Fast and Elegant Scraping Framework for Gophers
インストール
$ brew install go
$ go get -u github.com/gocolly/colly/...
実装サンプル
許可ドメイン内でクロールする
basic.go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// リクエスト許可するドメインの設定
c.AllowedDomains = []string{"jp.leagueoflegends.com", "support.riotgames.com"}
// HTMLもらった時に実行するコールバック
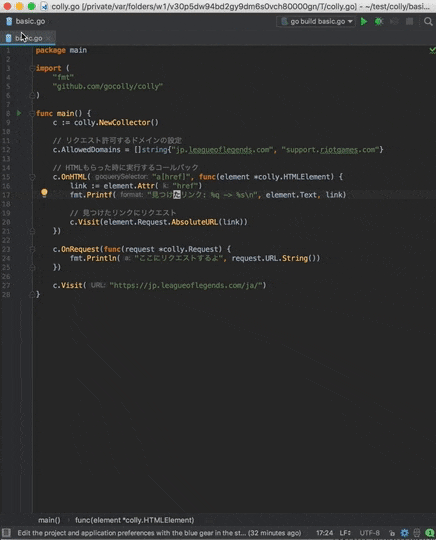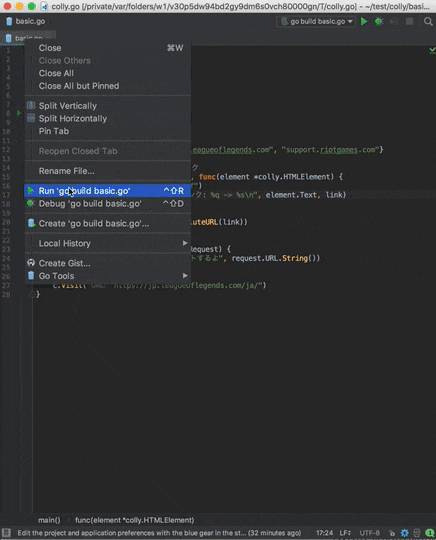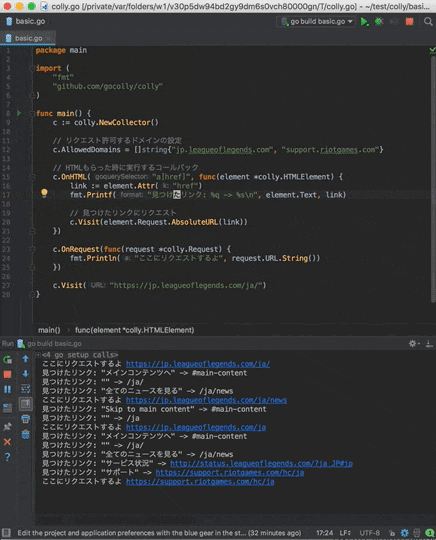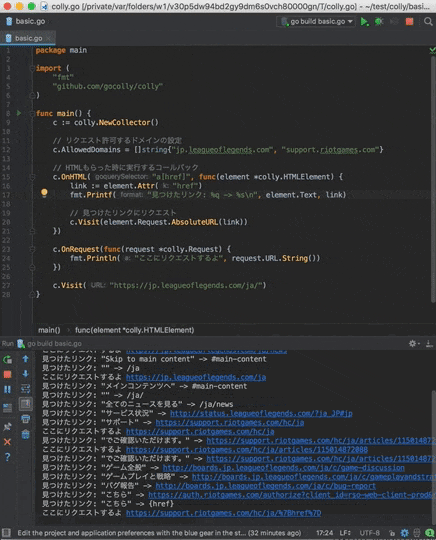
c.OnHTML("a[href]", func(element *colly.HTMLElement) {
link := element.Attr("href")
fmt.Printf("見つけたリンク: %q -> %s\n", element.Text, link)
// 見つけたリンクにリクエスト
c.Visit(element.Request.AbsoluteURL(link))
})
c.OnRequest(func(request *colly.Request) {
fmt.Println("ここにリクエストするよ", request.URL.String())
})
c.Visit("https://jp.leagueoflegends.com/ja/")
}
一覧ページから個別ページ入ってデータ収集
lol_champions.go
package main
import (
"log"
"github.com/gocolly/colly"
)
type Champion struct {
URL string
Name string
AD string
AR string
AP string
Difficulty string
}
func main() {
c := colly.NewCollector()
detailCollector := c.Clone()
