はじめに
画像処理や画像解析・機械学習向けの機能が集約されたオープンソースのライブラリのOpenCVを用い、zoomなどで使えるアプリを制作していこうと思います。私はプログラミングはかなりの初心者なため、拙いプログラムですが、ご了承ください。下の画像がリアルタイムで顔を画像に変えたものになります。このアプリでzoomには無い画像を使うことができます。また、今回使うpythonのモジュールは複数あるため、webサイトで調べて、インストールしてください。このソースコード、exeファイル、ffmpegファイルは(https://github.com/tachc1/swap)

必要モジュール
pip install opencv-python
pip install opencv-contrib-python
pip install numpy
pip install tkinter
pip install Pillow
GUI部分
baseGround = tk.Tk()# メインウィンドウを作成
baseGround.geometry('500x300+400+100')# ウィンドウのサイズを設定
baseGround.title('顔変換ソフト')# 画面タイトル
#ラベル作成
label1 = tk.Label(text='画像位置の横軸を決める(x座標): -100 ~ 100 ※おすすめは-70')
label1.place(x=10, y=110)
label2 = tk.Label(text='画像位置の縦軸を決める(y座標): -100 ~ 100 ※おすすめは-150')
label2.place(x=10, y=140)
label3 = tk.Label(text='画像の横幅を変える ※おすすめは90')
label3.place(x=145, y=170)
label4 = tk.Label(text='画像の縦幅を変える ※おすすめは230')
label4.place(x=140, y=200)
label5 = tk.Label(text='↓通りに実行したらFrameがでます。')
label5.place(x=20, y=270)
label6 = tk.Label(text='OKボタンを押した後、起動に10秒から20秒かかります。Frameはキーボードを押して消してください')
label6.place(x=20, y=270)
# テキストボックス
textBox1 = tk.Entry()
textBox1.place(x=340, y=110)
textBox2 = tk.Entry()
textBox2.place(x=340, y=140)
textBox3 = tk.Entry()
textBox3.place(x=340, y=170)
textBox4 = tk.Entry()
textBox4.place(x=340, y=200)
#ボタンがクリックされたら実行
def file_select():
global file_path
idir = 'C:\\python_test' #初期フォルダ
filetype = [("写真","*.png"), ("写真","*.jpg"), ("写真","*.jpg"), ("すべて","*")] #拡張子の選択
file_path = filedialog.askopenfilename(filetypes = filetype, initialdir = idir)
input_box.insert(tkinter.END, file_path) #結果を表示
#入力欄の作成
input_box = tkinter.Entry(width=40)
input_box.place(x=120, y=60)
#ラベルの作成
input_label = tkinter.Label(text="顔変換する画像を参照 ※写真を入れているフォルダは英字にしてください")
input_label.place(x=70, y=10)
input_label = tkinter.Label(text="画像は変換ソフトなどを調べて、おすすめの横幅197×縦幅276にしてください")
input_label.place(x=70, y=30)
#参照ボタンの作成
button = tkinter.Button(text=" 参照 ",command=file_select)
button.place(x=380, y=55)
# ボタンの作成と配置
button = tk.Button(baseGround,
text = ' OK ',
# クリック時にval()関数を呼ぶ
command = val1
).place(x=360, y=240)
baseGround.mainloop()
上記の内容でGUI部分を作成しています。すると以下のようなものが作ることができます。このファイルをswapface.pyとします。
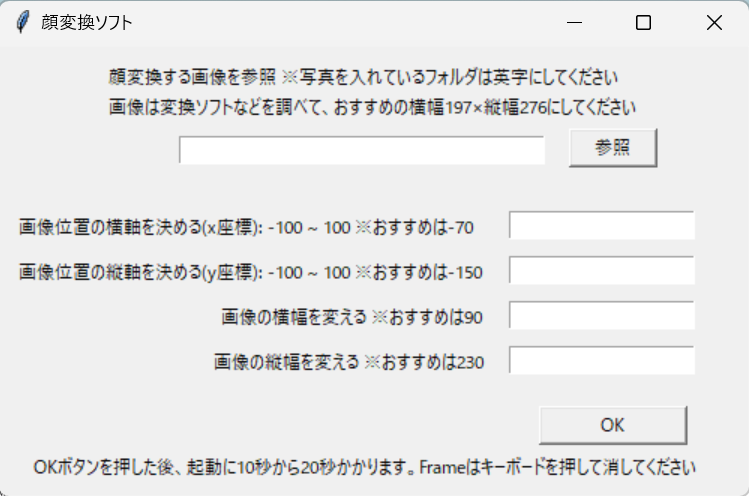
こちらが今回作成したGUI部分になります。
顔を変えるプログラム部分
以下が顔をリアルタイムで画像を取り換える部分とテキストボックスで取得した整数値から画像の位置、サイズを変えるプログラムになります。以下のプログラムをする前にAIに顔を認識してもらう必要があるため、学習済みモデルのカスケード分類機を使います。以下のリンクから手順通り、ダウンロードを行ってください。- (https://opencv.org/releases/) のOpenCVの公式サイトへアクセスする。
