はじめに
参画しているプロジェクトで実行計画が数十億という四皇並みの数値を持つSQLの存在が発覚しました。
重たすぎてタイムアウトしてしまい処理が正常終了できなくなっていたので、すぐにでもチューニングしたかったのですが知識が足りず何もできませんでした(この時は暫定対応としてタイムアウト時間を延長していました)。私の能力的にもプロジェクト的にも危機を感じたので勉強することを決意しました。
設計面と実装面について勉強をしたのでその内容を残します。また、折角なので実装面では実際に勉強で使用したSQLと取得した実行計画を一緒に残します。
(SQLと実行計画は部分的に伏せています。)
では先に個人的な結論から
結論
- とにかくインデックスを使った実装をする
- だからと言ってなんでもインデックスを張るのはNGでインデックス設計の知識が必要
- パーティション分けなどDB設計にも頼る
- ヒットする件数を制御するためにUI実装にも頼る
- インデックスを使わない実装(書き換え等)は上記に比べると重要度は低い
環境
Oracle Database 12c
大前提
実行計画を見よう
設計・実装云々の前に…そもそもではありますが、実行計画を確認しつつSQLを実装しているでしょうか?
少なくとも私が参画するプロジェクトでは、前述のとんでもないSQLが存在する以上確認できていないようでした。
また、実行計画を確認しているその環境には本番環境と同量のデータが存在するでしょうか?
実行計画はデータ量によって大きく変わります。少量のデータでは問題なくとも、データ量が増えるにつれて実行計画が膨れ上がっていくので本番環境と同等のデータ量の環境で検証するのが望ましいです。
後者は環境の問題なので用意するとして、前者は意識の問題なのでSQL実装の規約に盛り込むなどなどをしましょう。
では以降で設計面と実装面に触れていきます。
設計面
インデックス設計
インデックスが効いていると早くなりますが、なんでもかんでもインデックスを張ればいい訳ではありません。設定したほうがよいインデックスと設定しない方がよいインデックスが存在します。
以前自分なりにポイントをまとめてみましたので、こちらを参考にしていただければと思います。
パーティション化
検索対象トランザクションを減らすことは有効な手段です。
とは言いつつもよくわかっていなかったので調べてみました。
何故パーティション化が有効なのかというと、テーブルやインデックスを細かい単位に分割してそれベースでアクセスすることができるからです。また、そのテーブルを利用するアプリケーションからパーティション化しているか否かに関わらず同じように利用することができるためSQLの修正のような副作用はありません。
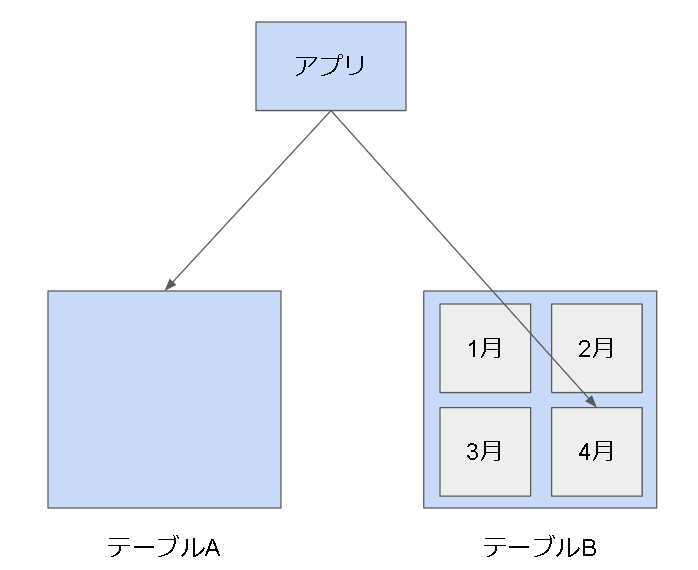
以下はあるアプリケーションが膨大なデータを持つテーブルに対して、4月分のデータのみ要求する例です。テーブルAからデータを取得する場合は、テーブル内データ全件を走査しなければなりません。テーブルBのように月ごとにパーティション化されていたとすると、4月分のパーティションに対してのみアクセスして取得することができます。ただし、このようにアクセスするためにはクエリにパーティションキーを含める必要があります。
パーティション分けとは少し異なりますが、履歴テーブルのようなものを用意して過去分を移行するのも一つの手です。
UI見直し
チューニングからは逸れてしまいますが…例えば、日付を使った検索で範囲を広く指定されることで対象が多くなり、重たくなるケースがあると思います。そのような場合にUI側で一定以上の期間を設定できないように制御をかけるのも一つの手です。
実装面
あるテーブルAを使って検証した結果をSQLと実行計画とともに残します。
また、検証に使用しているカラムはインデックスが張られていないものとします。
インデックスを使う
当然ですがインデックスを使うと驚くほど早くなります。
-- SELECT STATEMENT Cost = 50901
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select *
from テーブルA
where カラム = '~~~'
;
-- SELECT STATEMENT Cost = 3
-- +-TABLE ACCESS BY INDEX ROWID テーブルA テーブルA@SEL$1
-- +-INDEX UNIQUE SCAN テーブルA_PKC テーブルA@SEL$1
select *
from テーブルA
where id = 1
;
しかし、インデックスを使っていると思っていても実は使用されていないケースがあるので注意が必要です。
具体的には以下のようなケースでは使用されません。
● 暗黙の型変換等行っていないか
● 左辺で関数など使用いていないか
● null比較をしていないか etc
in ⇔ exists
以下例では倍の違いが生じました。
-- SELECT STATEMENT Cost = 46463
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select *
from テーブルA a1
where exists (
select 1
from テーブルA a2
where a1.カラム = a2.カラム
)
and a1.カラム = '~~~'
;
-- SELECT STATEMENT Cost = 92927
-- +-HASH JOIN RIGHT SEMI
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$2
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select *
from テーブルA a1
where a1.カラム in (
select カラム
from テーブルA a2
where a2.カラム = '~~~'
)
;
とは言え必ずしもexistsの方が実行計画が低いわけではありません。こちらを参考にさせていただいたところ、以下のような記載をされていました。
● 副問い合わせの選択性が高い場合にはIN
● 親問い合わせの選択性が高く、副問い合わせのコストも低い場合にはEXISTS
要するにin句の中で十分に絞ることができる場合はin句を、親で十分に絞ることができていてexistsの中のコストが低い場合はexistsを使用するのがよいようです。
union ⇔ case
以下のようにunion➡caseと書き換えることで実行計画の改善ができます。
