はじめに
みなさん、データベースをさわることって多いですか?
僕は全くです。
僕の普段の業務ではネイティブアプリの開発が主で、データベースとふれ合うことは滅多にありません。。
それでもこの記事を書こうと思ったのには理由があります。
僕は新卒2年目なのですが、弊社では新卒2年目向けの研修があります。
そこでは普段触れることが少ない技術や苦手な技術を担当してチームでサービス開発をします。
その研修を通して、データベースについてなかなか学べなかったなという反省がありました。
特に正規化~~(大学で学んだはずなのに抜けている...)~~について学ぶことを目標にしていましたが、他の作業で手をつけられずに不完全燃焼だったので何かしらの形でアウトプットして知見を深めようと心に決めました。
これはその行動の記録です。
ちなみに題材を「シェアハウス」にしたのは僕がたまたまシェアハウスに住んでいたのでイメージしやすいかなと思った、ただそれだけです。
正規化とは
リレーショナルデータベース(RDB)において、表の関連性を失わないように項目を整理して表を分離するとのこと。
正規化することで、データの更新や削除が容易に行えるようになります。
ほうほう。
じゃあ、実際にテーブルを正規化していってみよう
この記事で扱うデータ
どこぞのシェアハウス運営会社がハウス・住民・ハウスを管理するマネージャーの情報を集約したデータベースを作ってシステムを構築したい。と仮定してテーブルの設計をします。
※住民やハウス等の情報は適当なものです。
正規形の種類
正規形には
- 非正規形
- 第1正規形
- 第2正規形
- 第3正規形
- ボイスコッド正規形
- 第4正規形
- 第5正規形
があるそうです。
本記事では、一般的と言われている太字になっている正規形について見ていきます。
非正規形
早速作ってみました。
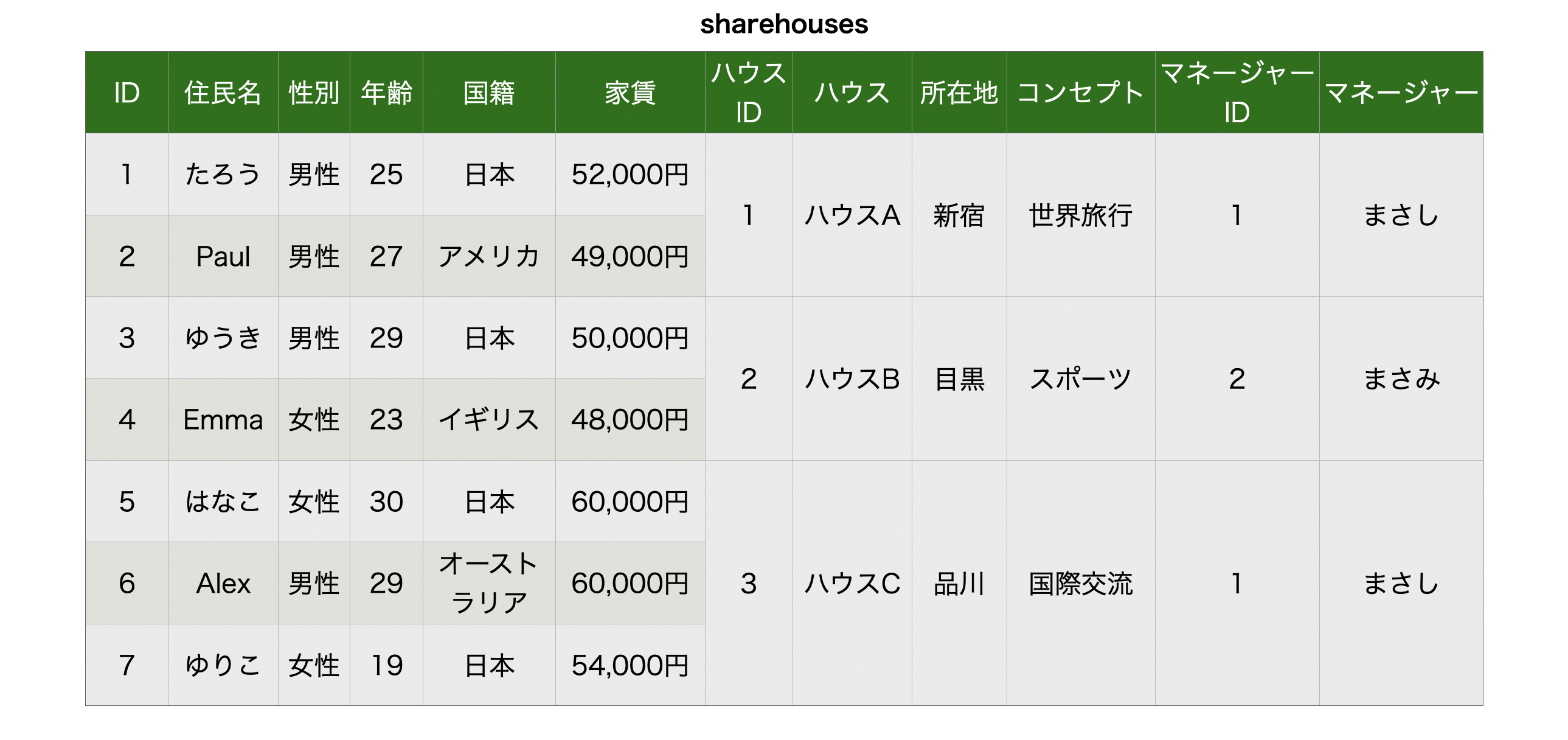
非正規形はエンジニアじゃなくても一般的にExcelとかでよく見かけるような形です。
重複する場所は結合されていてまとまって見やすいですね。
ただし非正規形はあくまで人の目で見てわかりやすい形になっているだけで、一行ずつのデータの操作を行うRDBでは扱うことができません。
そこで、正規化してRDBでも扱えるような形にしてあげます。
第1正規形
第1正規形では、繰り返し部分を除外することで「単一の値」としてRDBでも扱えるようにします。
要するに、下記の表のように結合されていた箇所を一行一行ちゃんと登録されてる状態にしましょうってやつですね。
