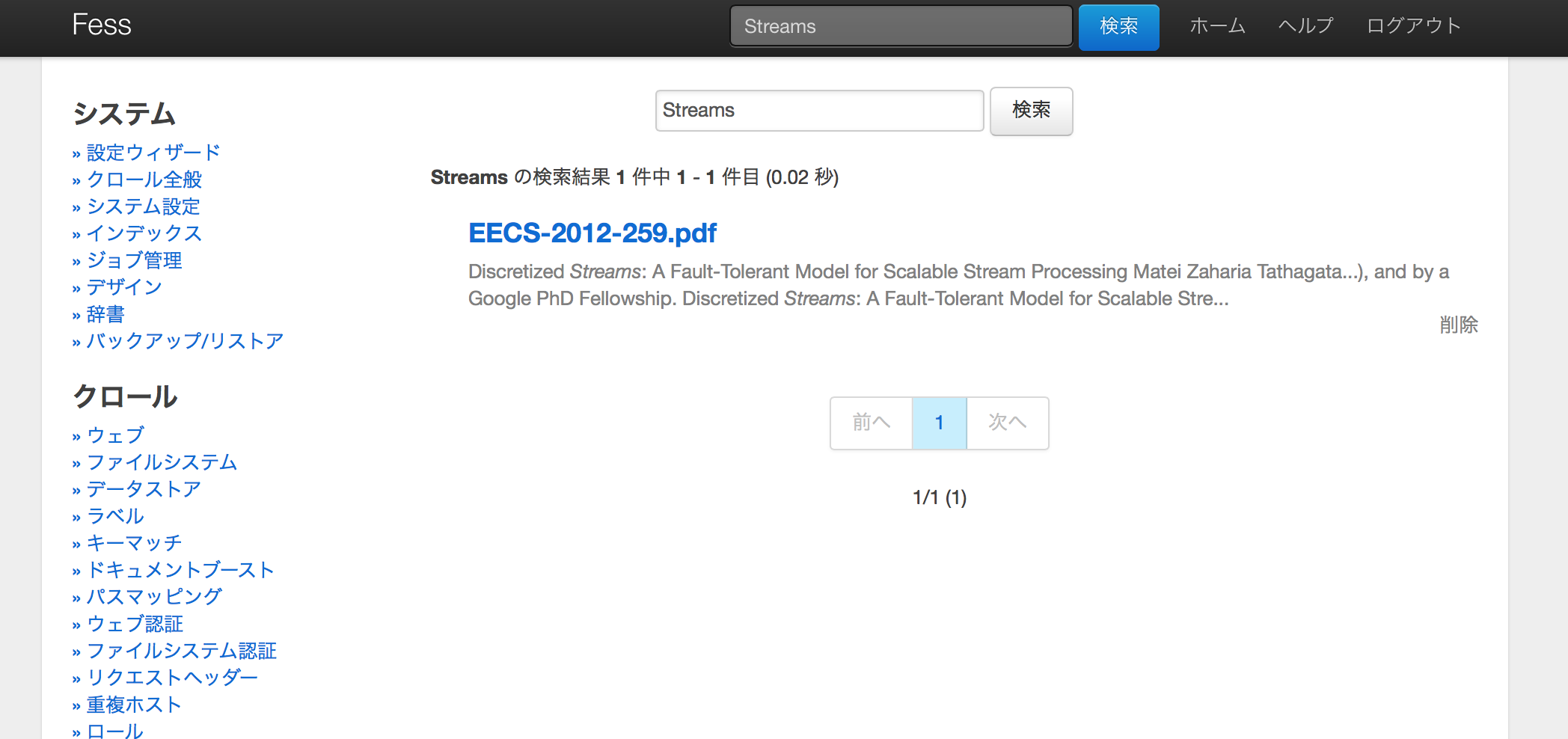
クローラが完了すると全文検索が利用可能になっています
ここではSparkの論文(PDF)を検索し、それがHITすることが確認できています
たった以上の手順で全文検索が簡単に導入できます
もちろんエンタープライズで運用するにはもっと詳細な設定や運用が必要です
しかしこれだけ簡単な手順で導入できるので「全文検索エンジンって使えるのかな?」「とりあえず簡易ツールとして入れてみたい」なんて思ってみたらまずは入れてみることをお勧めします