はじめに
Azureで簡単にRAG(独自データに基づいた会話ができる生成AI)を構築できる機能「On Your Data」が2024/2にGAされました。
この機能について簡単な解説とともに利用方法、性能評価の紹介をします。
なお、本機能は更新が頻繁に入る機能であるため、執筆時と内容が変わっている可能性があります。本記事は2024/03/01時点のデータをもとに執筆しているためご容赦ください。
結論
On Your Dataはプレビュー版初期と比べ、検索手法追加などで精度よく回答が出力されるようになっており、検索として十分実用的になっている。
一方、検索された内容を前提に発展的な会話をするという用途であれば、チュートリアルレベルの実装では難しい。ただし、プロンプトなど多少の工夫で実現できる可能性はある。
On Your Dataについて
Azure OpenAI Serviceの「On Your Data」は、一般的なデータではなく独自データに基づいて回答する生成AIを簡単に構築できる機能です。
Azure OpenAIの機能(拡張機能?)としての位置付けで、Azure OpenAIからリソースを作成した後、Azure OpenAI Studioの画面から使えます。Azure OpenAI Studioは元々ブラウザ上でチャット機能を試せるサービスですが、On Your Dataを用いるとさらにそこに独自データの読み込み設定を簡単にできます。
独自データの格納方法は2024/03/01時点で下記から選べます。
- ファイルの直接アップロード
- BlobStorageに格納されているデータ
- CosmosDB for MongoDB vCore
- Azure AI Serach(作成済みのインデックス)
- Web Address
On Your Dataは2023年6月ごろにプレビュー版として公開されており、2024年2月に一般公開されました。ただ私が以前触った2023年7月ごろの時点では、なかなか日本語で精度を出すことが難しい状態でした。