- Release直下の最新のOpenCVから「Sources」をクリック
- ダウンロードしたらzipフォルダを解凍し、opencv-4.7.0\data\haarcascadesの順番にフォルダを開いていきます。haarcascadesフォルダ内のhaarcascade_frontalface_alt2.xmlを使うので、swapface.pyと同じ階層にこのファイルを取り込みます。これで顔認識が自動で行えます。
カスケード分類器が取り込めたと思うので、以下に顔を画像に変えるプログラムを書きます。
def val():
global a,b,c,d, e, f
# テキストボックスの値を取得
x1 = (textBox1.get())
y1 = (textBox2.get())
w1 = (textBox3.get())
h1 = (textBox4.get())
a = x1
b = y1
c = w1
d = h1
# カメラの解像度設定
WIDTH = 1920
HEIGHT = 1080
# 読み込みする画像の指定
img = file_path
cv2_img = cv2.imread(img, cv2.IMREAD_UNCHANGED)
#顔認識モデルの指定
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
# 引数でカメラを選べれる。
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, HEIGHT)
def overlayImage(src, overlay, location, size):
overlay_height, overlay_width = overlay.shape[:2]
# webカメラの画像をPIL形式に変換
src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
pil_src = Image.fromarray(src)
pil_src = pil_src.convert('RGBA')
# 合成したい画像をPIL形式に変換
overlay = cv2.cvtColor(overlay, cv2.COLOR_BGRA2RGBA)
pil_overlay = Image.fromarray(overlay)
pil_overlay = pil_overlay.convert('RGBA')
#顏の大きさに合わせてリサイズ
pil_overlay = pil_overlay.resize(size)
# 画像を合成
pil_tmp = Image.new('RGBA', pil_src.size, (255, 255, 255, 0))
pil_tmp.paste(pil_overlay, location, pil_overlay)
result_image = Image.alpha_composite(pil_src, pil_tmp)
# OpenCV形式に変換
return cv2.cvtColor(numpy.asarray(result_image), cv2.COLOR_RGBA2BGRA)
def main():
x1 = 0
y1 = 0
w1 = 0
h1 = 0
# 顔認識の左上角の座標を格納する変数
x = 0
y = 0
# 顔の幅と高さを格納する変数
w = 0
h = 0
while True:
# VideoCaptureから1フレーム読み込む
ret, frame = cap.read()
#フレームをグレー形式に変換し、顔認識
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
face = face_cascade.detectMultiScale(gray, 1.3, 5)
# 顔が認識されていればx, y, w, hを更新
if face != ():
(x, y, w, h) = face[0]
# 変数が初期値以外ならフレームに画像を合成
if w != 0:
frame = overlayImage(frame, cv2_img, (x+int(a), y+int(b)), (w+int(c), h+int(d)))
# 加工したフレームを表示する
cv2.imshow('Frame', frame)
# キー入力を1ms待って、ESCを押されたらBreakする
k = cv2.waitKey(1)
if k != -1:
break
# キャプチャをリリースして、ウィンドウを閉じる
cap.release()
cv2.destroyAllWindows()
cv2.waitKey(1)
if __name__ == '__main__':
main()
cv2.destroyAllWindows()
cv2.waitKey(1)
これにより顔をリアルタイムで画像に変えることができます。
この変数についての説明
# 顔認識の左上角の座標を格納する変数
x = 0
y = 0
# 顔の幅と高さを格納する変数
w = 0
h = 0