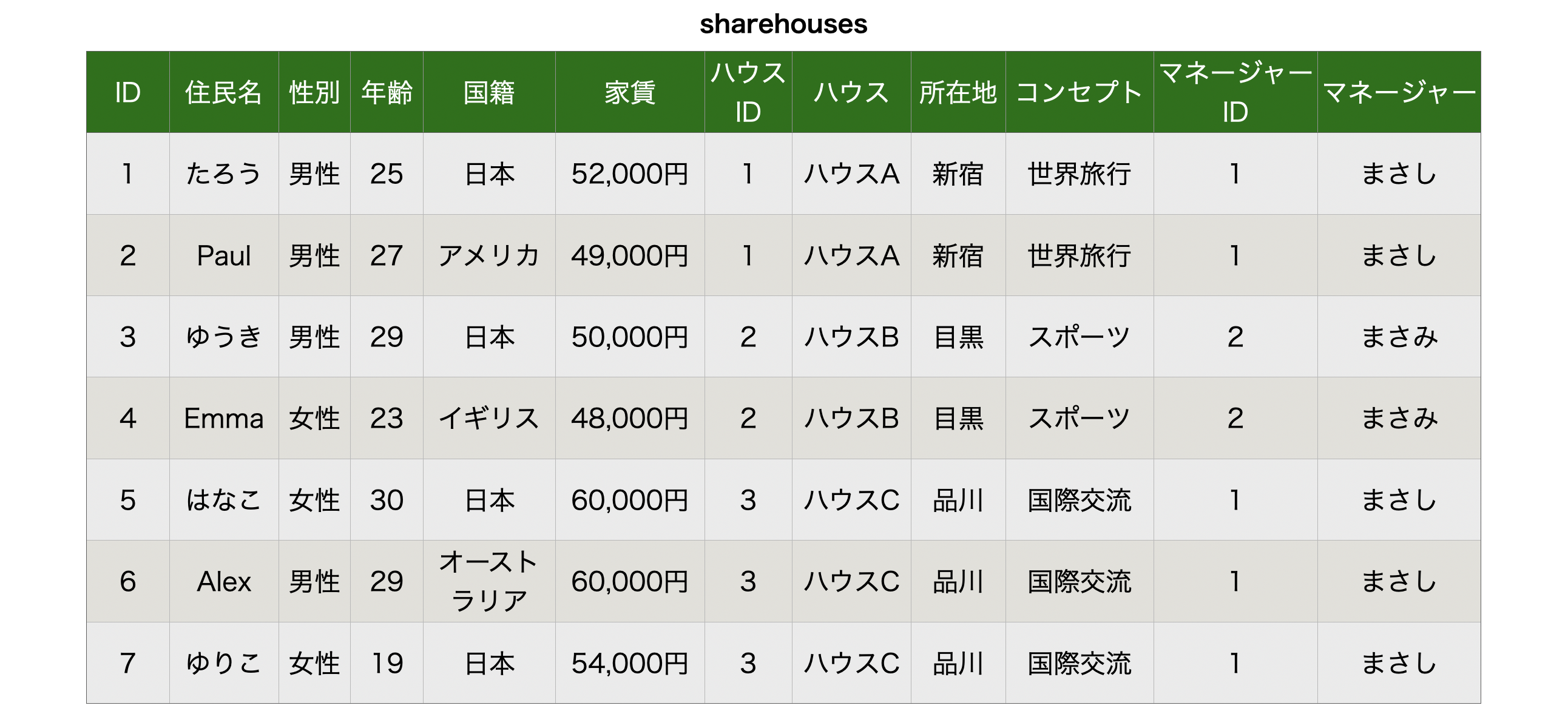
これでDBの操作ができるようになりました。
ただ、これだけでは少し問題があります。
例えば、たろうさんがハウスBに引っ越したとします。
そうすると、ハウスIDは**2(表の赤字)**になります。
それにつれて、「ハウス」や「所在地」、「マネージャー」等の情報も変更してあげなければいけませんね(表の太字部分)。
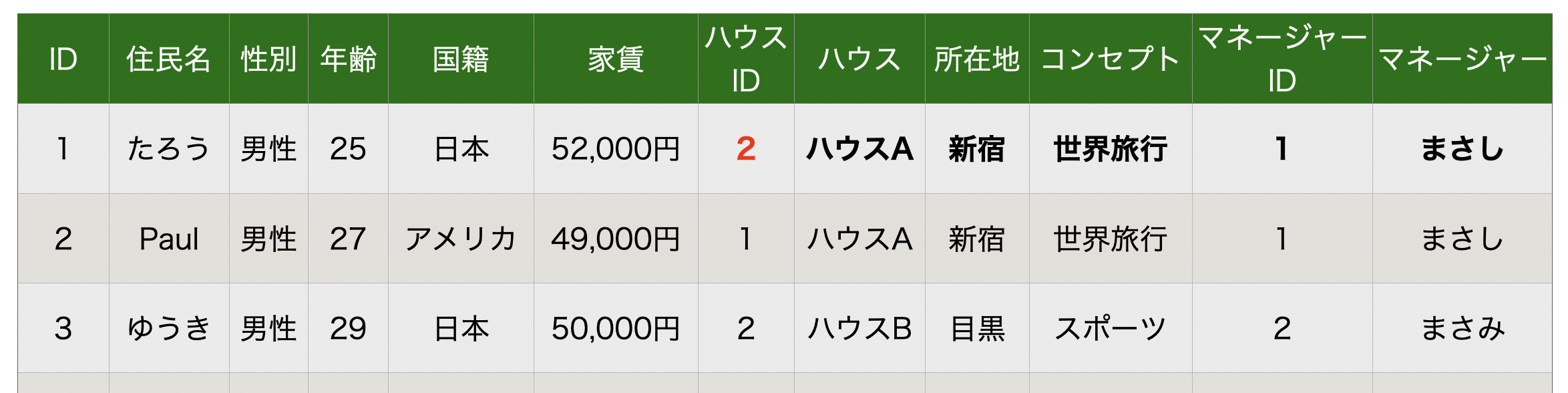
また、ハウスCのオーナーさんが「うちのコンセプトを新しくしたい!新しいコンセプトは世界のゲームにする!」って言ったとします。
この場合、ハウスCのコンセプトの列を修正しないといけません。
作った表には3つのデータしかありませんが、このハウスが100人規模のシェアハウスだったら100箇所のデータを更新してあげなければいけません。
めんどくさいですよね...

じゃあ正規化してこのめんどくささを解消しましょう。
第2正規形
第1から第2正規形にするには、まず「関数従属」について知っておかなければなりません。
関数従属というのはxが決まればyがわかるといいったものです。
そして第2正規形にする条件は、部分関数従属を排除されているというものです。
はい??