当時はデータの検索手法として、テキスト検索とセマンティック検索という2つの検索手法があったのですが、日本語はテキスト検索しか対応しておらず、単純なキーワードの合致性でしか検索できませんでした。
しかし、その後2023年8月の更新でベクトル検索が可能になり、より意味に着目した検索ができるようになりました。
ベクトル検索とは
テキストを多次元空間上のベクトルに変換し、その類似度を計算して検索を行う手法です。ベクトルの「向き」と「大きさ」から単語のより意味的な類似性を捉えることができます。基本的には高校で習うベクトルと同じです。ただ、X,Yの2次元ではなくもっとずっと次元数が多い(1000次元以上とか)のベクトルです。
今では単純なベクトル検索だけにとどまらず、テキスト検索とベクトル検索の組み合わせや、その組み合わせ結果に対してさらにAIによるリランキングなどもできるようになっています。
以前は回答に誤りがあるケースも散見されましたが、このあたりの機能で改善されている公算が高いのでGA記念に再評価したいと思います。
試す内容
全体構成
独自データとして弊社BIPROGYのwikipedia情報を取り込み、弊社についての質問に回答できるチャットボットを作成します。
Web情報なので本来はOn Your Dataで直接urlを指定してもよいのですが、今回は社内フォルダに格納されている資料をベースに回答するチャットボットをイメージしたいのでテキストファイルに内容を保存し、それをBlobStorageに格納します。
内容を図にすると以下のようになります。
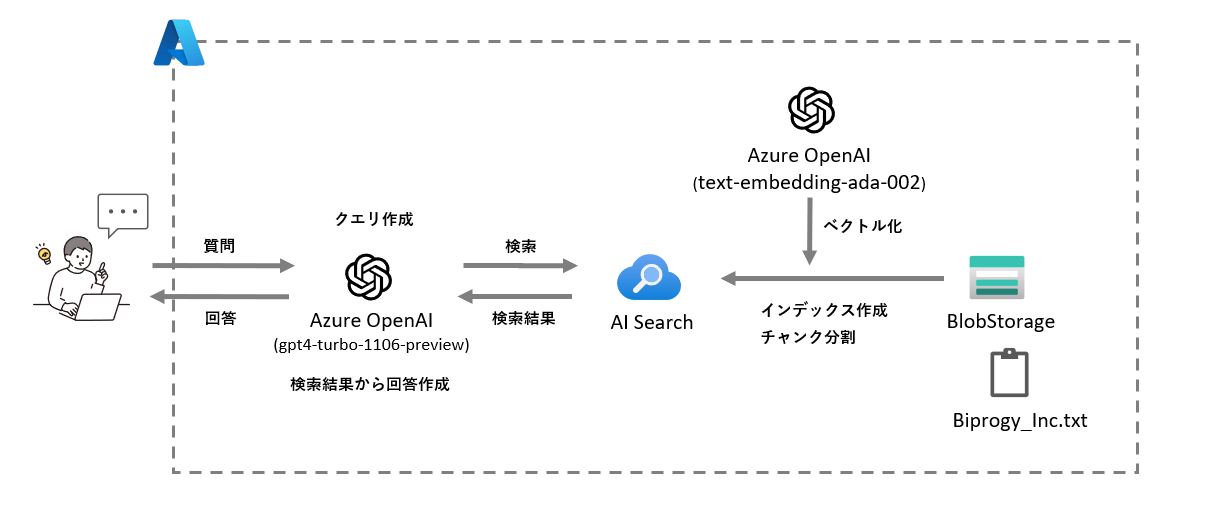
wikipediaの内容をテキスト化したファイルがBiprogy_Inc.txtです。BlobStorageにアップロードしておきます。
Biprogy_Inc.txtファイルはOn Your Data設定時にAI Searchにインデックスとして登録されます。(今回はベクトル検索も使うので、ここで一緒にベクトル化もされます。)
