はじめに
Lambdaでは、DynamoDB Streamsでデータの変更を検知して実行することができます。以前は、変更のたびに毎回Lambdaが実行され、Lambdaのコード内で追加、更新、削除を判断して処理を行う必要がありました。この方法では、毎回Lambdaが実行されるため、その分、費用がかかる状態でした。
それが2021年11月のアップデートでLambda実行前に処理を実行するかどうかフィルタリングすることができるようになり、コードの簡略化や不要な実行がなくなり費用も低減できます。
今回は、実際にフィルタリングを設定し、実行してみます。
事前準備
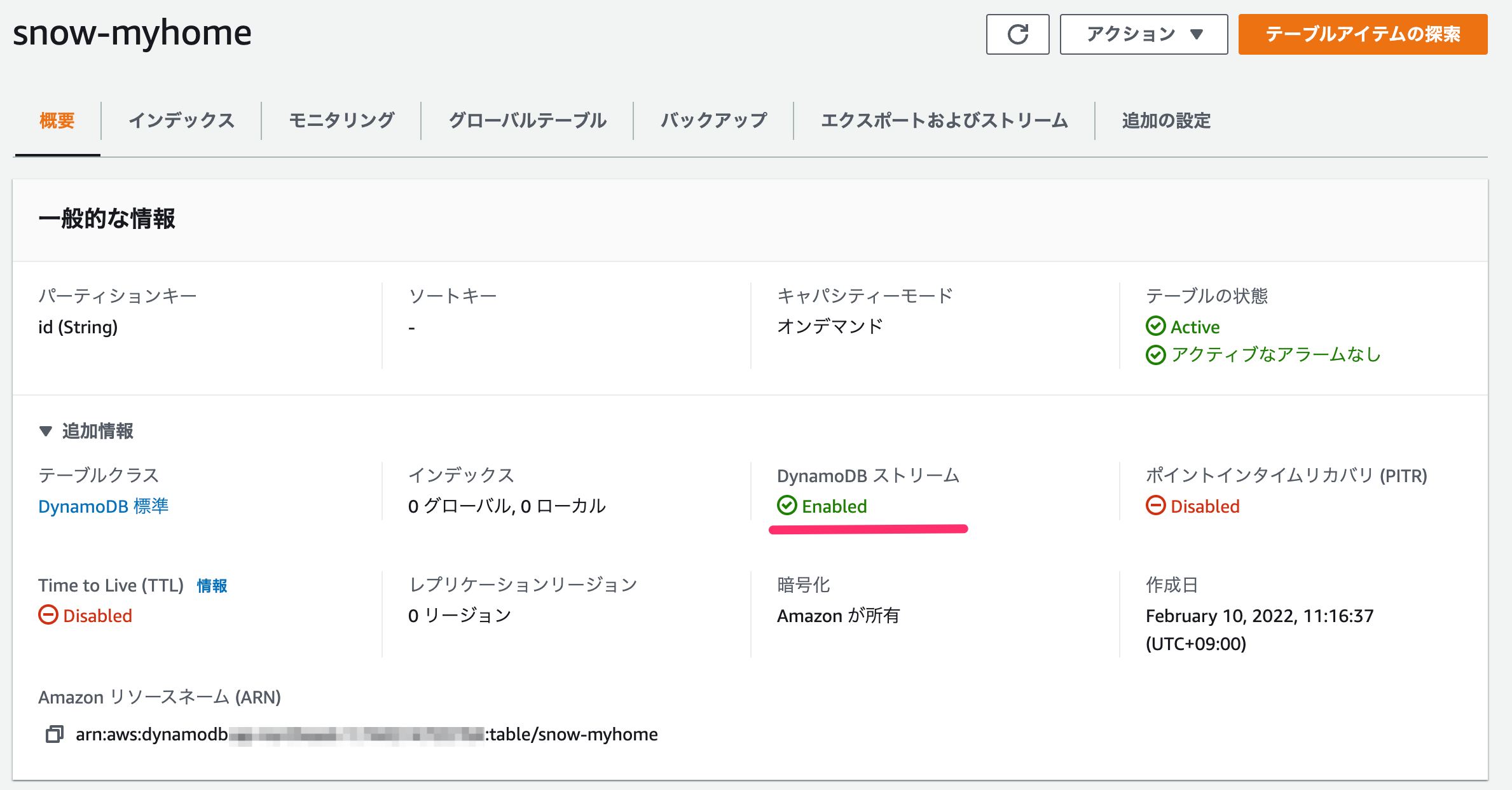
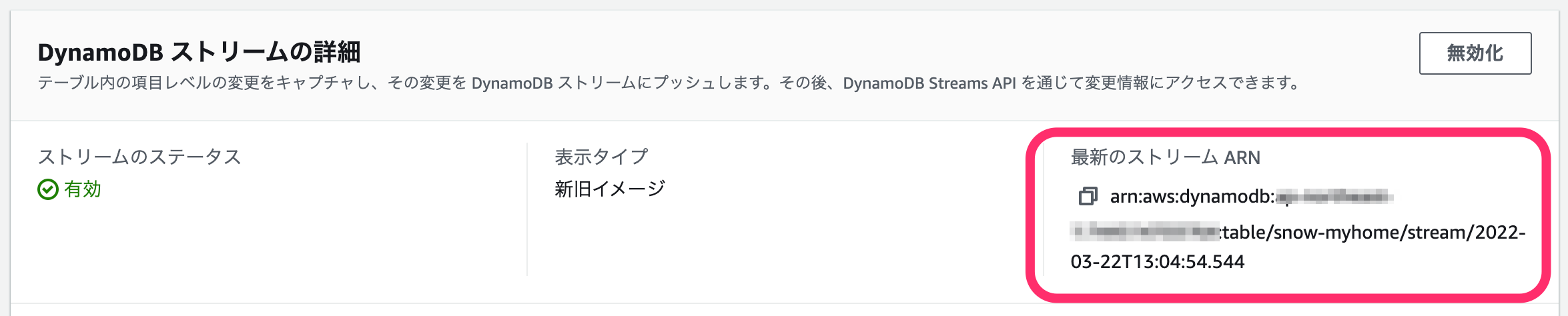
トリガーとなるDynamoDBのテーブルを作成し、ストリームを有効化しておきます。その後、ストリームARNをコピーしておきます。
Lambda Functionを作成する
今回は、pythonでログを出力するだけの処理で確認します。実際には、DynamoDBのテーブルにレコードが追加されたら、「管理者、ユーザに通知する」、「分析用のテーブルにレコードを追加する」等のユースケースで利用することがあるかと思います。
