この記事の内容
kaggleのメルカリのコンペ(https://www.kaggle.com/c/mercari-price-suggestion-challenge) にチームで参加した際にシルバーメダルを獲得しました。(ほぼほぼチームの人が優秀すぎたお陰ですが)あまりkaggleの内容って記事化したものが少ないと感じたので、取り組みでどのようなことをしたのかというのを簡潔に記しておこうと思います。
コードはあまり書かず、どのような処理を行なっていたかを重点的に書いていくつもりです。
コンペ概要
ざっくり説明すると商品の情報から価格(出品価格)を予測する、という内容です。予測出品価格と正解データ(実際の出品価格)の誤差を最も小さくした者勝ちとなります。
データセットが持つ商品の詳細は以下の通りです。
-
"name" :商品の名前です。「MLB Cincinnati Reds T Shirt Size XL」など
-
"item_condition_id":「新品、未使用」「目立った傷や汚れなし」などの商品状態がラベル化されています。1,2,3,,など
-
"category_name":商品のカテゴリです。サブカテゴリが/で区切られています。「Men/Tops/T-shirts」など
-
"brand_name":ブランド名です。ノーブランド品もしくはユーザーが選択しなかった場合は欠損値となります。
-
"shipping":送料込み(出品者負担)か着払いかがラベル化されたデータが入ってます。0か1です。
また、このコンペはルールがあり、
1. データセット読み込みから予測データ作成までを全てkaggleのカーネル上で行わなければならない。
2. 1を1時間以内に行わなければならない。
3. (基本)外部データを使ってはならない。
これにより、ただ予測精度を重視するだけでなく省メモリ、高速での計算が求められます。現実的には精度を出すための何層もの予測モデルのスタッキングが出来ない、となります。
外部データも使えないので、よくkaggleでやられてる他の人の予測データを入手して重みづけして提出なども出来なくなっています。
アウトプットとして「実際の現場で使える」予測モデルを求めているのでしょうかね。ここはちょっと未知なところですが、何層もスタッキングしたものって実際現場で使えるのか?と言われると疑問ですよね。
データ探索
こちらはメルカリのkernelで色々書かれているので見てみてください。
https://www.kaggle.com/c/mercari-price-suggestion-challenge/kernels
前処理
一番重要なのは、前処理でした。他のコンペは違うケースもあると思いますが、メダルをとるくらいのレベルになってくると予測モデルそのものより前処理をどれだけこなせるかが順位に響いてくると思います。
実際に行なった前処理は色々ありますので、何点かピックアップして書こうかと思います。
”price”の処理
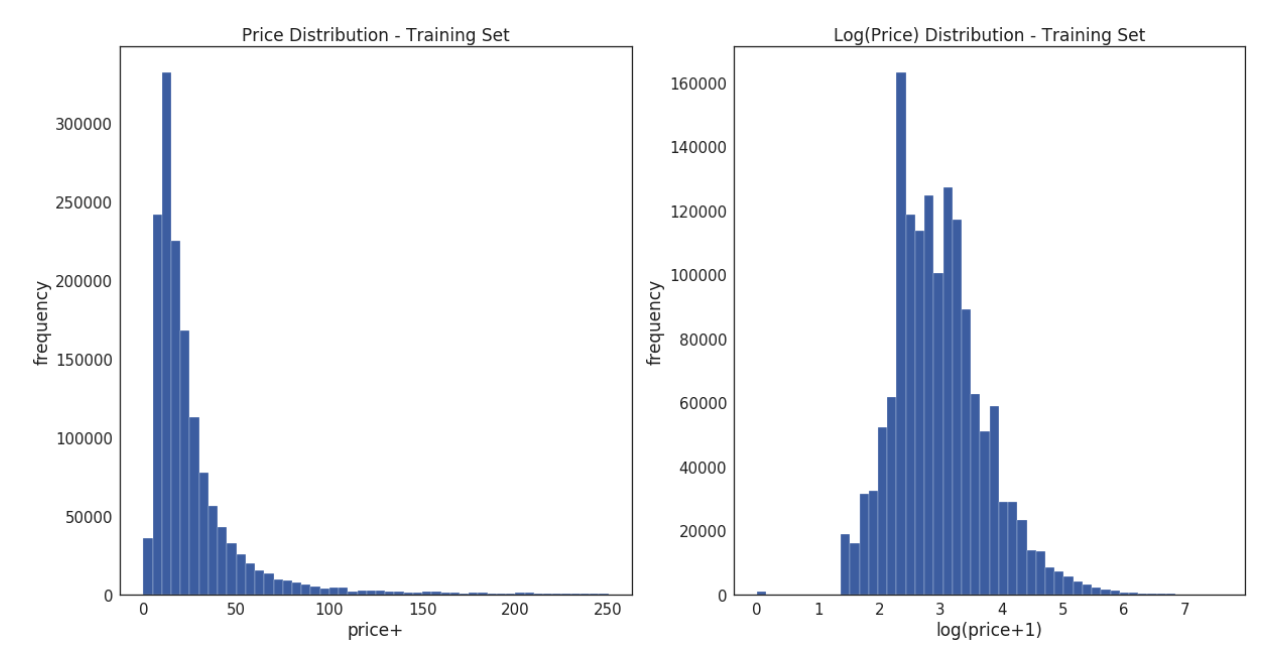
学習データのpriceの分布を以下の左図に載せます。こちらをみますと分布が若干左寄りの分布になっていることがわかると思います。※一般的に年収の分布や商品の購入価格の分布はこのようになることが多い気がします。
基本的に線形回帰などの予測モデルはデータが正規分布であることを仮定しているため、以下のように対数をとり
y_{new} = \log (y_{ori}+1) \
以下の右下に対数をとることで得られた分布を示します。
得られた数値を元に学習を行い、予測モデルを立ててテストデータに対して予測を行います。
最後に得られた予測値(要はテストデータの予測値)を
y_{ori} = e^{y_{new}}-1 \\
によって元どおり変換します。(忘れずに!)
"item_name","item_description"の処理
TweerTokenizerの活用