わかりにくいので、具体例で見てみましょう。
sharehousesテーブルのうち、ハウスIDがわかれば、ハウスよりも右の列の情報がわかりますが住民名や性別まではわかりません。
これがハウスよりも右の列の情報が部分的に関数従属しているということなんですね。
これを排除してあげるのが、第2正規形にするということです。
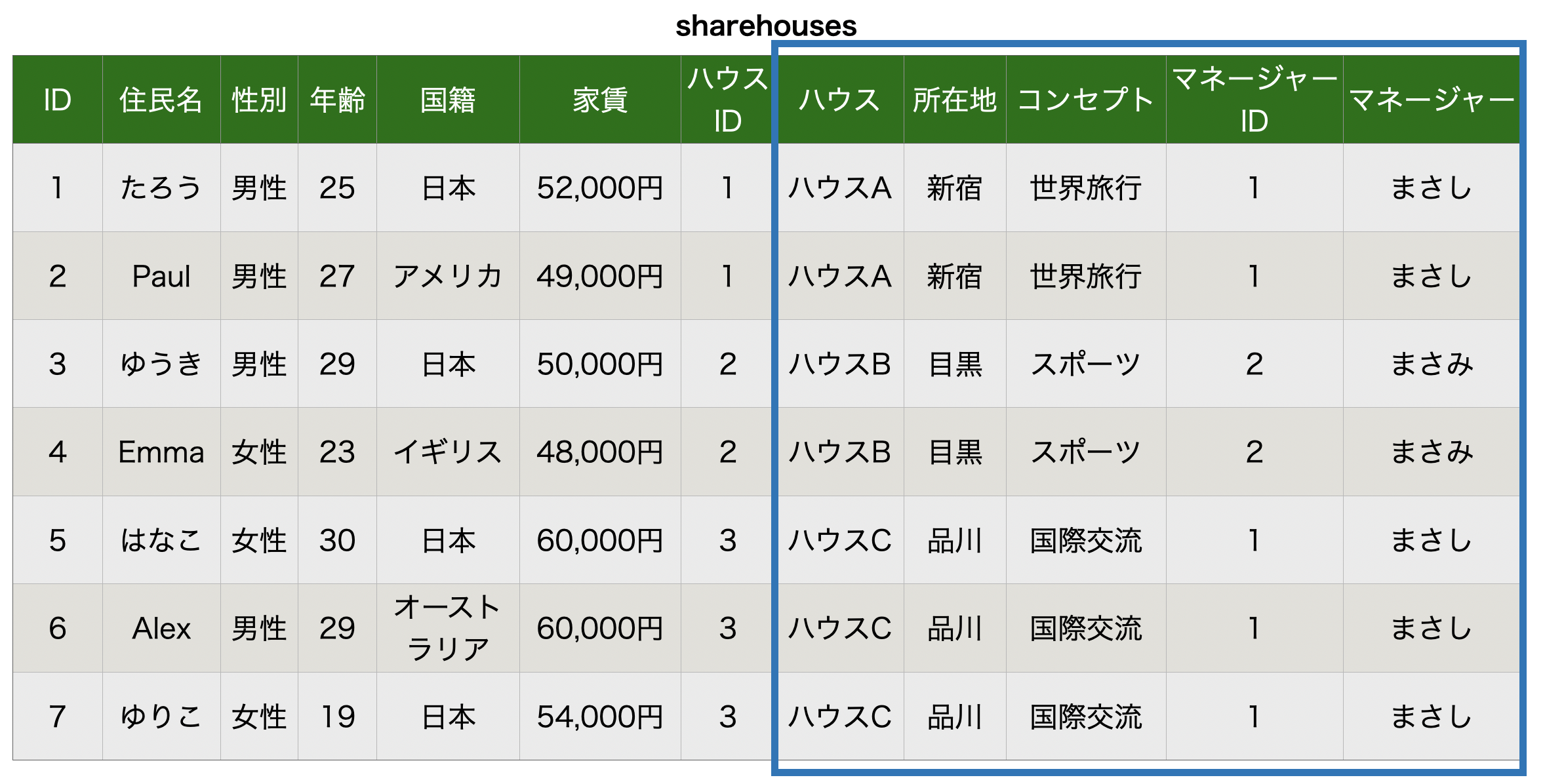
やってみたのがこちら。
residents(住民)テーブルとhouses(ハウス)テーブルに分割しました。
また、residents(住民)テーブルではハウスIDという列を追加してハウスの情報を参照できるようにしました。
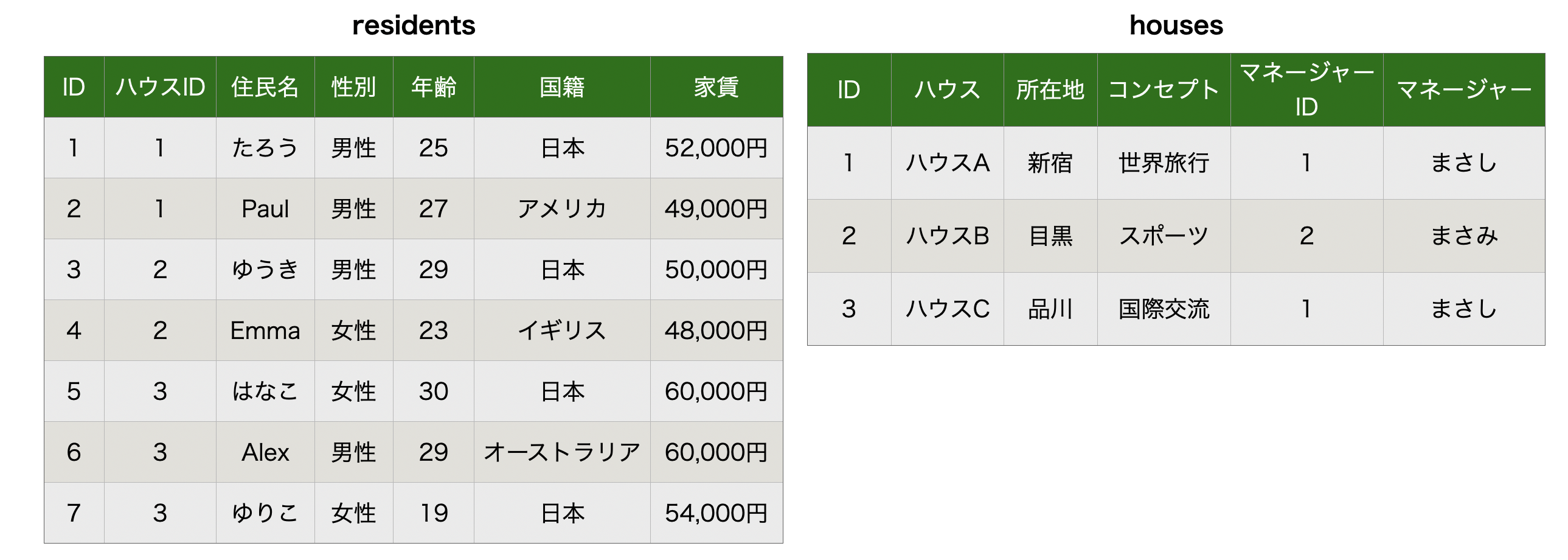
これによって、冗長性がなくなりました。
さっきの第1正規形の例であった「ハウスCのコンセプトを世界のゲームにしたい!」という話が上がっても、housesテーブルの該当箇所を1箇所直すだけでよくなり、residentsテーブルではハウスIDを参照しておけば良いという状態になります。
ハウスを引っ越す場合もresidentsテーブルのハウスIDを更新すればそれで終わりです。
とても変化に柔軟になりました!
第3正規形
第2正規形で部分関数従属を排除できてスッキリできました。
しかし、まだ第2正規形のテーブルの中にはまだ冗長なものがあります。
第3正規形にするには推移的関数従属を排除することを行います。
推移的関数従属とはxが決まればyが決まり、yが決まればzが決まるというものです。