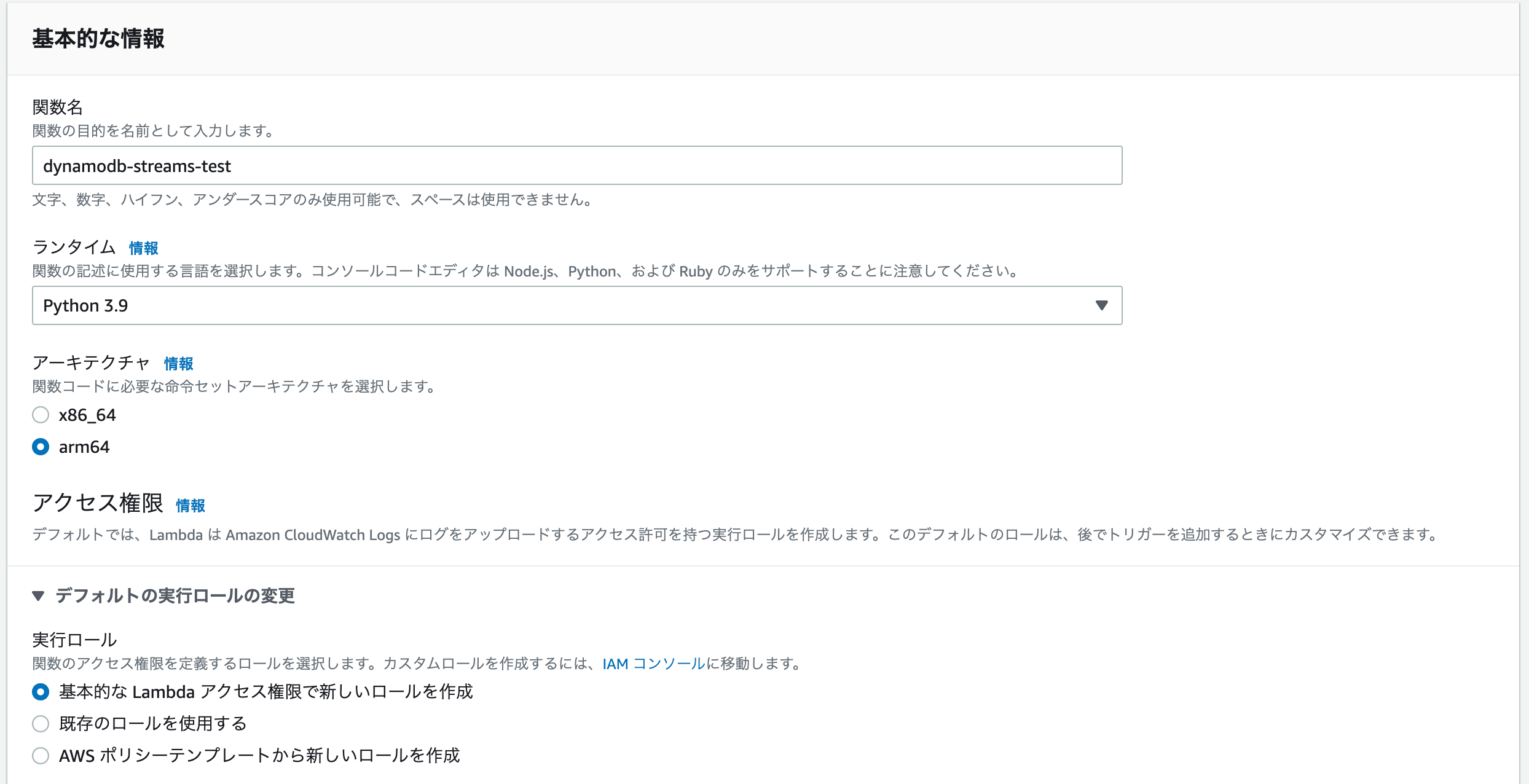
基本設定
Lambda Functionのソース
import json
def lambda_handler(event, context):
print("Received event: " + json.dumps(event))
for record in event['Records']:
print(record['eventID'])
print(record['eventName'])
print("DynamoDB Record: " + json.dumps(record['dynamodb']))
return 'Successfully processed {} records.'.format(len(event['Records']))
# アクセス権限
Lambda Functionのアクセス権限には以下の通り、DynamoDB Streamsへのアクセス権限が必要なります。※ポリシー抜粋
{
"Action": [
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeStream",
