はじめに
人が音楽を聴くと、ここがサビだな、とか、ここから雰囲気変わったなとかを感じ取れるかと思います。それを機械的にできないかと思いやってみました。
ただし、サビの部分を特定することまではできず、あくまで構成をざっくりつかむ(こことここは雰囲気が変わってる)ところまでをやってみました。結構無理やり感があるように思います。
なお、音楽処理、機械学習について初学者ですので、間違いありましたら、ご指摘いただけると嬉しいです!
使用した曲
RADWIMPSの前前前世 [original ver.] のmp3ファイルを利用しました。
また、楽曲の構成は下記のページを参考にしました。
RADWIMPS「前前前世」のコード進行解説と、楽曲の感想 ※11/24 オリジナル版も追記
ざっくり秒数と構成は下記かと思います。
開始時間 構成
0 イントロ
20 Aメロ
45 Bメロ
67 サビ
93 間奏
103 Aメロ
127 Bメロ
150 サビ
175 間奏
225 サビ
250 アウトロ
上記それぞれが別のクラスタとして認識でき、また同じ構成(Aメロ同士、サビ同士)はそれぞれ同じクラスタとして認識できるといいなと思いました。
使用するライブラリの一部
音楽分析のライブラリとしてlibrosaを用います。
またscikit-learnを用いてクラスタリングを行います。
コード
スペクトログラムの表示
mp3ファイルを読み込み、どのような周波数の音がどれくらいの強さでているかを時系列で見る「スペクトログラム」を作成します。これを見るだけでも、ここで雰囲気が変わってそう、ということはわかるかと思います。
スペクトログラムを作成するにあたり、mp3ファイルに対し、フーリエ変換という処理を行います。これによって、ある時間における、各周波数ごとの強さのリストが手に入るため、後ほどクラスタリングします。
import librosa
import matplotlib.pyplot as plt
import matplotlib.colors as clrs
import numpy as np
import math
from sklearn import cluster
import pandas as pd
import seaborn as sns
import IPython.display
import datetime
%matplotlib inline
# mp3の読み込み
music,fs = librosa.audio.load('zenzenzense.mp3')
# 後ほど用いる関数
def labels_list_to_df(labels_list):
labels_01_list = []
for i in range(len(labels_list)):
labels_01_list.append(np.bincount([labels_list[i]]))
return pd.DataFrame(labels_01_list)
def df_to_df_list(df):
df_list =[]
for i in range(len(df.columns)):
df_list.append(df[i])
return df_list
def pick_colors(df):
return list(clrs.cnames.values())[:len(df.columns)]
def show_stackplot(index_df,df_list,colors):
fig, ax = plt.subplots(1, 1, figsize=(15,5))
fig.patch.set_facecolor('white')
ax.stackplot(index_df.index,df_list,colors=colors)
plt.xticks([i*10 for i in range(int(round(index_df.index.tolist()[-1]))//10 + 1)])
plt.show()
# フーリエ変換の初期設定(調整必要)
n_fft = 2048 # データの取得幅
hop_length = n_fft // 4 # 次の取得までの幅