基本的に英語は単語が空白で区切られているのでテキスト解析はしやすいのですが、例えば「----- brand!」のような文章があった場合「brand」と「!」を分離出来ません。
TweerTokenizerを使うことによりこの問題を解消できます。
(以下サンプルコード)
tknzr = TweetTokenizer(strip_handles=True, reduce_len=True)
s1 = '@remy: This is waaaaayyyy too much for you!!!!!!'
tknzr.tokenize(s1)
→[':', 'This', 'is', 'waaayyy', 'too', 'much', 'for', 'you', '!', '!', '!']
以上のような処理を行います。こちらを使うことにより、単語をより正確に分離することができます。
TF-IDF
これらに関しては基本的にTF-IDFを使いベクトル化するのが良いと思います。(良いと思いますと書いたのは、実際コンペで使ったのは色々な理由で違うからです。後ほど説明します)
TF-IDFは
1.「文章にたくさん出てくる単語ほど重要」
2.「いくつもの文書で横断的に使われている単語はそれほど重要ではない」
ということを表す値をそれぞれかけたもので重みづけする方法です。
sklearnのライブラリにあります。
しかしデータセットにある単語を全てベクトル化してしまうと計算量が上がり、かつ結果的に精度も上がらないので、こちらはTF-IDFの引数max_featuresで数を入れることで、tfidfの値が大きい順から指定数だけベクトル化することが出来ます。
max_featuresに入れる数ですが、こちらは実際に数を入れてみて提出(submission)し、どの数が良いのか判断するしました。
実際にはTF-IDFではなくhash trickを使いました。こちらもsklearnにライブラリがあります。こちらを使った理由は、計算時間です。TF-IDFの方が精度が出るのは確認したのですが、他の処理に時間がかかった為こちらを採用しました。
他の処理を抜かしてこちらをTF-IDFにしたら、、という検証は時間がなかったのでしておりません。
表記揺れの修正
こちらはかなり細かい作業になります。"item_name","item_description"は人が書いた文章なので、様々な書き方がなされています。
単純な例だと「I will」 と 「I'll」で、こちらは同じ意味ですよね。ただ、表記が違うと別の単語としてベクトル化されてしまう為、変換が必要となります。
例えば以下のような変換を行います。
text = re.sub("\'ve", " have ", text, flags=re.IGNORECASE)
text = re.sub("n't", " not ", text, flags=re.IGNORECASE)
text = re.sub("i'm", "i am", text, flags=re.IGNORECASE)
text = re.sub("\'re", " are ", text, flags=re.IGNORECASE)
text = re.sub("\'d", " would ", text, flags=re.IGNORECASE)
text = re.sub("\'ll", " will ", text, flags=re.IGNORECASE)
text = re.sub("\'s", "", text, flags=re.IGNORECASE)
また以下のように、ラフ(?)に書かれたものなどがあるのでこのようなものも変換しました。
text = re.sub('\$', " dollar ", text, flags=re.IGNORECASE)
text = text.replace('karat', ' carat ')
これらは実際にデータセットの内容をみて、変換を判断する必要があるかと思います。
to be continued..