"dynamodb:ListStreams"
],
"Effect": "Allow",
"Resource": [
"arn:aws:dynamodb:[リージョン]:[アカウントID]:table/[テーブル名]/stream/[ストリームID]"
]
}
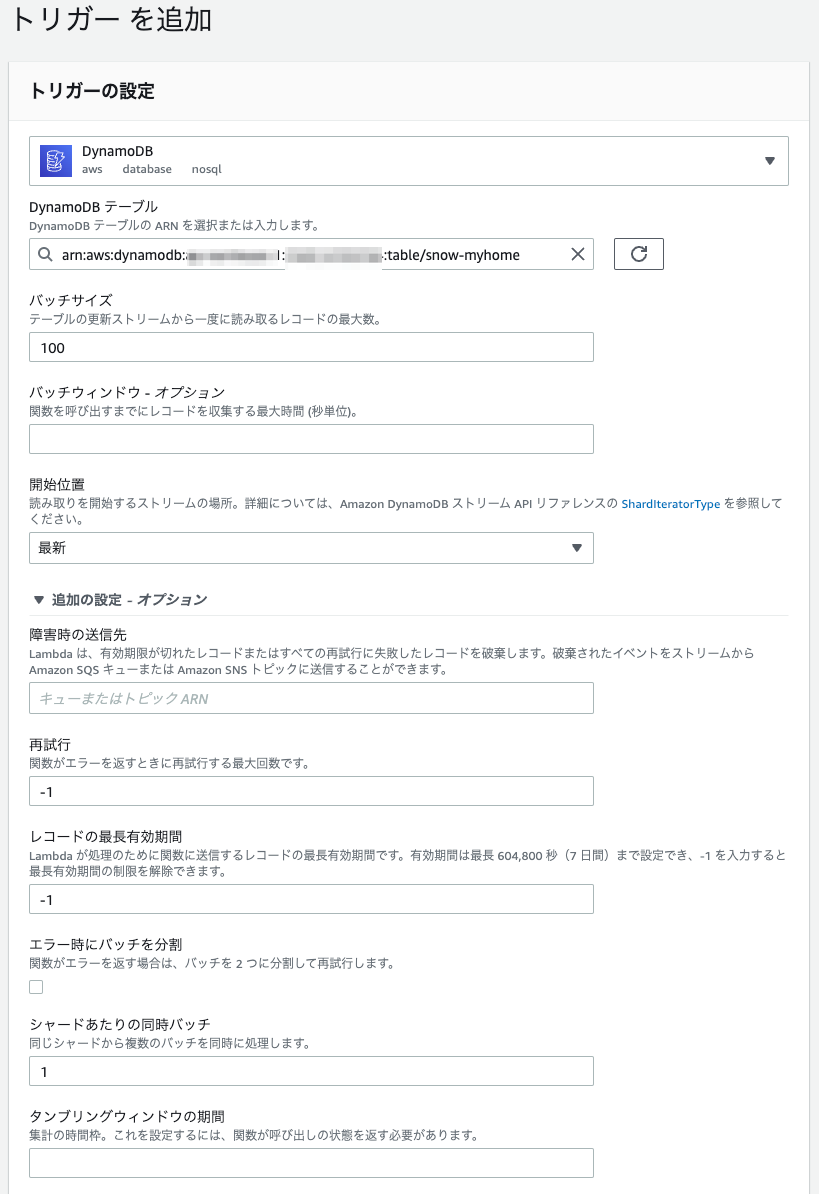
トリガー
トリガーにDynamoDBを設定します。フィルタリング条件については後述します。
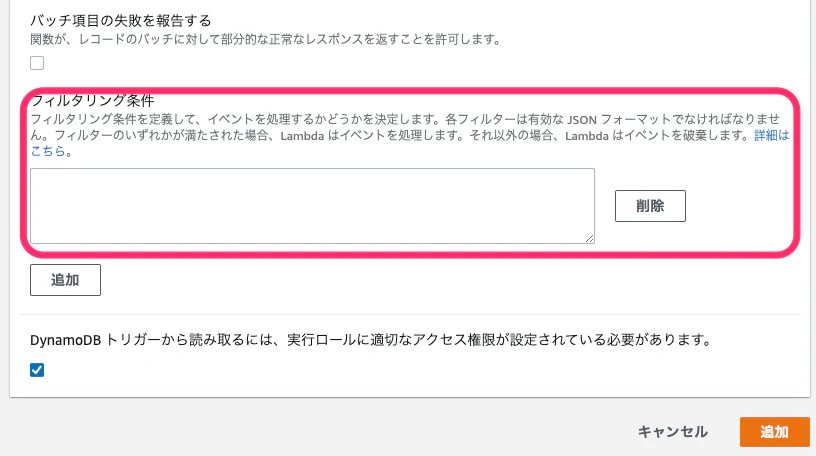
フィルタリング条件の設定
トリガー設定にあるフィルタリング条件を追加し、Lambda Functionを実行したい条件を設定します。
「追加」の場合に実行する
{
"eventName": ["INSERT"]
}
「更新」の場合に実行する
{
"eventName": ["UPDATE"]
}
「削除」の場合に実行する
{
"eventName": ["DELETE"]
}
細かいフィルタールールについては、以下を参考すると良いです。
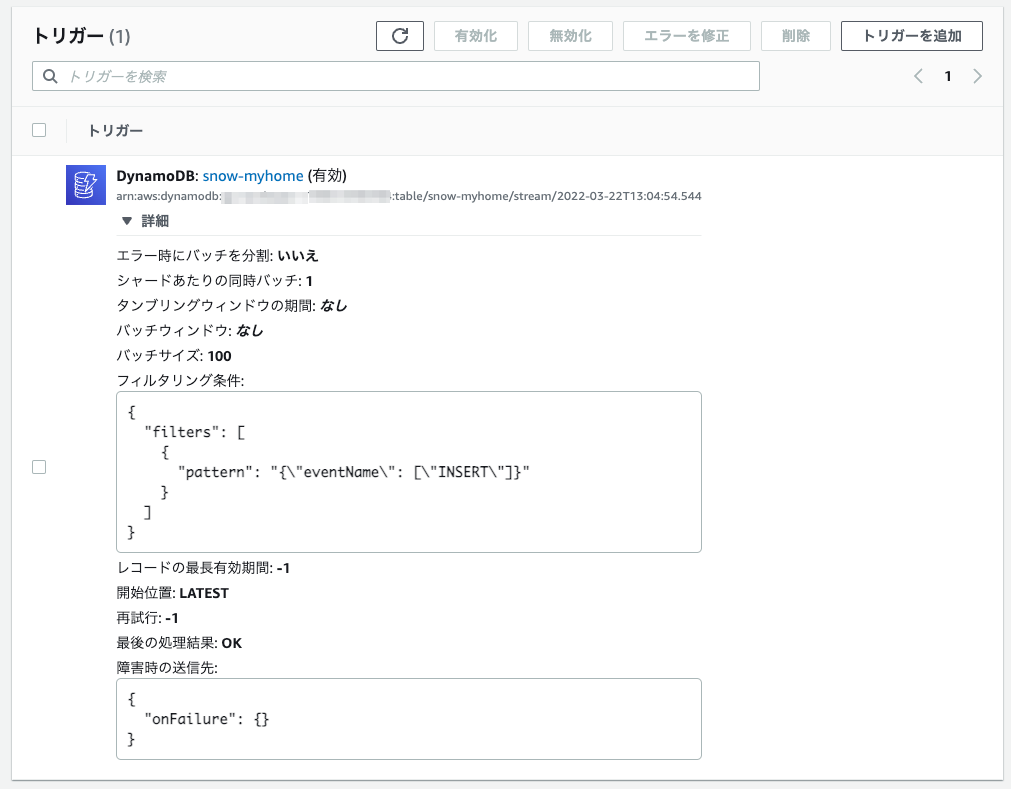
トリガーを確認する
設定したトリガーを確認します。追加したフィルタリング条件が設定されていることがわかります。
