Kerasの練習がてらU-net構造のモデルで、画像セグメンテーションをしてみた。
画像セグメンテーションと言っても、物体の位置を白に塗り、それ以外を黒にするという2値のみのものです。
今回の物体は、猫が好きなので、猫にしました。
環境
- Windows10
- GeForce GTX 1080 ti
- Python
- Keras
- CUDA 9.0
Inputs




こんな感じの猫がいる画像(60(学習用)+20(評価用))を準備
サイズは、128*128にした。
ただし、入力時は、GrayScale化し、1Channelにして扱った。
Teachers




こんな感じに、猫がいるところ(猫の範囲)を白にした画像を準備
サイズは、Inputsに同じく128*128。
DVD見ながら自分でアノテーション。
画像処理でうまくエッジが出せなかったので、ペイントツールで、猫の外枠を明らかに違う色で描いてから、エッジ抽出処理して、内側を白に変更した。
2値化して、1Channelで扱う。
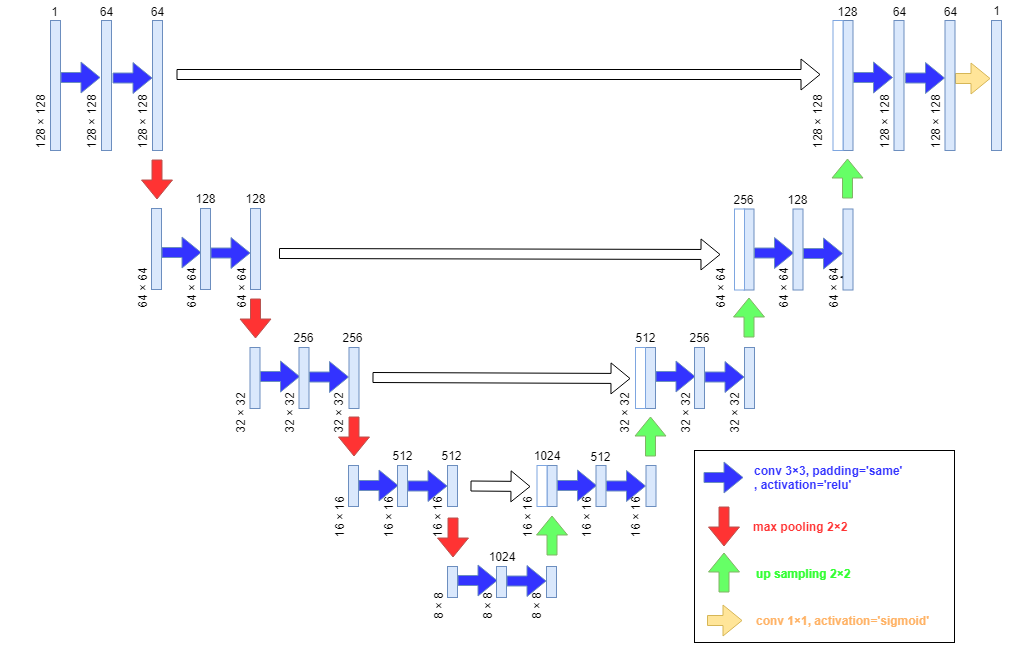
モデル
U-netの論文(*1)の通りにすると、Outputのサイズが、inputより小さくなるが、今回は、同じにしたい。
そこで、今回は、Convolutionするときに、paddingをして、サイズを落とさないようにする実装にしてみた。
loss関数は、Dice Coefficient
こんな感じ
学習
バッチサイズ : 5
エポック : 100
で学習実行
学習曲線は、こんな感じ
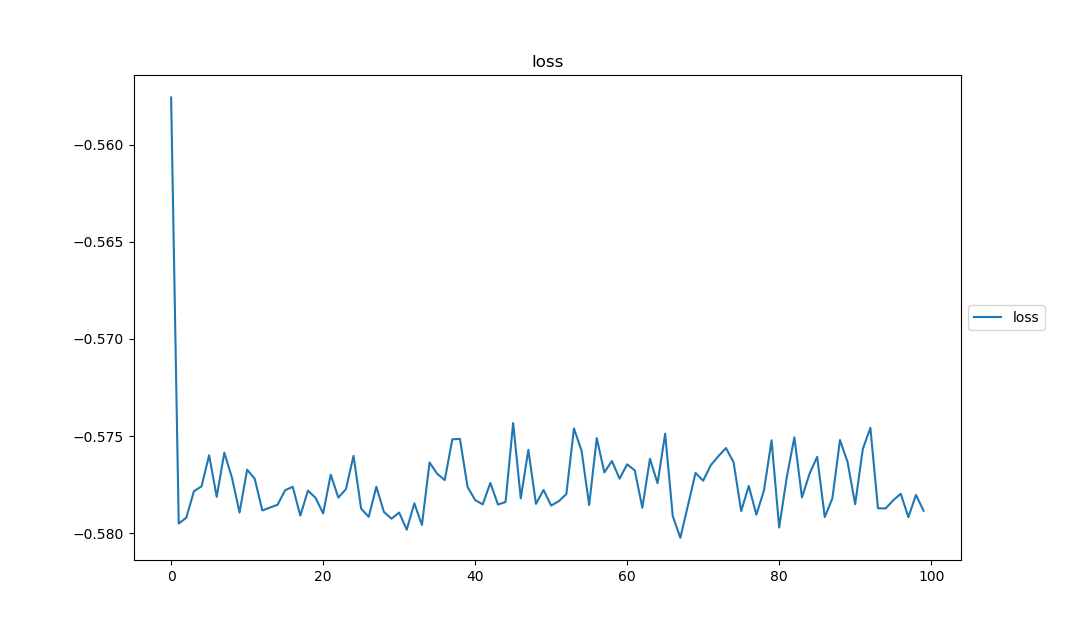
んん、なんか微妙?
結果
学習に使ったデータ












それぞれの列で、上から順に、入力/出力/理想(教師)
出力が真っ白に。。。
検証用データ(学習に使用しなかったデータ)












それぞれの列で、上から順に、入力/出力/理想
やはり、出力が真っ白。。。学習がうまく行ってないのだろうか...
学習曲線も、下がって行っているように見えないし。
まとめ
KerasでU-net構造のモデルを書くことはできたが、
結果を見る限り学習がうまく言ってなさそう。
改良を行い、学習がうまくいくようにしたい。
と、実は、既に、改良を行ってみたので、その結果も書いていこうと思いましたが、
記事が長くなったので、
U-net構造で、画像セグメンテーションしてみた。(2)に続く。
注釈
*1 : 参照 https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/