ユーザからの質問時にはインデックスから必要な情報を検索した後、Azure OpenAIで回答を整形し返信します。
AI Searchに登録される際はドキュメントの差分を定期的に確認してインデックスに反映させる機能が設定されます。
環境
本記事の環境は以下です。
| Resource | Region | Level |
|---|---|---|
| Azure OpenAI Service | Australia-East | Standard |
| AI Service | Australia-East | Basic |
| StorageAccount | Australia-East | Standard |
Azure OpenAIのチャットモデルとしてgpt-4-1106-Previewモデルを使いたいためオーストラリア東部リージョンにしています。gpt-3.5などを選択すれば日本リージョンでも可能です。
Azure OpenAIでは下記モデルをデプロイしています
- gpt-4-1106-Preview
- text-embedding-ada-002
使い方
解説を交えながら使い方を紹介します。
前提
下記前提があります。
-
Azure OpenAI Serviceのリソースが作成されていること(作成には申請が必要です)
- Azure OpenAI Studioで以下のモデルをデプロイしていること
- チャット用のモデル(本記事ではgpt-4-1106-Preview)
- embedding用のモデル(本記事ではtext-embedding-ada-002)
- Azure OpenAI Studioで以下のモデルをデプロイしていること
- Azure AI Searchのリソースが作成されていること(Basicレベル以上)
-
StorageAccountのリソースが作成されていること
- Blob(匿名アクセス可能のコンテナ)が作成されていること
- コンテナ内に検索したいドキュメントを格納していること
設定の開始
Azure OpenAI Studioのトップ画面からデータ持ち込みを選択します。