これを第2正規形のhousesテーブルで見ると、以下のようなイメージです。
IDがわかればマネージャーIDがわかり、マネージャーIDがわかればマネージャーがわかるという関係ですね。
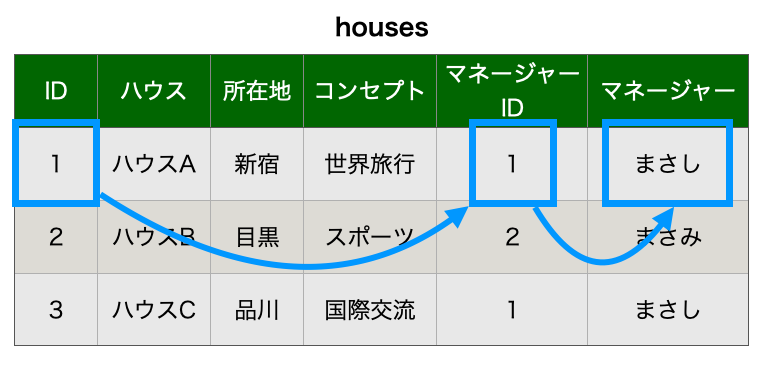
これを排除してあげれば良いので、housesテーブルからマネージャーの情報を分割させます。
できた表は以下になりました。
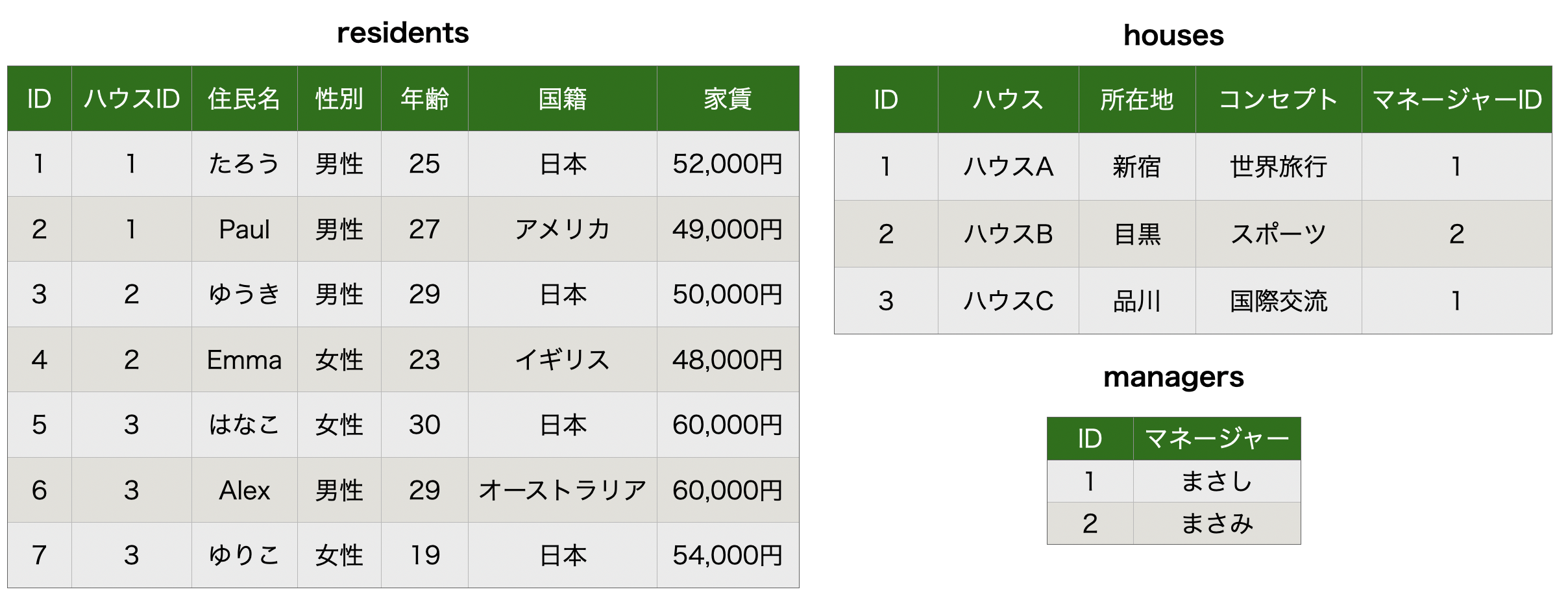
たまたま作成したテーブルにマネージャーの情報が少ないのでしなくても良いじゃんと思ったりするかもしれませんが、マネージャーの情報が増えてくると恩恵を感じられるようになるかと思います。
修正
作成したテーブルをチームの人たちにみてもらい上司から「この表の中にデータとしてあまり持たせない方が良いものがあるよ」と言われました。
さあ、どのテーブルのどの列で、どうするべきでしょうか?
正解は以下、年齢を生年月日にするでした。
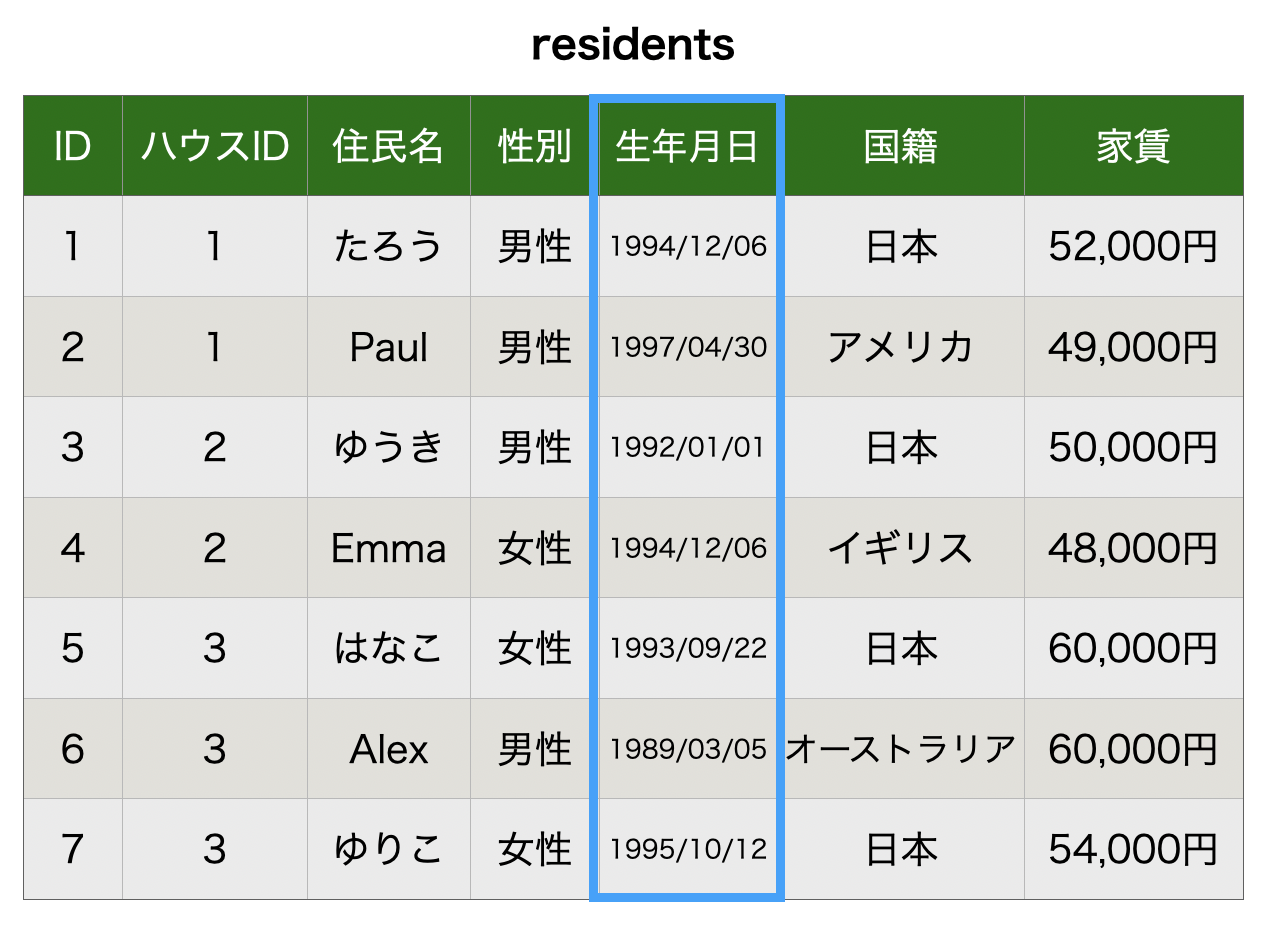
なぜ年齢にしない方が良いかというと、データベースが1年に1回誕生日を迎えた人の年齢の値を都度都度更新しなければならず、コストがかかるからです。
データベースの操作ができるとはいえ、なるべくデータを操作しない設計にするのが望ましいのですね。
また、このテーブルについて議論しているうちに自分でもこの列はおかしいと思うものを見つけました。
それは、家賃です。