ご注意
作成された以下のフィルタリング条件をそのままコピーして作成しようとするとエラーになります。
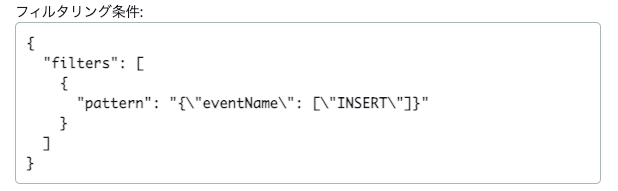
↓エラー。恥ずかしながらハマってました。。
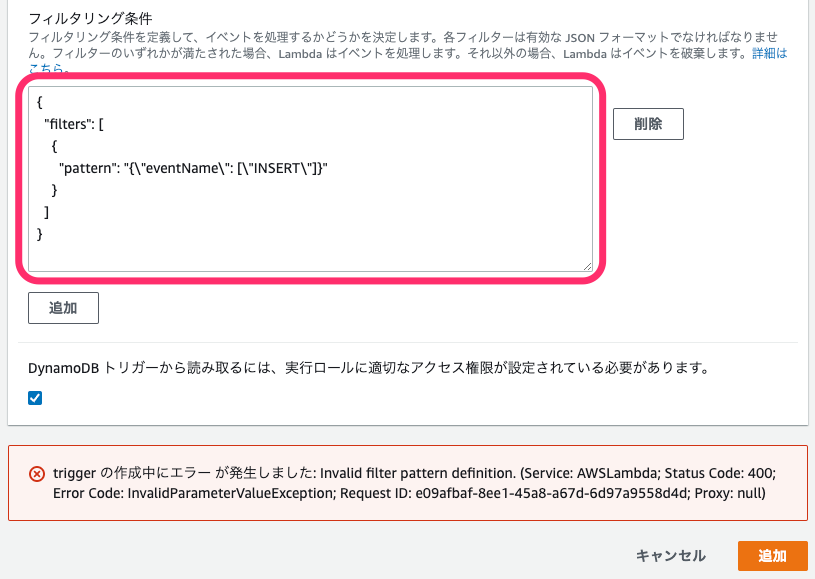
↓正解はこっちです。
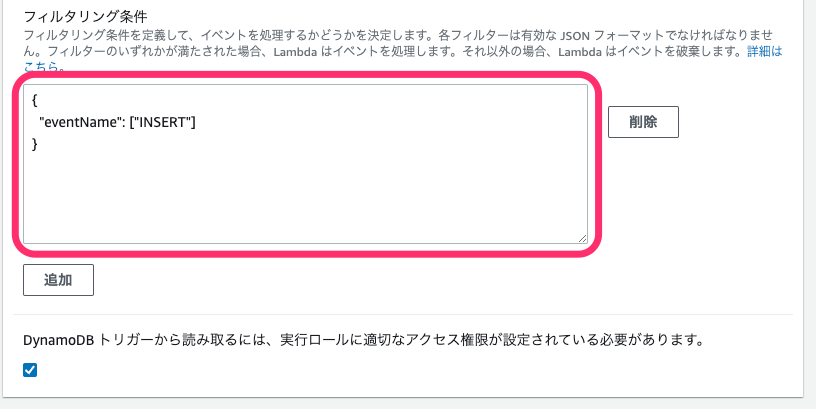
動きを確認する
では、実際に動かしてみます。以下が既存のテーブルです。

レコードを追加します。
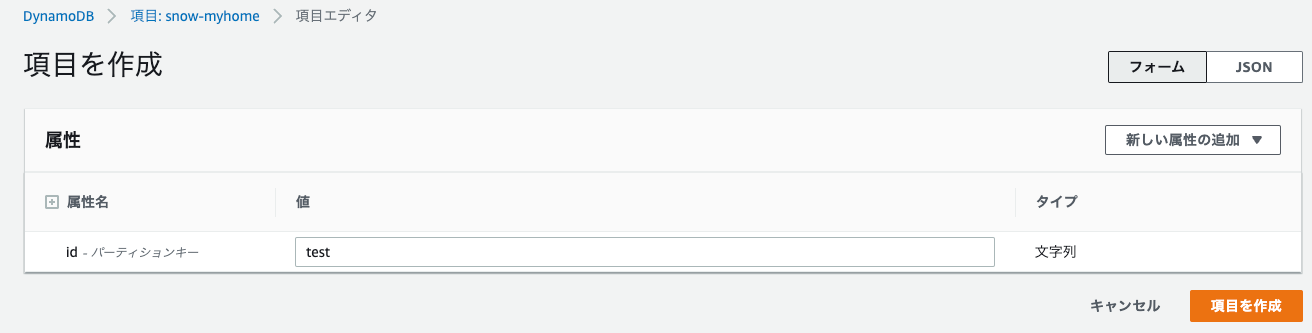
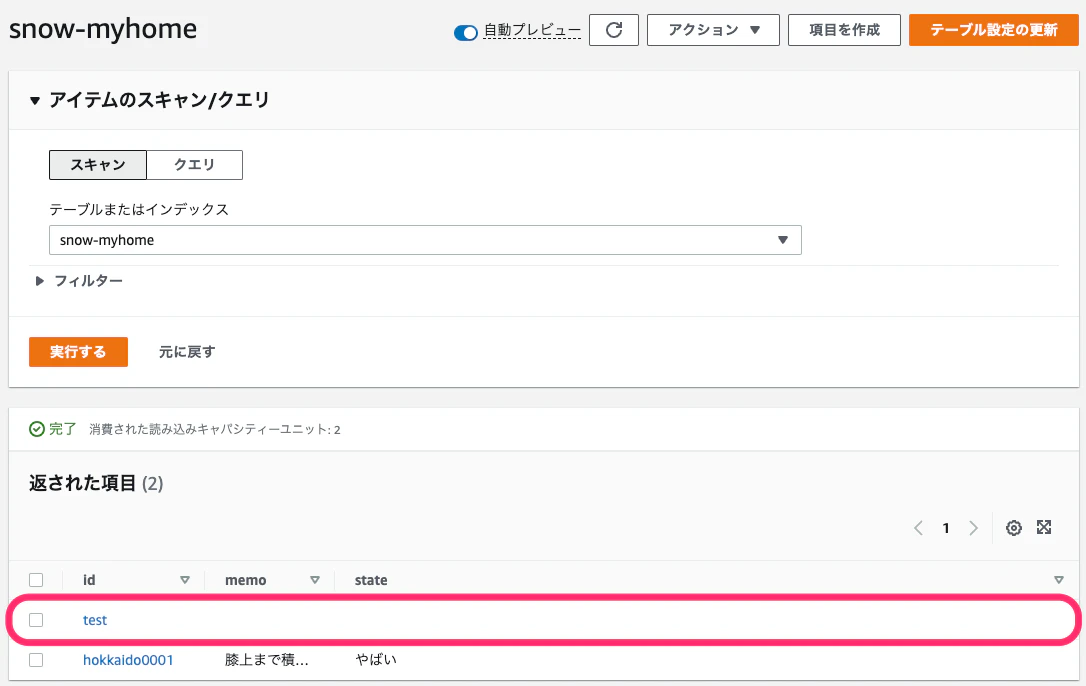
Lambda Functionのログが以下の通り、出力されています。
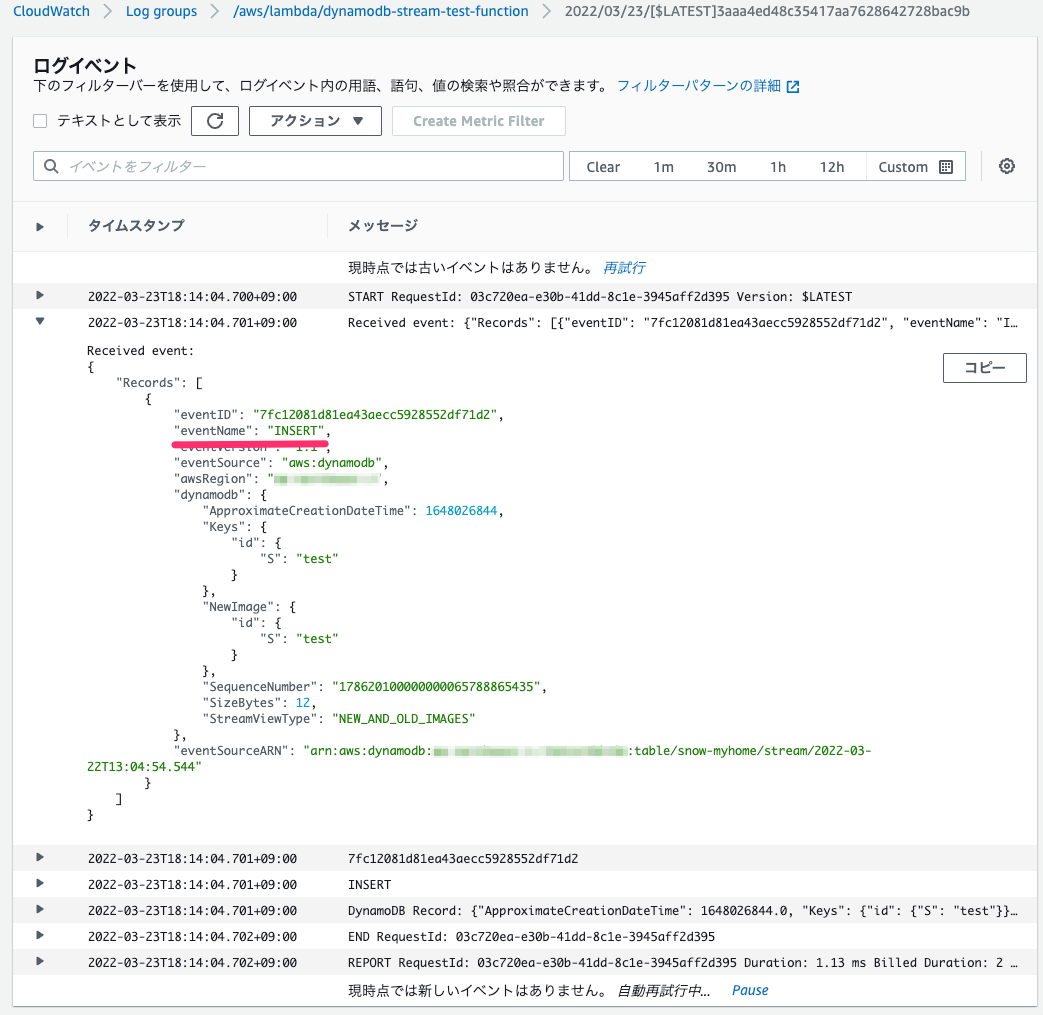
次にレコードの削除を行なってみます。
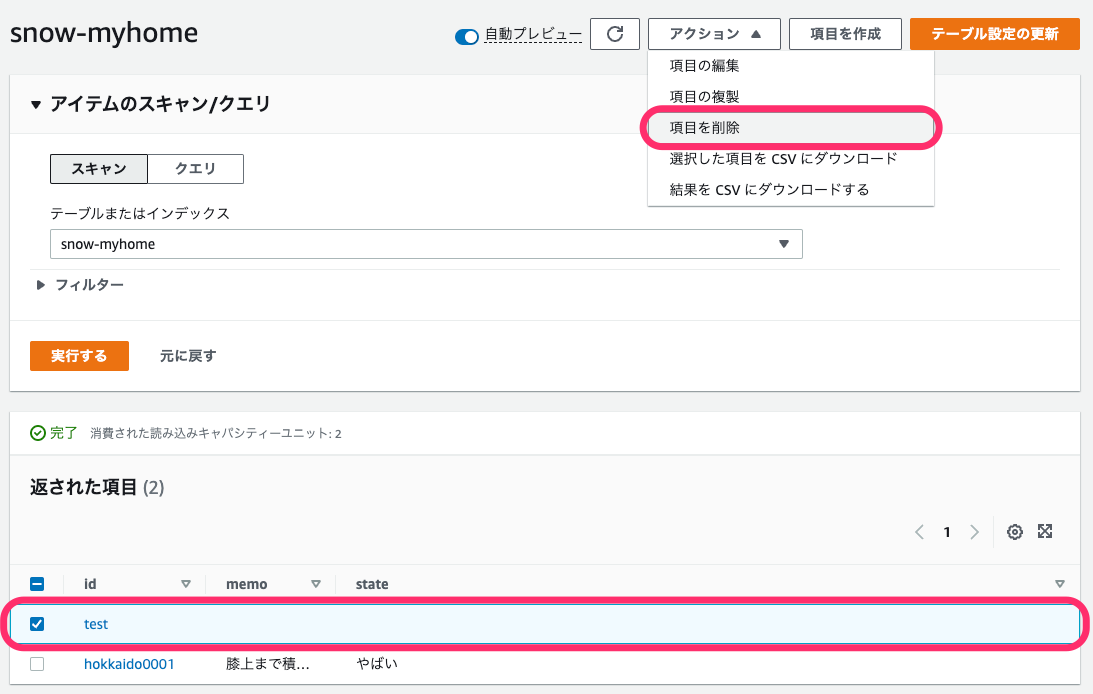
Lambda Functionのログが以下の通り、出力されていません。
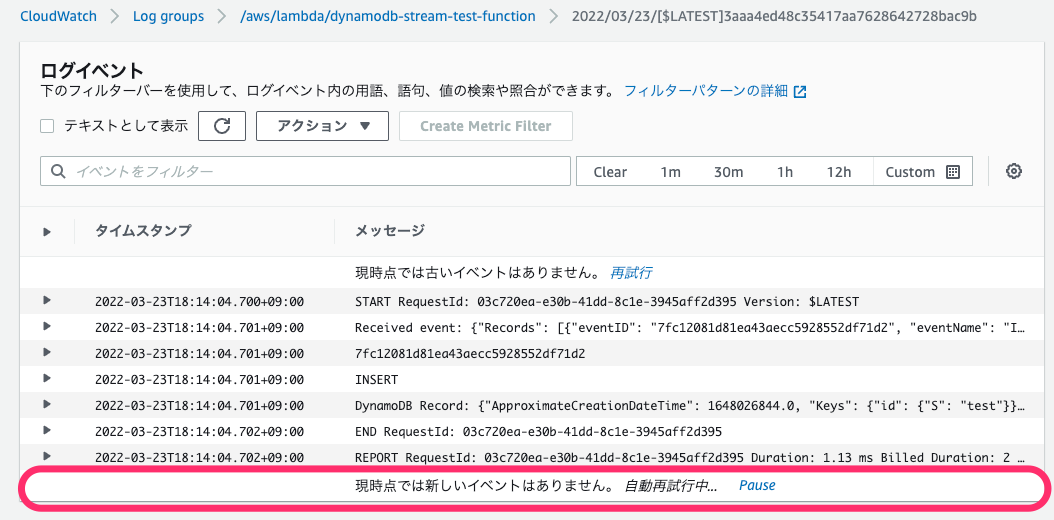