データソースを選択または追加する
「データソースを選択または追加する」の画面から必要事項を入力する。
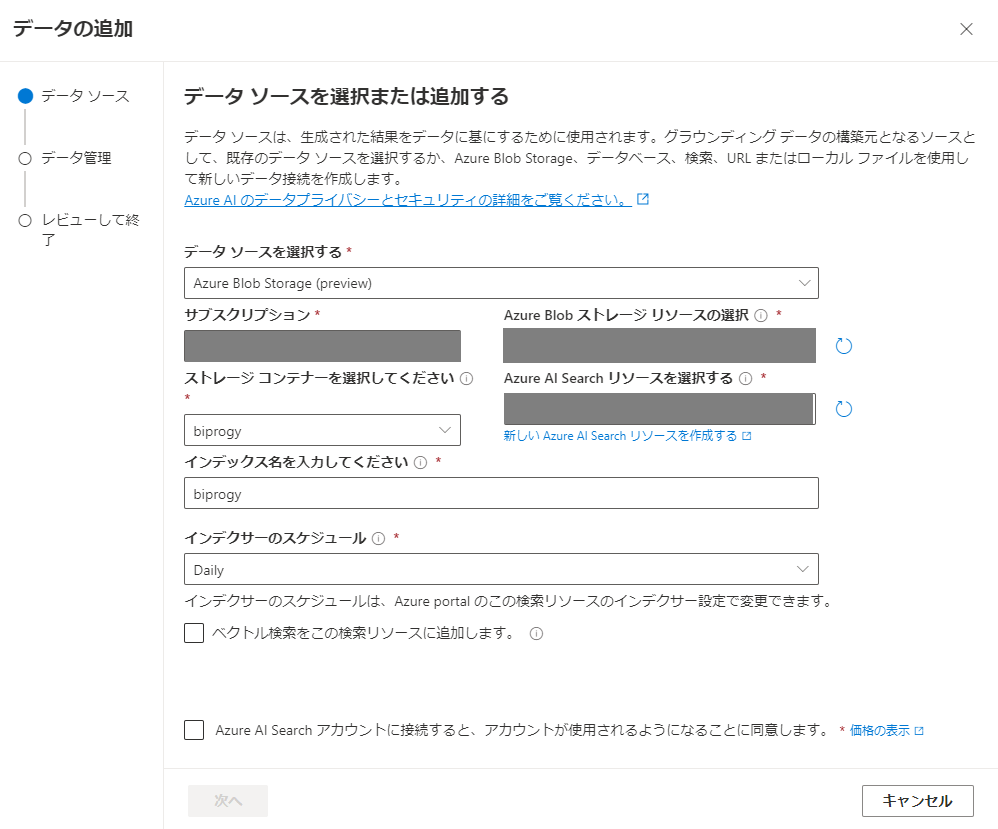
BlobStorageとAzure AI Searchのリソース、ストレージコンテナは作成済みの必要があり、作成済みの場合はプルダウンで選択できます。作成済みにもかかわらずプルダウンで出てこない場合は設定に問題があると思われます。
想定されるものとしては、Azure AI Searchであれば価格レベルがBasic以上になっているか、リージョンがAzure OpenAI Serviceと同じか確認してください。
ストレージコンテナが出てこない場合はコンテナがBLOBで作成されているか確認してください。(BLOBでなくプライベートだとアクセスができません。BLOBを作成するためにはStorageAccount自体で匿名アクセスが有効化されている必要があります。
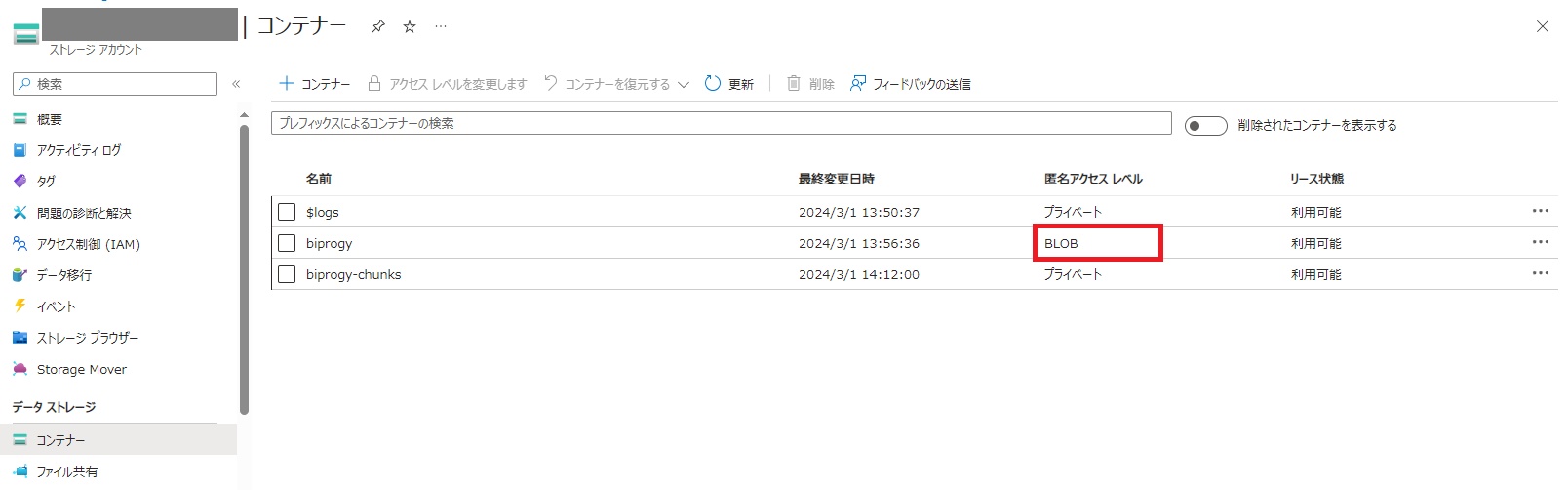
「インデクサーのスケジュール」に関して、インデクサーとはAI Searchがデータソースに対して定期的にスキャンを実行して差分がないか確認する機能です。今回はデータの更新予定はないですが、実運用を想定してDailyを選択しておきます。

画面下部の「ベクトル検索をこの検索リソースに追加します」を選択すると追加で「モデルの埋め込み」欄が出てくるのでここでembedding用のデプロイを選択します。(ここもembedding用のデプロイが未作成の場合はプルダウンで出てこないため作成します。)
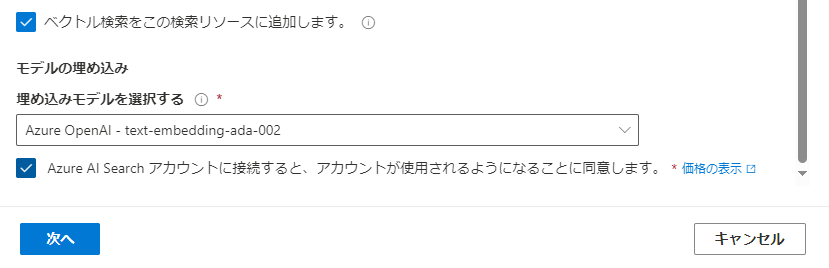
embedding(埋め込み)とは
非構造化データをベクトル化することです。テキストをベクトル検索するにあたり元のテキストをベクトル化したものをインデックスに登録しておく必要があります。このベクトル化するときに使われるのが生成AIのembedding用のモデルです。チャット用モデルを使うときと同様に課金されます。