# 短時間フーリエ変換
D =librosa.stft(music,n_fft=n_fft,hop_length=hop_length,win_length=None)
# 結果をスペクトログラムで表示
librosa.display.specshow(librosa.logamplitude(np.abs(D)**2,ref_power=np.max),
y_axis='log',x_axis='time',hop_length=hop_length)
plt.title('Power spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout
すると下記のグラフを得ることができます。
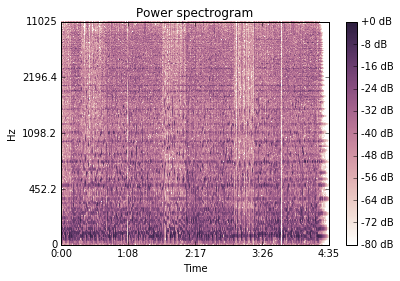
横軸が時間帯になってます。縦軸に大量の線が引かれているようなグラフになります。
クラスタリングする
フーリエ変換で得たリストを元に、クラスタリングを行います。
そうすれば、ギターの音が引かれたタイミング、ボーカルが歌っていたタイミング、をそれぞれクラスタにできるはず。。
とはいえ、ギター、ベース、ドラム、ボーカルはそれぞれ鳴ったり消えたりと、音楽中目まぐるしく変化しているので、ある程度の時間帯における各クラスタの数を見えるようにします。
# クラスタ分類の数(調整必要)
n_clusters=20
# k_meansのラベルをいくつずつ見ていくか(調整必要)
hop = 50
# クラスタ分類(k_means)
logamp = librosa.logamplitude(np.abs(D)**2,ref_power=np.max)
k_means = cluster.KMeans(n_clusters=n_clusters)
k_means.fit(logamp.T)
col = k_means.labels_.shape[0]
# グラフ作成
count_list = []
# ラベル付けたデータをhop分持ってきて数を数える。
for i in range(col//hop):
x = k_means.labels_[i*hop:(i+1)*hop]
count = np.bincount(x)
count_list.append(count)
# index内容
index = [(len(music)/fs)/len(count_list)*x for x in range(len(count_list))] # 秒数
df = pd.DataFrame(count_list,index = index).fillna(0)
columns = [chr(i) for i in range(65,65+26)][:10]
df_list = df_to_df_list(df)
colors = pick_colors(df)
show_stackplot(df,df_list,colors)
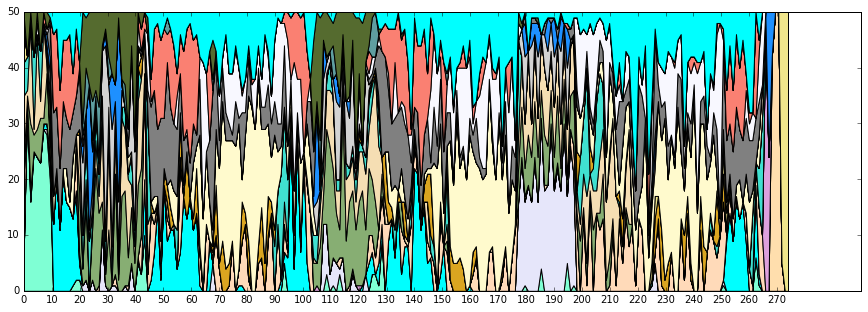
なんとなく、
- 20秒からと105秒からあたりが同じような組み合わせになってそう
- 65秒からと150秒からあたりが同じような組み合わせになってそう
といったことが見て取れるかと思います。
再度、クラスタリングする
クラスタの組み合わせでもって、再度クラスタリングします。
# クラス多数(調整必要)
music_cluster_num = 4
k_means_music = cluster.KMeans(n_clusters=music_cluster_num)
k_means_music.fit(df)
df['cluster'] = k_means_music.labels_
df4 = labels_list_to_df(k_means_music.labels_)
df4_list = df_to_df_list(df4)
colors = pick_colors(df4)
show_stackplot(df,df4_list,colors)
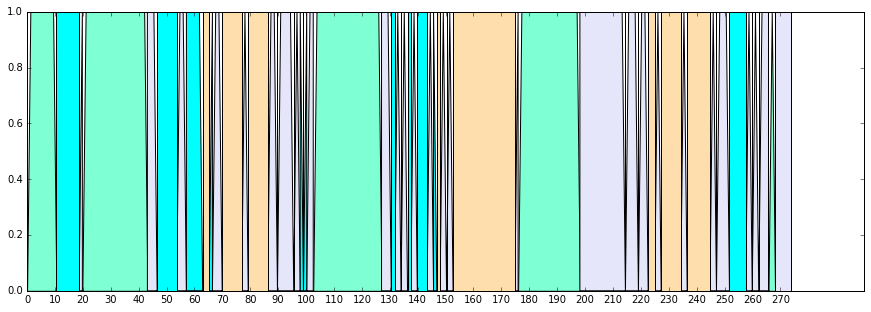
時間の短いクラスタについては、その前のクラスタに合わせてしまいます。
短いクラスタをその前のものにくっつけてしまう。