-- SELECT STATEMENT Cost = 50895
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select case
when 作成日付 = '2022/09/20' then '今日'
when 作成日付 = '2022/09/19' then '昨日'
end as 日付
from テーブルA
;
-- SELECT STATEMENT Cost = 101817
-- +-SORT UNIQUE
-- +-UNION-ALL
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$2
select 作成日付
from テーブルA
where 作成日付 = '2022/09/20'
union
select 作成日付
from テーブルA
where 作成日付 = '2022/09/19'
;
しかし必ずしもunionをcaseに書き換えればよいわけではありません。そもそもunionでしか解けない場合はその通りunionを使用することになりますし、unionを使うことでインデックスを利用できる場合にも使用することになります。
union ⇔ union all
抽出されるデータの重複を許す場合やそもそもデータの重複が無い場合はunion allを使いましょう。
-- SELECT STATEMENT Cost = 101551
-- +-SORT UNIQUE
-- +-UNION-ALL
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$2
select カラム
from テーブルA
where created_at > '2022/08/25'
union
select カラム
from テーブルA
where created_at < '2022/08/25'
;
-- SELECT STATEMENT Cost = 92941
-- +-SORT UNIQUE
-- +-UNION-ALL
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$2
select カラム
from テーブルA
where created_at > '2022/08/25'
union all
select カラム
from テーブルA
where created_at < '2022/08/25'
;
必要なカラムだけ取得する
(例では若干ですが)不要なカラムを取得するとその分実行計画が大きくなります。
-- SELECT STATEMENT Cost = 46462
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select カラム
from テーブルA
;
-- SELECT STATEMENT Cost = 46641
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select *
from テーブルA
;
一部をマテビュー化する
リフレッシュが必要になる都合上、必ず利用できる手ではないですが一考の余地はあると思います。マテビューにもインデックスを設定できるので利用するとさらに早くなります。
例えば、条件が複雑でコストが高いSQLがあったとします。
また、このSQLは前月分の計上データを取得するために利用されて、実際には翌月頭実行されるとします。
その場合、翌月頭の夜中にリフレッシュすることで複雑なクエリを流すことなく実行することができます。
(パフォーマンス検証ができなかったの例はありません。)
group by ⇔ distinct
色々調べて、確認をしてみたのですが私の環境上では実行計画のコストで差は生じませんでした。ですが、以下例では実行計画は同じで合ったものの、実行してみるとdistinctは一瞬で取得できましたが、group byは中々時間がかかっていました。
-- SELECT STATEMENT Cost = 10858
-- +-SORT AGGREGATE
-- +-VIEW SYS.VW_DAG_0 VW_DAG_0@SEL$C33C846D
-- +-HASH GROUP BY
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select count(distinct カラム)
from テーブルA
;
-- SELECT STATEMENT Cost = 10858
-- +-HASH GROUP BY
-- +-TABLE ACCESS FULL テーブルA テーブルA@SEL$1
select count(カラム)
from テーブルA
group by カラム
;
サブクエリを減らす
例の数十億の実行計画を持つSQLもサブクエリが大量にありました。SQLによっては難しい対応ですが、その分パフォーマンスへの影響は大きいです。
(思いつかずパフォーマンス検証ができなかったので例はありません。)
おわりに
設計面と実装面に対してそれぞれ勉強してみた感想を書きます。
設計面
やはりインデックス設計は重要だなと思いました。設計自体は容易なものではないですが、対応してしまえば既存のSQLのうちいくつかが早くなるかもしれませんし、新規に実装する際にもインデックスを使用して実装することを第一に考えればよいので、実装面での対応に比べるとコストやハードルが低くなると思いました。
とは言え、やはりある程度の力がないと無法地帯となってしまうので、実装面に関する知識ももちろん必要です。
実装面
インデックス以外の対応でも実行計画の改善は見られましたが、実装者とレビュー者の一人一人にある程度の知識が必要になってきたり、既に稼働しているSQLチューニングでは改修前後で全く同じデータが抽出されることを確認する必要があったり、結構なコストがかかってしまうなと思いました。
また、今回のdistinctとgroup byの例のように実行計画は同じでも実際にかかる時間が違うケースもあり、実行計画を見るだけではなく、チューニングするためには実行して比較してみることも必要なのだと再認識しました。もちろん知識、動作検証共に必要なものではありますが、すぐに身についたりするものではないため、個人的に対応の優先度としては設計面での対応よりは高くないかなと判断しました。
どなたかの参考になりましたら幸いです。
参考
2つの副問い合わせの違い IN 条件か EXISTS 条件か
SQL実践入門──高速でわかりやすいクエリの書き方
パーティション化の概念
実践!パーティションの基本から実装例まで