変数x,yは初期値は0です。顔を認識すると顔の位置によってx,y座標が決まります。スクリーン座標のxの0は左上で値が増えていくごとに右に動きます。yの0は左上で値が増えると下に動きます。また、顔を認識するとx,y座標が変わるため、画像の位置を調節していくにはマイナスの値を使います。
変数w,hは指定した画像の幅と高さを決めます。width(w)が横幅でheight(h)が縦幅です。
全体のプログラム
from tkinter import PhotoImage, filedialog
import cv2
import numpy
from PIL import Image
import tkinter
import tkinter as tk
a = 0
b = 0
c = 0
d = 0
baseGround = tk.Tk()# メインウィンドウを作成
baseGround.geometry('500x300+400+100')# ウィンドウのサイズを設定
baseGround.title('顔変換ソフト')# 画面タイトル
label1 = tk.Label(text='画像位置の横軸を決める(x座標): -100 ~ 100 ※おすすめは-70')# ラベル
label1.place(x=10, y=110)
label2 = tk.Label(text='画像位置の縦軸を決める(y座標): -100 ~ 100 ※おすすめは-150')
label2.place(x=10, y=140)
label3 = tk.Label(text='画像の横幅を変える ※おすすめは90')
label3.place(x=145, y=170)
label4 = tk.Label(text='画像の縦幅を変える ※おすすめは230')
label4.place(x=140, y=200)
label5 = tk.Label(text='↓通りに実行したらFrameがでます。')
label5.place(x=20, y=270)
label6 = tk.Label(text='OKボタンを押した後、起動に10秒から20秒かかります。Frameはキーボードを押して消してください')
label6.place(x=20, y=270)
textBox1 = tk.Entry()# テキストボックス
textBox1.place(x=340, y=110)
textBox2 = tk.Entry()
textBox2.place(x=340, y=140)
textBox3 = tk.Entry()
textBox3.place(x=340, y=170)
textBox4 = tk.Entry()
textBox4.place(x=340, y=200)
# キー入力時のコールバック関数を定義
def on_key1(event):
textBox2.focus_set()
# コールバック関数のバインド
textBox1.bind("<Key-Return>", on_key1)
# 以下、entry2用
def on_key2(event):
textBox2.focus_set()
textBox2.bind("<Key-Return>", on_key2)
def on_key3(event):
textBox3.focus_set()
textBox2.bind("<Key-Return>", on_key3)
def on_key4(event):
textBox4.focus_set()
textBox3.bind("<Key-Return>", on_key4)
def clear_text():
input_box.delete(0, tk.END) # テキストボックスの値を削除
def button_clicked():
global file_path
idir = 'C:\\python_test' #初期フォルダ
filetype = [("写真","*.png"), ("写真","*.jpg"), ("写真","*.jpg"), ("すべて","*")] #拡張子の選択
file_path = filedialog.askopenfilename(filetypes = filetype, initialdir = idir, )
input_box.insert(tkinter.END, file_path) #結果を表示
if button_clicked.flag:
clear_text()
input_box.insert(tkinter.END, file_path) #結果を表示
button_clicked.flag = False
button_clicked.flag = not button_clicked.flag
button_clicked.flag = False
#入力欄の作成
input_box = tkinter.Entry(width=40)
input_box.place(x=120, y=60)
#ラベルの作成
input_label = tkinter.Label(text="顔変換する画像を参照 ※写真を入れているフォルダは英字にしてください")
input_label.place(x=70, y=10)
input_label = tkinter.Label(text="画像は変換ソフトなどを調べて、おすすめの横幅197×縦幅276にしてください")
input_label.place(x=70, y=30)
#ボタンの作成