# いくつ未満をくっつけるか(調整必要)
min_num = 5
comp_list = []
m=1
for i in range(len(k_means_music.labels_) - 1):
if k_means_music.labels_[i] == k_means_music.labels_[i+1]:
m = m + 1
else:
comp_list.append([k_means_music.labels_[i],m])
m=1
# 最後の文字をリストにくっつける。
comp_list.append([k_means_music.labels_[-1],m])
# comp_listの長さが短いものは、前のクラスタと同じIDにする。
for i in range(1,min_num):
replace_comp_list = []
replace_comp_list.append(comp_list[0])
for j in range(1,len(comp_list)):
if comp_list[j][1] == i:
replace_comp_list[-1][1] += i
else:
replace_comp_list.append(comp_list[j])
# 同じクラスタが並んでる場合はくっつける
k = 0
while k < len(replace_comp_list)-1:
try:
while replace_comp_list[k][0] == replace_comp_list[k+1][0]:
replace_comp_list[k][1] += replace_comp_list[k+1][1]
replace_comp_list.pop(k+1)
except IndexError:
continue
else:
k += 1
comp_list = replace_comp_list
# 元の形式に戻す
thawing_list = []
for i in range(len(replace_comp_list)):
for j in range(replace_comp_list[i][1]):
thawing_list.append(replace_comp_list[i][0])
df5 = labels_list_to_df(thawing_list)
df5_list = df_to_df_list(df5)
colors = pick_colors(df5)
show_stackplot(df,df5_list,colors)
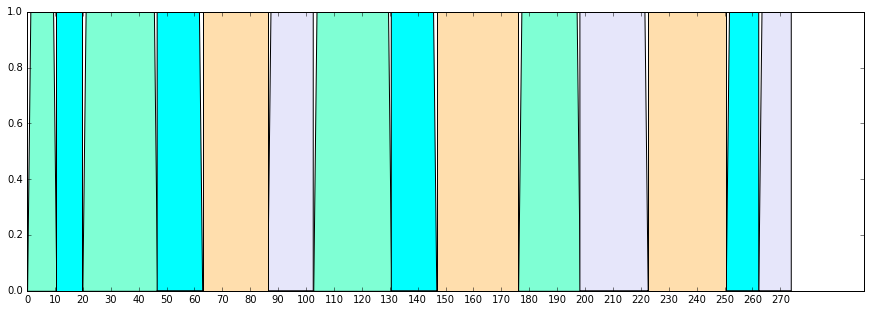
- Aメロの始まる、20秒、103秒以降
- Bメロの始まる、45秒、127秒以降
- サビの始まる、67秒、150秒、225秒以降、
は、数秒のズレはあるものの、一緒になりました。
ざっくりではありますが、構成がつかめるかと思います。
他の楽曲でも試して見る
RADWIMPS スパークル [original ver.]
で同様に試してみました。
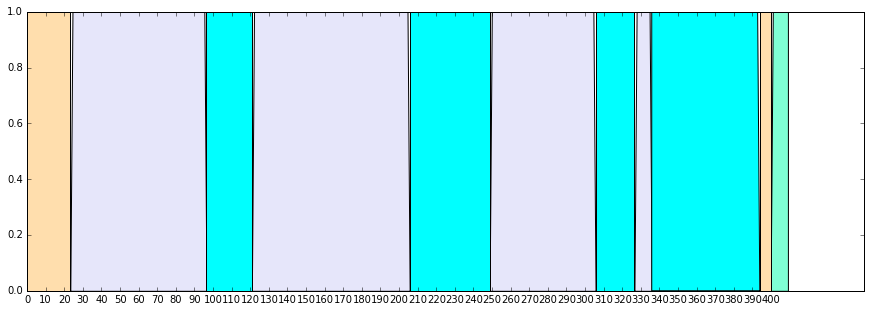
サビが始まるのは、119秒、243秒、321秒辺りで一応別れてはいるものの、Aメロ、Bメロなどは区別できてなさそうで、精度としては前前前世と比べて落ちそうです。
Aメロ、Bメロの雰囲気があまり変わらないことや、楽曲が前前前世と比べて長いこともあり、このような結果になったのかと思います。
終わりに
まだ各パラメータ(クラスタ数、)の調整を行ってないので、それ次第ではもう少し精度は上がると思います。時間のズレも減りそう。
librosaには曲のテンポを調べる機能や、楽器ごとに曲を切り分ける機能などもあります。この辺を活用するのも良さそうです。
違うアーティストの曲も試してみたいと思います。
ありがとうございました。今日(2016/12/31)の紅白や、幕張メッセで行われるカウントダウンジャパンで前前前世聞きましょう。僕は幕張メッセに向かいます。
あわせて行きたい
三葉の声優された上白石さんが初のワンマンライブをするそうです。CDJでは前前前世も披露されました。
上白石萌音 1st ワンマンライブ『Live THEATRE ~chouchou~』