はじめに
この記事ではPythonのpandasを使ってデータの複雑な計算を少ないコード量で処理する方法をご紹介します。特にpandasのapplyをうまく使う方法について紹介します。
pandasのapplyの基本的な使い方については以下のドキュメントをご覧ください。
記事の概要
本記事では以下の内容についてサンプルコードを交えて解説します。
- Pandasのデータフレーム
groupbyとapplyの併用 - PandasのデータフレームにPython辞書(
dict)のgetメソッドの使用 - Pandasのデータフレームに
applyで独自定義した関数を使用
上記の内容を、簡単なクラスター分析をするという例に沿って解説します。
このクラスター分析のステップは以下の通りとします。
- データポイントとクラスタラベルのダミーデータの準備
- クラスタ重心を計算
- クラスタ領域を定義
- クラスタが未知のデータポイントに対してクラスタを定義
本題
まず、データポイントとクラスタラベルのダミーデータの準備をします。
各データポイントごとにx, y座標と属するクラスタラベルが定義されています。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# クラスタのデータポイントのデータフレームの作成
data_cluster = pd.DataFrame({
"x": [1.5, 2.5, 3.0, 2.0, 4.5, 7.5, 9.0, 6.0, 8.0, 7.0],
"y": [2.5, 3.5, 3.0, 2.5, 4.0, 6.5, 8.5, 7.0, 6.0, 5.5],
"labels_cluster": ["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]
})
scatter_plot = sns.scatterplot(data=data_cluster, x='x', y='y', hue='labels_cluster', palette='Set1', s=100)
データポイントを図にすると以下のようになります。
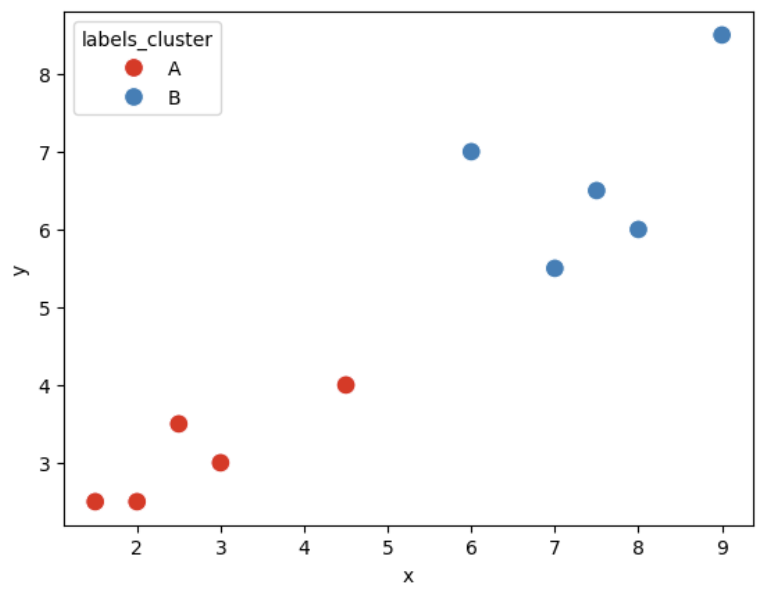
Pandasのデータフレームgroupbyとapplyの併用
続いて、クラスタごとの重心座標を計算します。重心を計算するにはクラスタに属するデータポイントのx,y座標の平均を計算します。
pandasのgroupbyとapplyを併用することで、以下のように1行で全てのデータポイントについて計算することができます。
# データポイントのx,y座標から、クラスタの重心のx,y座標を計算、labels_clusterをキーに重心のx,y座標のマップを作成
map_center_cluster = data_cluster.groupby("labels_cluster").apply(lambda g: (g["x"].mean(), g["y"].mean())).to_dict()
map_center_cluster
ここで、g["x"]はグループ内の x 列のデータを含む Series として扱われます。よって、mean()により平均値を計算することができます。
(g["x"].mean(), g["y"].mean())は重心のx座標とy座標を含むタプルとしています。
後に扱いやすいようto_dictで辞書化しています。
出力結果(クラスタごとの重心座標)は以下になります。
# 出力結果(クラスタごとの重心座標)
{'A': (2.7, 3.1), 'B': (7.5, 6.7)}
PandasのデータフレームにPython辞書(dict)のgetメソッドの使用
上記のマッピングを使って、各データポイントの重心座標を列として加えます。
その際は以下のように書きます。
# マッピングを
data_cluster["center_coordinates_cluster"] = data_cluster["labels_cluster"].apply(lambda c: map_center_cluster.get(c))
display(data_cluster)
上記のcには各データポイントのlabels_cluster列の値が渡されるため、map_center_clusterの値がgetメソッドにより取得できます。
| x | y | labels_cluster | center_coordinates_cluster | distance_from_center | |
|---|---|---|---|---|---|
| 0 | 1.5 | 2.5 | A | (2.7, 3.1) | 1.34164 |
| 1 | 2.5 | 3.5 | A | (2.7, 3.1) | 0.447214 |
| 2 | 3 | 3 | A | (2.7, 3.1) | 0.316228 |
| 3 | 2 | 2.5 | A | (2.7, 3.1) | 0.921954 |
| 4 | 4.5 | 4 | A | (2.7, 3.1) | 2.01246 |
| 5 | 7.5 | 6.5 | B | (7.5, 6.7) | 0.2 |
| 6 | 9 | 8.5 | B | (7.5, 6.7) | 2.34307 |
| 7 | 6 | 7 | B | (7.5, 6.7) | 1.52971 |
| 8 | 8 | 6 | B | (7.5, 6.7) | 0.860233 |
| 9 | 7 | 5.5 | B | (7.5, 6.7) | 1.3 |
Pandasのデータフレームにapplyで独自定義した関数を使用
続いてデータポイントのx,y座標とクラスタの重心のx,y座標から、データポイントとクラスタの距離を計算します。
以下のように距離を計算する関数を定義しておきapplyを使うことにより計算できます。
# データポイントのx,y座標とクラスタ重心のx,y座標から、データポイントとクラスタ重心の距離を計算する
def calc_distance_from_center(row):
return np.sqrt((row["x"] - row["center_coordinates_cluster"][0])**2 + (row["y"] - row["center_coordinates_cluster"][1])**2)
data_cluster["distance_from_center"] = data_cluster.apply(lambda row: calc_distance_from_center(row), axis=1)
display(data_cluster)