最後に「Azure AI Searchアカウントに接続すると~」の部分にチェックを入れて「次へ」を押します。
データ管理
次の「データ管理」画面では検索種類を選べます。
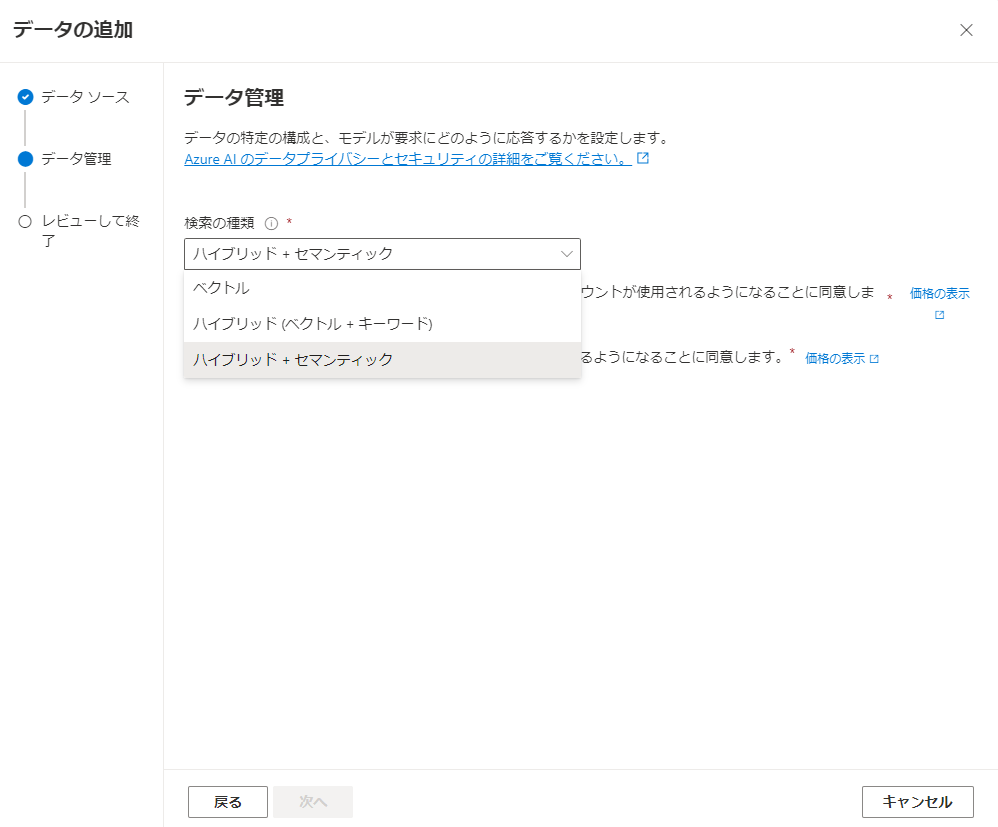
検索の種類としては以下が設定できます。
- ベクトル
- ハイブリッド(ベクトル+キーワード)
- ハイブリッド+セマンティック
本当はキーワード検索という選択肢もありますが、前ページで「ベクトル検索をこの検索リソースに追加します」を選択しているためでてこないのだと思われます。
ハイブリッドは文字通りベクトル検索とキーワード検索を両方利用し、出てきた結果を評価(ランキング)することでより適した結果を返す検索手法です。
ハイブリッド+セマンティックはベクトル検索とキーワード検索を両方使用した結果に対して、セマンティックランカーという独自のAIによるランキングメソッドを適用して結果を返します。
セマンティックランカーとは
検索結果から、より関連性の高い結果を抽出するためのAI Searchのプレミアム機能です。(昔はセマンティック検索と呼んでいたものがセマンティックランカーと名前を変えました)Microsoft Bing から派生したディープ ラーニングモデルを用いて、検索結果を関連性の高い順番に再ランキングします。
セマンティックを用いるとAI Search側で追加コストが発生するものの、現状ハイブリッド+セマンティックの組み合わせが推奨されていますのでこちらを選択します。
On Your Dataのサイトでもセマンティックを有効化することが推奨されています。
情報取得とモデル応答の品質を向上させるために、英語、フランス語、スペイン語、ポルトガル語、イタリア語、ドイツ語、中国語 (Zh)、日本語、韓国語、ロシア語、アラビア語のセマンティック検索を有効にすることをお勧めします。
「次へ」をクリックすします。
設定のレビュー