champions := make([]Champion, 0)
// 一覧ページから個別ページURLを取得して個別ページ用のコレクタでリクエストする
link_selector := "#sortabletable1 tr td:nth-child(1) > a"
c.OnHTML(link_selector, func(e *colly.HTMLElement) {
href := e.Attr("href")
url := e.Request.AbsoluteURL(href)
log.Println("URL: ", url)
detailCollector.Visit(url)
})
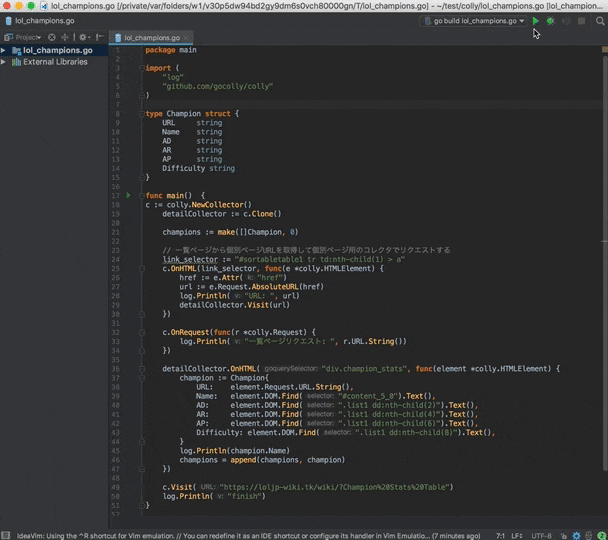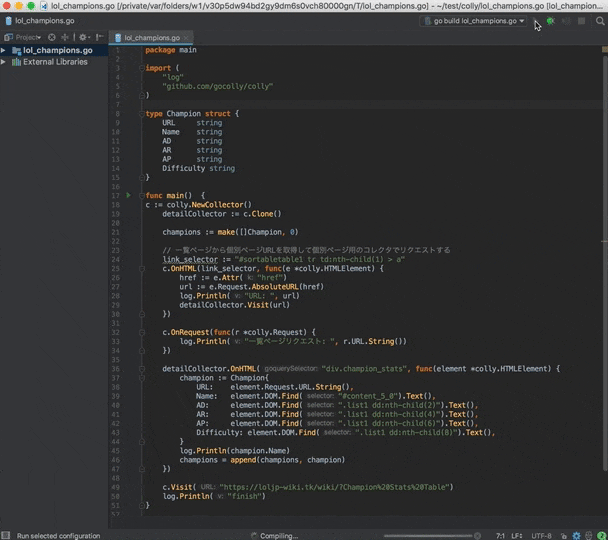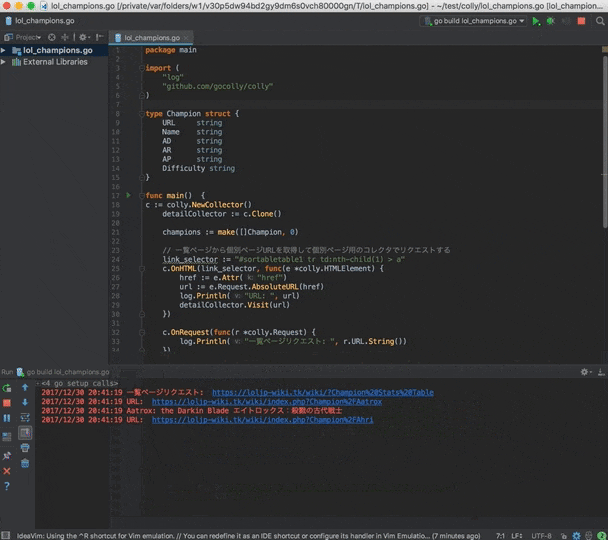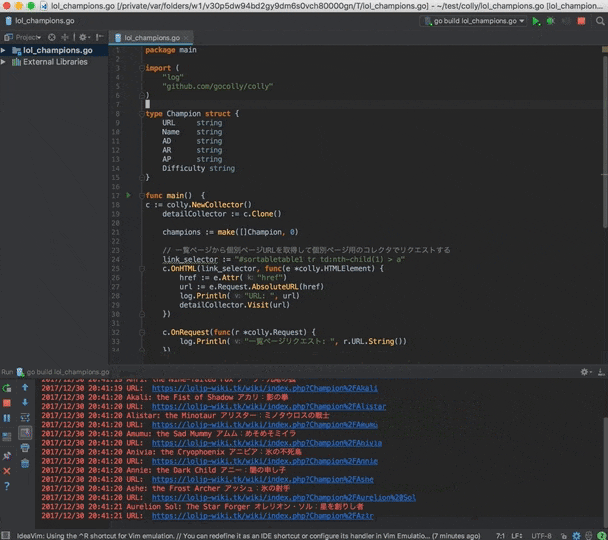
c.OnRequest(func(r *colly.Request) {
log.Println("一覧ページリクエスト: ", r.URL.String())
})
detailCollector.OnHTML("div.champion_stats", func(element *colly.HTMLElement) {
champion := Champion{
URL: element.Request.URL.String(),
Name: element.DOM.Find("#content_5_0").Text(),
AD: element.DOM.Find(".list1 dd:nth-child(2)").Text(),
AR: element.DOM.Find(".list1 dd:nth-child(4)").Text(),
AP: element.DOM.Find(".list1 dd:nth-child(6)").Text(),
Difficulty: element.DOM.Find(".list1 dd:nth-child(8)").Text(),
}
log.Println(champion.Name)
champions = append(champions, champion)
})
c.Visit("https://loljp-wiki.tk/wiki/?Champion%20Stats%20Table")
log.Println("finish")
}