マルチクラスのセグメンテーション
複数クラスのセグメンテーションを行おうと思って調べてみたが、
多くのモデルが、pixel単位に対して、各クラスの確率を出力し、
そこから、ピクセル毎に、「この位置は、〇〇だ」という形式をとる実装だった。
が、よく考えてみると、
自分たちって画像や風景をみた際に、「おっこの位置は、〇〇。あの位置は、△△」なんて言わなくね?
どっちかって言うと、
「あの辺に〇〇があって、あの後ろには、△△」みたいな、ある種レイヤー的な捉え方しない?
と思い、
pixel単位に対して、各クラスの確率を出力
ではなく、
クラス毎のセグメンテーションマップを出力
って形でできないかとやってみた。
クラス毎のセグメンテーションマップを出力
これの場合、うまくいって、学習データをちゃんと用意できれば、重なり合った領域に対しても、(おそらくこうあるはずという形式になるかもしてないが、)セグメンテーションができるんじゃないだろうかという期待もあった。
UNet系のモデルで、実験
ちょうど実装してみていたUnet, DeepUNetで実験することに。
変更点としては、
マルチクラスセグメンテーション時、最終レイヤーで、channel軸に対してsoftmaxするところを、全体に対してsigmoidをかける様に変更。
また、loss計算は、各チャンネル毎に、dice coefficentを使ったlossを出し、sumする様に変更した。
学習
カラー画像を入力として、同一サイズのクラス数分のchannelを持つベクトルを出力にしようかと思ったが、
今回は、対象物(クラス)を2種に絞ったので、各クラスをそれぞれchannel対応させて、出力もそのままRGBをもつカラー画像(にそのまま変換できるベクトル)にした。
ノート : 青
ペン : 赤
学習データは、
オリジナル : 50枚
を用意し、
data augmentationで、
フリップ(水平 = 1 + 1) * 回転(60度ずつ = 1 + 5) * スケーリング(1.5 = 1 + 1) = 24 倍
に、水増しして
合計 50[枚] * 24[倍] = 1200[枚]
を使用した。(20%(=240枚)をvalidationに回した。)
Epoch数:1000、
Batch:80(UNet), 60(DeepUNet)
で、学習した。
結果
loss曲線は、こんな感じ
UNet:
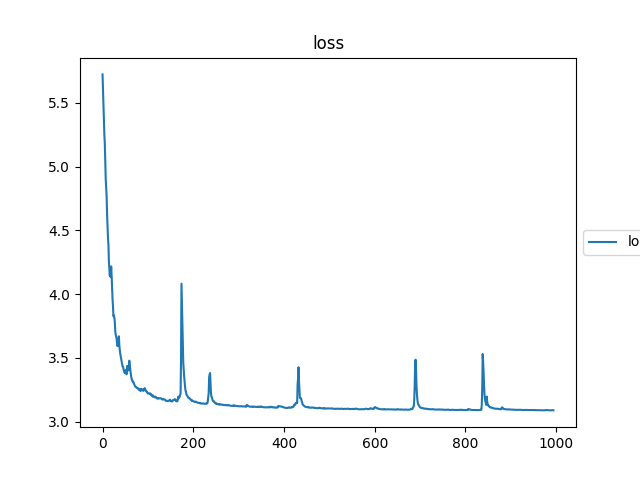
DeepUNet:
(紛失してしまった....)
そして出力結果は、こんな感じ (一部抜粋)


うまくいかない。
今回の場合、未使用channel(緑)があり、このchannelのみ、教師データに1枚もないので、学習できない?
それで、緑の画素が、全体に混ざって入り、こんな感じになった?
理想は、この緑が、なくなること。