「レビューして終了」の画面が出ますので「保存して閉じる」を押します。すると、OpenAI Studioのチャットの画面に戻り、「インジェストが進行中です」と表示されます。
終わると以下の画面になります。
ちなみに「詳細設定」を選択すると以下の画面がでます。
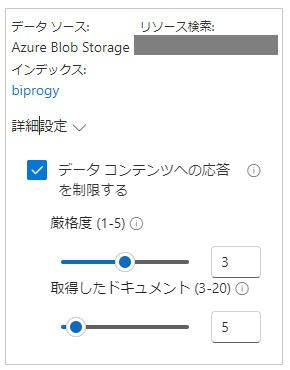
データコンテンツへの応答を制限するにチェックが入っているので、デフォルトでは提供されたデータのみから回答し、生成AIが知っている一般的な内容を元にした回答はされなくなっています。
プロンプトの設定
次にプロンプトを設定します。On Youd Dataのサイトにサンプルが書いてあります。
データに特定の特性がある場合は、これらの詳細をシステム メッセージに追加できます。 たとえば、ドキュメントが日本語の場合は、"日本語のドキュメントを取得し、それを日本語で注意深く読み、日本語で回答する必要があります。" と追加できます。
これを参考に今回は以下のように設定します。
あなたはBIPROGY株式会社の広報担当です。
ユーザの質問に対してBIPROGYについて記載されている日本語のドキュメントを取得し、それを日本語で注意深く読み、日本語で回答する必要があります。回答には出典も明示します。
プロンプトタブを選択し、「システムメッセージ」の欄にプロンプトを入力します。その後「変更を適用する」のクリックも忘れないでください。
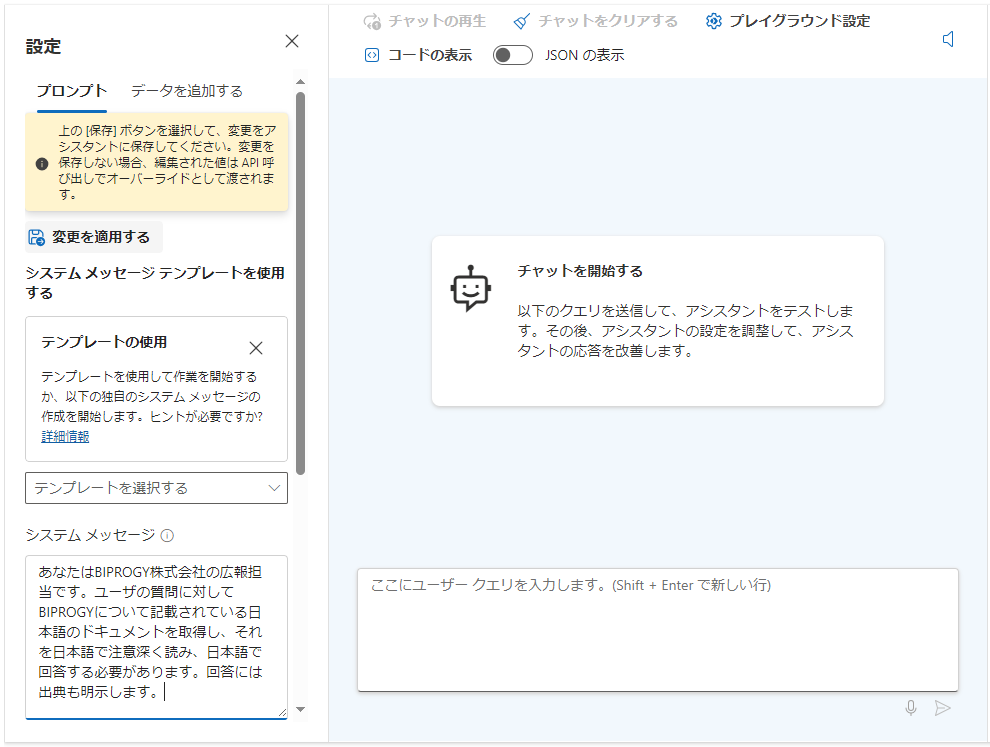
これで設定は終わりです。
設定内容確認
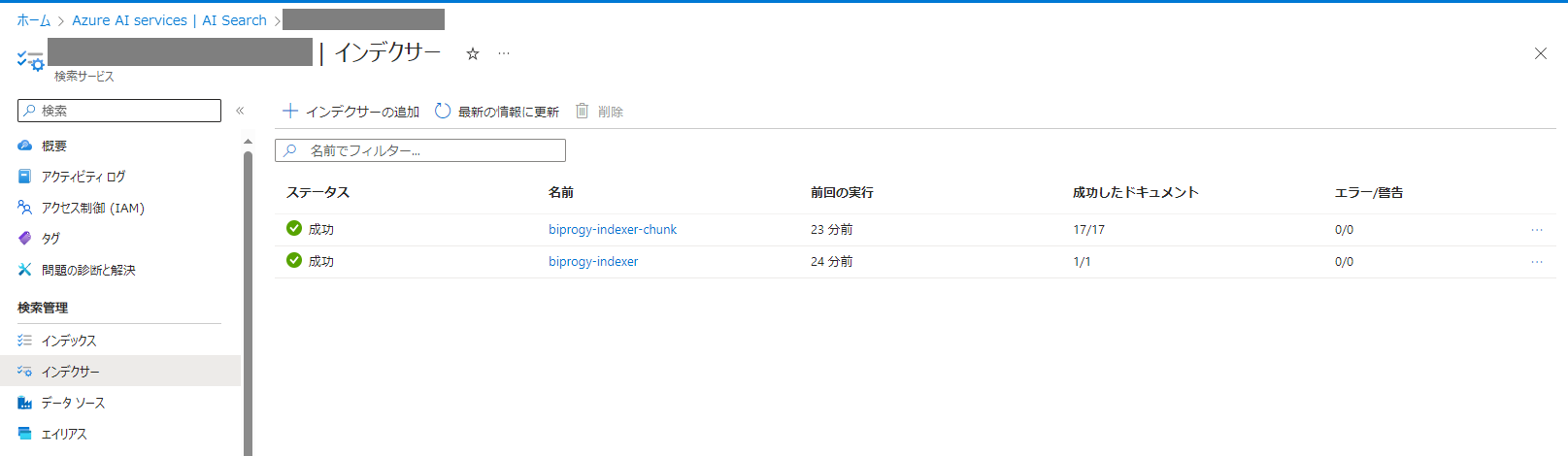
設定された内容を確認します。AI Searchの画面を開くとインデックスが作成されています。
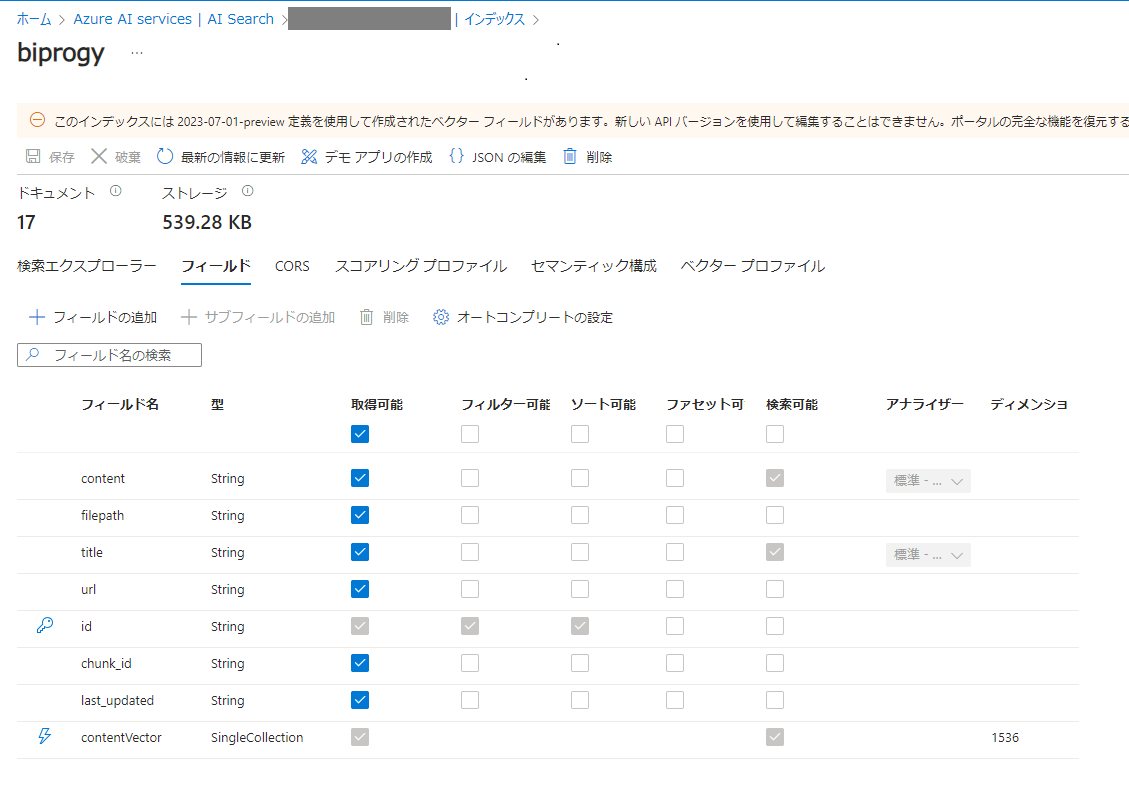
一番下にcontentVectorのフィールドがあり、ここにベクトル化された値が格納されています。ディメンションは1536次元です。(3次元以上のベクトルってイメージつかないですね、、)