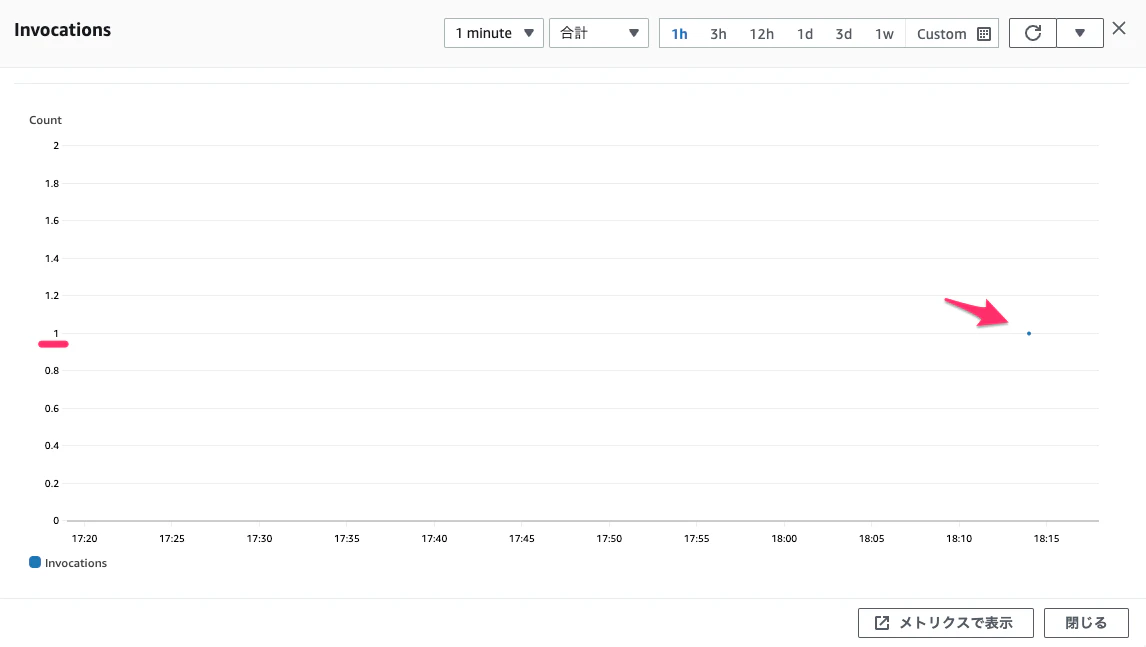
メトリクスも見てみます。Invocationsのカウントが1です。
おまけ(CLoudFormationテンプレート)
ここまで手動でやってきましたが、やはり手早く使いたい方もいるかと思いますので、CloudFormationテンプレートを載せておきます。レコードが追加された場合に実行されるサンプルになります。
AWSTemplateFormatVersion: '2010-09-09'
Description: 'Filtering event sources for AWS Lambda functions'
# Parameters
Parameters:
DynamoDBStreamsArn:
Type: String
MinLength: 1
# Resources
Resources:
# Role
ExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub '${AWS::StackName}-execution-role'
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Action:
- sts:AssumeRole
Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Path: /
Policies:
- PolicyName: lambda-execution-policy
PolicyDocument:
Version: 2012-10-17
Statement:
- Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Effect: Allow
Resource:
- !Sub 'arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/lambda/${AWS::StackName}-*'
- Action:
- dynamodb:GetRecords
- dynamodb:GetShardIterator
- dynamodb:DescribeStream
- dynamodb:ListStreams
Effect: Allow
Resource:
- !Ref DynamoDBStreamsArn
# Lambda
LambdaFunction:
Type: AWS::Lambda::Function
Properties:
Architectures:
- arm64
Code:
ZipFile: |
import json
def lambda_handler(event, context):
print("Received event: " + json.dumps(event))
for record in event['Records']:
print(record['eventID'])
print(record['eventName'])
print("DynamoDB Record: " + json.dumps(record['dynamodb']))
return 'Successfully processed {} records.'.format(len(event['Records']))
FunctionName: !Sub '${AWS::StackName}-function'
Handler: index.lambda_handler
MemorySize: 128
Role: !GetAtt ExecutionRole.Arn
Runtime: python3.9
Timeout: 300
# Lambda - EventSourceMapping
EventSourceMapping:
Type: AWS::Lambda::EventSourceMapping
Properties:
BatchSize: 100
BisectBatchOnFunctionError: false
Enabled: true
EventSourceArn: !Ref DynamoDBStreamsArn
FilterCriteria:
Filters:
- Pattern: "{\"eventName\": [\"INSERT\"]}"
FunctionName: !Ref LambdaFunction
MaximumBatchingWindowInSeconds: 0
MaximumRecordAgeInSeconds: -1
MaximumRetryAttempts: -1
ParallelizationFactor: 1
StartingPosition: LATEST
TumblingWindowInSeconds: 0
まとめ
フィルタリングの設定を行うことでフィルタリングするコードが不要となり、簡略化され、さらに費用が少なくなるのは良いですね。おまけ含めて、ぜひご活用いただければと思います。良いものは使いましょー