確かにresidentsが支払うものであるからここに持たせるのが自然かと思っていましたが、家賃というのはハウスや部屋ごとに決まるもののため、住民テーブルに持たせるのは不適切かもしれないと考えました。
そこで住民テーブルから家賃を切り離して家賃テーブル(rents)を持たせる設計にしてみました。
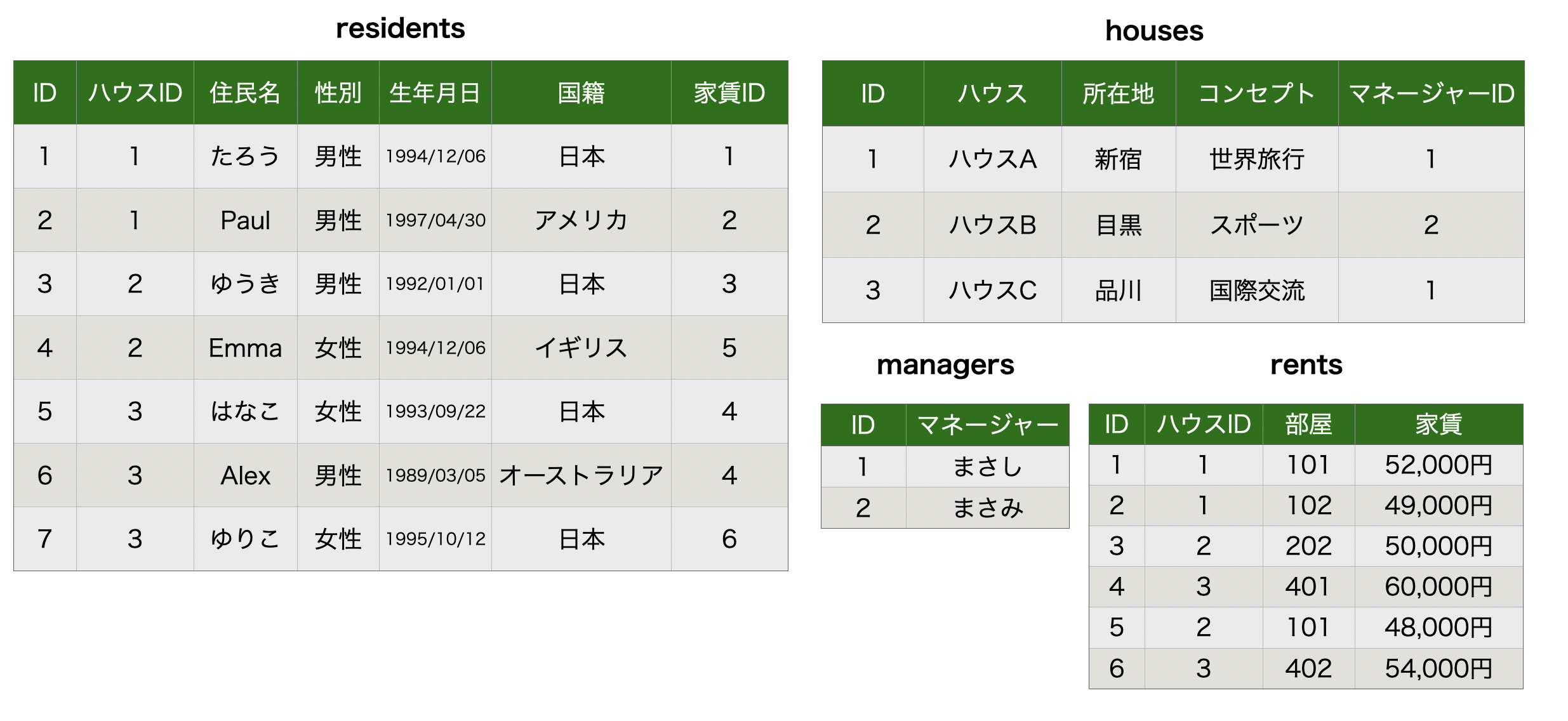
これで家賃と住民、ハウスの関連性を持たせることができてスッキリしたかなと思います。
SQLの影響
作成した各テーブルに対して、SQLを作成/実行したときにどのように変化もあるのかを考えてみました。
今回は、マネージャーがまさしさんであるハウスの情報と住んでいる人の名前を知りたいといったケースでのSQLについて考えてみました。
SQL文
作成したSQL文は以下になります。※あくまで一例です。
第1正規形
SELECT id, housename, address, concept, residentname FROM sharehouse WHERE managername = 'まさし';
第2正規形
SELECT h.id, h.housename, h.address, h.concept, r.residentname FROM houses h
LEFT JOIN residents r ON h.id = r.house_id
WHERE managername = 'まさし';
第3正規形
SELECT id, housename, address, concept, residentname FROM