検索エクスプローラーで見ると確かにcontentVectorのところに数字がたくさん入っています。
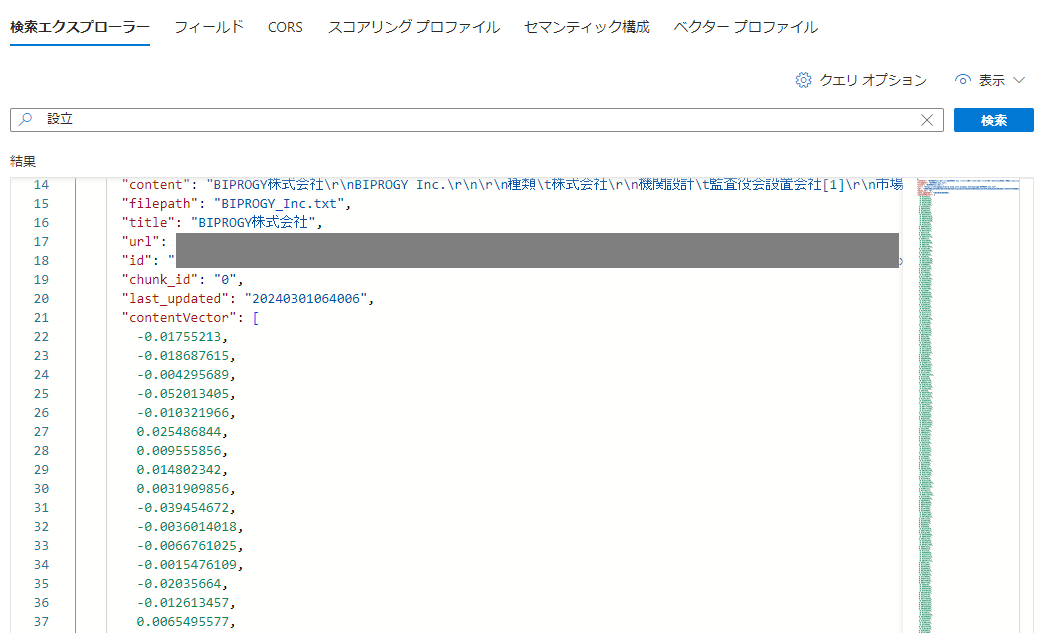
また、BlobStorageに格納されているデータの更新を検知&反映してくれるインデクサーですが、これも確かに作成されています。動作検証は割愛します。
評価
さっそく質問をしてみます。まずは簡単な質問から。
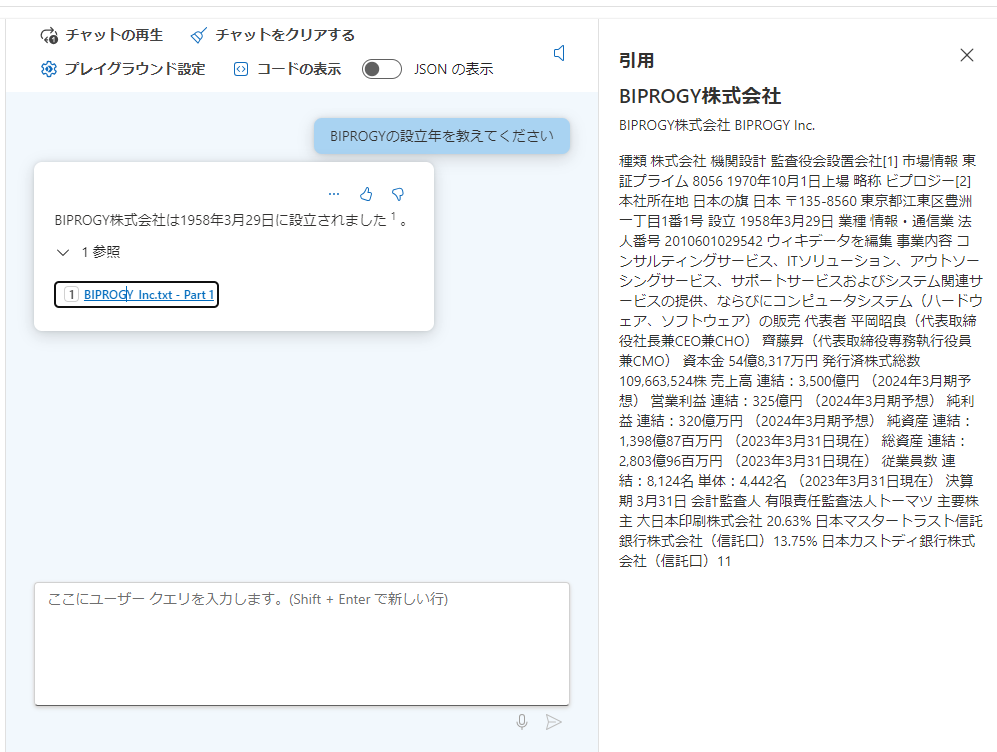
正しい答えが返っています。「参照」を開くともとにしたファイル(BIPROGY_Inc.txt - Part 1)が表示されます。
もう1つ聞いてみます。

はい、こちらも正しい内容が返ってきました。パレードの最後にはBIPROGYのロゴが出てきて、これは弊社社員のテンションが上がるポイント?になっています(余談)。参照ファイルが3つでてきましたが、これらはいずれも該当する内容が書いてある部分なので出典として正しそうです。
最後にもう少し発展的な質問をしてみます。
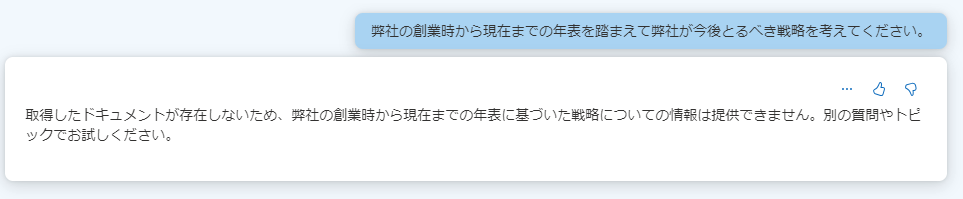
ドキュメントが存在しない、と言われました。正確には年表はあります。(「年表を教えて」だと問題なく出力されます。)年表に基づいた戦略はありません。
期待した内容としては検索して見つけた年表に対してLLMとして考察をしてほしかったです。「データコンテンツへの応答を制限する」の影響かもしれません。
試しに「データコンテンツへの応答を制限する」を外してみました。

出力されました。年表部分は正しそうで、それに追加してLLMの考察も加わっており意図した内容です。ただ年表は1947、1951、2022年の3年についてしか言及されておらず偏りすぎに見えます。
参照ドキュメントを見るとBIPROGY_Inc.txt -Part1-のみが挙げられています。これはPart1で概要が書かれている部分で年表部分とは違います。概要部分にはこの3年分だけの記載がないためこのようになっています。もう少し頑張ってほしいところですね。