applyとlambdaを使うことで、関数の中で(もしくは外でも)row["x"]のように書くことでその列のデータを取得できます。
row["center_coordinates_cluster"][0]はタプルの1番目のデータ、即ち重心のx座標を取得しています。
計算された距離は、以下のようにデータフレームの新しい列に格納されます。
| x | y | labels_cluster | center_coordinates_cluster | distance_from_center | |
|---|---|---|---|---|---|
| 0 | 1.5 | 2.5 | A | (2.7, 3.1) | 1.34164 |
| 1 | 2.5 | 3.5 | A | (2.7, 3.1) | 0.447214 |
| 2 | 3 | 3 | A | (2.7, 3.1) | 0.316228 |
| 3 | 2 | 2.5 | A | (2.7, 3.1) | 0.921954 |
| 4 | 4.5 | 4 | A | (2.7, 3.1) | 2.01246 |
| 5 | 7.5 | 6.5 | B | (7.5, 6.7) | 0.2 |
| 6 | 9 | 8.5 | B | (7.5, 6.7) | 2.34307 |
| 7 | 6 | 7 | B | (7.5, 6.7) | 1.52971 |
| 8 | 8 | 6 | B | (7.5, 6.7) | 0.860233 |
| 9 | 7 | 5.5 | B | (7.5, 6.7) | 1.3 |
次に、各クラスタとみなす領域を定義します。
ここでは、クラスタ重心から最も距離のあるデータポイントまでの距離を半径とした円内をその領域とします。クラスタA, Bの重心はそれぞれ (2.7, 3.1)、(7.5, 6.7)となるので、領域は以下の図のようになります。

次に、クラスタが未知なデータポイントに対してどのクラスタに属するかを計算したいとします。
後の計算の準備ため、各クラスタの重心の情報の辞書を作成します。
# labels_clusterごとに重心からの距離が最大となるデータポイントのインデックスを取得
idx = data_cluster.groupby('labels_cluster')['distance_from_center'].idxmax()
# labels_clusterをキーにデータポイントの座標等のマップを作成
map_max_distance = data_cluster.loc[idx].set_index("labels_cluster").to_dict(orient = "index")
map_max_distance
# 出力結果(クラスタごとの重心座標や領域の半径)※xとyは不要です
{'A': {'x': 4.5,
'y': 4.0,
'center_coordinates_cluster': (2.7, 3.1),
'distance_from_center': 2.0124611797498106},
'B': {'x': 9.0,
'y': 8.5,
'center_coordinates_cluster': (7.5, 6.7),
'distance_from_center': 2.3430749027719964}}
次にクラスタが未知なデータポイントを以下に定義します。
data_unknown = pd.DataFrame({
"x": [3.5, 8.7, 2.5, 5.5],
"y": [3.5, 8.3, 2.7, 4.0]}
)
display(data_unknown)
| x | y | |
|---|---|---|
| 0 | 3.5 | 3.5 |
| 1 | 8.7 | 8.3 |
| 2 | 2.5 | 2.7 |
| 3 | 5.5 | 4 |
上記のデータポイントに対して、どのクラスタに属するかを計算します。
これも先ほど同様下のような関数を定義し、applyでデータフレームに対して関数を適用できます。
この関数は、各クラスタ重心とデータポイントとの距離が領域の半径の距離以下であればそのクラスタラベルをリストに加えて出力しています。
# 任意のデータポイントにクラスターラベルを割り振る
def get_cluster_candidates_within_distance(row, map_max_distance):
labels_cluster_candidates = []
for cluster_label, cluster_values in map_max_distance_rows.items():
# クラスタの重心座標を一時変数として定義
cluster_center_x = cluster_values["center_coordinates_cluster"][0]
cluster_center_y = cluster_values["center_coordinates_cluster"][1]
# データポイントとクラスタ重心の距離を計算
distance = np.sqrt((row["x"]-cluster_center_x)**2+(row["y"]-cluster_center_y)**2)
#上記距離が、クラスタ定義の距離より小さければそのクラスタとする
if (cluster_values["distance_from_center"] >= distance):
labels_cluster_candidates.append(cluster_label)
return labels_cluster_candidates
data_unknown["label_cluster_candidates"] = data_unknown.apply(lambda row: get_cluster_candidates_within_distance(row, map_max_distance_rows), axis=1)
display(data_unknown)
関数の中身はfor文やif文を含む複雑な内容でも処理可能です。
計算結果は以下のようにデータフレームの新しい列に格納されます。
| x | y | label_cluster_candidates | |
|---|---|---|---|
| 0 | 3.5 | 3.5 | ['A'] |
| 1 | 8.7 | 8.3 | ['B'] |
| 2 | 2.5 | 2.7 | ['A'] |
| 3 | 5.5 | 4 | [] |
さいごに
本記事ではpandasで複雑な計算を少ないコード量で処理する方法について、サンプルコードを交えながら解説しました!データ分析の際の実装の参考になれば幸いです。