button = tkinter.Button(text=" 参照 ",command=button_clicked)
button.place(x=380, y=55)
def val1():
val()
def val():
global a,b,c,d, e, f
# テキストボックスの値を取得
x1 = (textBox1.get())
y1 = (textBox2.get())
w1 = (textBox3.get())
h1 = (textBox4.get())
a = x1
b = y1
c = w1
d = h1
# カメラの解像度設定
WIDTH = 1920
HEIGHT = 1080
# 読み込みする画像の指定
img = file_path
cv2_img = cv2.imread(img, cv2.IMREAD_UNCHANGED)
#顔認識モデルの指定
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
# 引数でカメラを選べれる。
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, HEIGHT)
def overlayImage(src, overlay, location, size):
overlay_height, overlay_width = overlay.shape[:2]
# webカメラの画像をPIL形式に変換
src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
pil_src = Image.fromarray(src)
pil_src = pil_src.convert('RGBA')
# 合成したい画像をPIL形式に変換
overlay = cv2.cvtColor(overlay, cv2.COLOR_BGRA2RGBA)
pil_overlay = Image.fromarray(overlay)
pil_overlay = pil_overlay.convert('RGBA')
#顏の大きさに合わせてリサイズ
pil_overlay = pil_overlay.resize(size)
# 画像を合成
pil_tmp = Image.new('RGBA', pil_src.size, (255, 255, 255, 0))
pil_tmp.paste(pil_overlay, location, pil_overlay)
result_image = Image.alpha_composite(pil_src, pil_tmp)
# OpenCV形式に変換
return cv2.cvtColor(numpy.asarray(result_image), cv2.COLOR_RGBA2BGRA)
def main():
x1 = 0
y1 = 0
w1 = 0
h1 = 0
# 顔認識の左上角の座標を格納する変数
x = 0
y = 0
# 顔の幅と高さを格納する変数
w = 0
h = 0
while True:
# VideoCaptureから1フレーム読み込む
ret, frame = cap.read()
#フレームをグレー形式に変換し、顔認識
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
face = face_cascade.detectMultiScale(gray, 1.3, 5)
# 顔が認識されていればx, y, w, hを更新
if face != ():
(x, y, w, h) = face[0]
# 変数が初期値以外ならフレームに画像を合成
if w != 0:
frame = overlayImage(frame, cv2_img, (x+int(a), y+int(b)), (w+int(c), h+int(d)))
# 加工したフレームを表示する
cv2.imshow('Frame', frame)
# キー入力を1ms待って、ESCを押されたらBreakする
k = cv2.waitKey(1)
if k != -1:
break
# キャプチャをリリースして、ウィンドウを閉じる
cap.release()
cv2.destroyAllWindows()
cv2.waitKey(1)
if __name__ == '__main__':
main()
cv2.destroyAllWindows()
cv2.waitKey(1)
# ボタンの作成と配置
button = tk.Button(baseGround,
text = ' OK ',
# クリック時にval()関数を呼ぶ
command = val1
).place(x=360, y=240)
baseGround.mainloop()
こちらが全体のプログラムになります。私はこのアプリを使ってzoomに参加して楽しんでます。
終わりに
使用画像はサイズを変える場合にはお勧めの値でまず試してもらった後に、値を調整してください。このアプリの改善点を挙げるとすれば
・テキストボックスの値を入力した後にENTERキーを押すと次のテキストボックスにいくことができるようにする。(解決済)
・ファイルやフォルダ名に日本語があるとエラーが起きないようにする
・Frameが起動するとウィンドウの×ボタンで閉じれるようにする
・EXE化がうまくできておらず、フォルダ内でしか起動しない問題の解消(解決済)