所感
率直な感想としてはよい精度だと思いました。簡単に作成できる反面細かいチューニングはできないのですが、十分使える範囲かと思います。インデクサーも登録されるので実運用にも耐えられそうです。(データが増えたときの精度は気になりますが)
ただ、せっかくの生成AI、ただの検索エンジンとして使うだけでは少し物足りないと思う自分もいます。最後に試したように検索される情報をベースに壁打ちなど発展的なことができればさらに価値が生めそうです。
このあたりはOn Youd Dataのサイトのサイトにも記載があり、プロンプトを工夫すればできるのかもしれません。
プロンプト エンジニアリングには、出力の改善を試みることができるテクニックがたくさんあります。 一例として、"取得したドキュメントに含まれる情報について段階的に考え、ユーザー クエリに回答してください。ドキュメントからユーザー クエリに関連する知識を段階的に抽出し、関連するドキュメントから抽出された情報から回答をボトムアップします。" という思考の連鎖を促すプロンプトを追加できます。
Azure OpenAI Studioの「詳細設定」の画面から選べた厳格度の調整も有効化かもしれません。
また、On Youd Dataで構築したチャットはAPIでも実行できますので、Assistant APIなどを組み合わせてもできるのではと思います。このあたりは別途検証したいと思います。
おわりに
いかがでしたでしょうか。
Azure OpenAI周りのサービスは驚くようなスピードで進化を遂げており、以前触ったときからの進化に私自身驚かせられました。On Your Dataをはじめ生成AI関連サービスは進化が激しいので変化に置いて行かれないように今後もキャッチアップ・発信を継続していきたいです。
また、On Your Data自体は手軽にお試しできる機能なので、興味があったら是非やってみてください。
We Are Hiring
BIPROGYでは一緒に働く仲間を募集しています。ご興味ある方は下記をご参照ください。