(SELECT h.id, h.housename, h.address, h.concept, r.residentname, m.managername FROM houses h
LEFT JOIN managers m ON h.manager_id = m.id
LEFT JOIN residents r ON h.id = r.house_id) sharehouses
WHERE managername = 'まさし';
正規化してテーブルが増えていくにつれて参照しなければいけないテーブルも増えるので、SQLが複雑になっていきます。
パフォーマンス
ローカル環境にそれぞれの正規形のデータベースとテーブルを作成し、約12万件のサンプルデータを用意して実行速度を確認してみました。
|正規形|速度|
|---|---|---|
|第1正規形|0.09 sec|
|第2正規形|0.38 sec|
|第3正規形|0.10 sec|
数百件とかではまだ違いはみられませんでしたが、膨大なデータを扱うようになるとパフォーマンスに影響が現れました。
予想ではテーブルの数が多く、その分テーブル間の参照回数が多そうな第3正規形が一番遅くなるのかと思いきや第2正規形が最も遅くなる結果となりました。
ちなみに、実行計画は以下のようになりました。
第1正規形

第2正規形

第3正規形

疑問点
さすがにSQLを見るに、第2正規形のものよりも複雑なSQLになっているのにここまで早くなるのはおかしいと思い、第3正規形のサブクエリ部分のみを実行して実行時間を確認してみました。
SELECT h.id, h.housename, h.address, h.concept, r.residentname, m.managername FROM houses h
LEFT JOIN managers m ON h.manager_id = m.id
LEFT JOIN residents r ON h.id = r.house_id
結果は0.40secでした。
と、いうことは0.4sec + 0.10secの0.50secくらい処理に時間がかかっている?
SQLの実行時に表示される時間が実行時間のどの部分を表しているのかまで今回突き止めることができなかったので、ここについて詳しい方がいたらご教授願いたいです(;_;)
おわりに
正規化することで、テーブルの冗長性がなくなり管理しやすくなる一方でSQLのパフォーマンスにも影響が出るので、どの設計が適切かを考えるのが重要だということがわかりました。
SQLのパフォーマンス向上にはテーブル設計を見直す以外にも下記等の方法があるようです。
- そもそものSQLを見直す
- INDEXを作成する
- キャッシュ機構を用意する
この辺りの知識も別の機会にインプットしていけたらなと思います。
今回は自分なりにテーブルを作り、職場の先輩方のレビューをもとにテーブルの設計やパフォーマンスについてを考えられて、正規形についての理解が深まったと思います。
もっとこういう設計にした方が良いとかアドバイス等いただければ幸いです。