はじめに
Apexでひらがな・カタカナを相互に変換する方法についての記事です。
全角・半角の変換に比べて記事の検索ヒット数が少なかったので、備忘録も兼ねて投稿しました。
需要が無いだけの可能性も十分ありますが、良かったら使ってください。
目次
1. コード全体
public without sharing class JapaneseCharConverter {
private static final Integer DIFFERENCE_NUM = 96; // ひらがな-カタカナ間のUnicode値の差(以下全て10進数)
private static final Integer START_HIRAGANA_CODE = 12353; // ぁ
private static final Integer END_HIRAGANA_CODE = 12438; // ゖ
private static final Integer START_KATANAKA_CODE = 12449; // ァ
private static final Integer END_KATAKANA_CODE = 12534; // ヶ
public static String convertHiraganaToKatakana(String str){
return execute(str, true);
}
public static String convertKatakanaToHiragana(String str){
return execute(str, false);
}
private static String execute(String str, Boolean isHiraganaToKatakana){
if(String.isBlank(str)){
return '';
}
List<Integer> codePointList = new List<Integer>();
for(Integer i = 0; i < str.length(); i++){
Integer codePoint = str.codePointAt(i);
if(isHiraganaToKatakana){
codePoint += isHiragana(codePoint) ? DIFFERENCE_NUM : 0; // ひらがな → カタカナの場合はUnicode値に96足す
} else {
codePoint -= isKatakana(codePoint) ? DIFFERENCE_NUM : 0; // カタカナ → ひらがなの場合はUnicode値から96引く
}
codePointList.add(codePoint);
}
return String.fromCharArray(codePointList); // 文字コードが入ったリストを元に文字列を生成して返却する
}
private static Boolean isHiragana(Integer codePoint){
return codePoint >= START_HIRAGANA_CODE && codePoint <= END_HIRAGANA_CODE;
}
private static Boolean isKatakana(Integer codePoint){
return codePoint >= START_KATANAKA_CODE && codePoint <= END_KATAKANA_CODE;
}
}
2. 使い方
convertHiraganaToKatakana() / convertKatakanaToHiragana()に、変換したい文字列を渡すだけでOKです。
それぞれひらがな / カタカナの部分だけ変換され、その他は元の文字列のまま返却されます。
String hiragana = "ぁあぃいぅうぇえぉおゃやゅゆょよらりるれろゎわゐゑをん";
String result1 = JapaneseCharConverter.convertHiraganaToKatakana(hiragana);
System.debug(result1);
// "ァアィイゥウェエォオャヤュユョヨラリルレロヮワヰヱヲン"
String katakana = "ァアィイゥウェエォオャヤュユョヨラリルレロヮワヰヱヲン";
String result2 = JapaneseCharConverter.convertKatakanaToHiragana(katakana);
System.debug(result2);
// "ぁあぃいぅうぇえぉおゃやゅゆょよらりるれろゎわゐゑをん"
String mix = "あいうえおカキクケコ亜井兎絵尾abCDe";
String result3 = JapaneseCharConverter.convertHiraganaToKatakana(mix);
System.debug(result3);
// アイウエオカキクケコ亜井兎絵尾abCDe
3. 解説
【Unicodeについて】
前提として、Unicodeを用いてひらがなとカタカナの変換を行なっています。
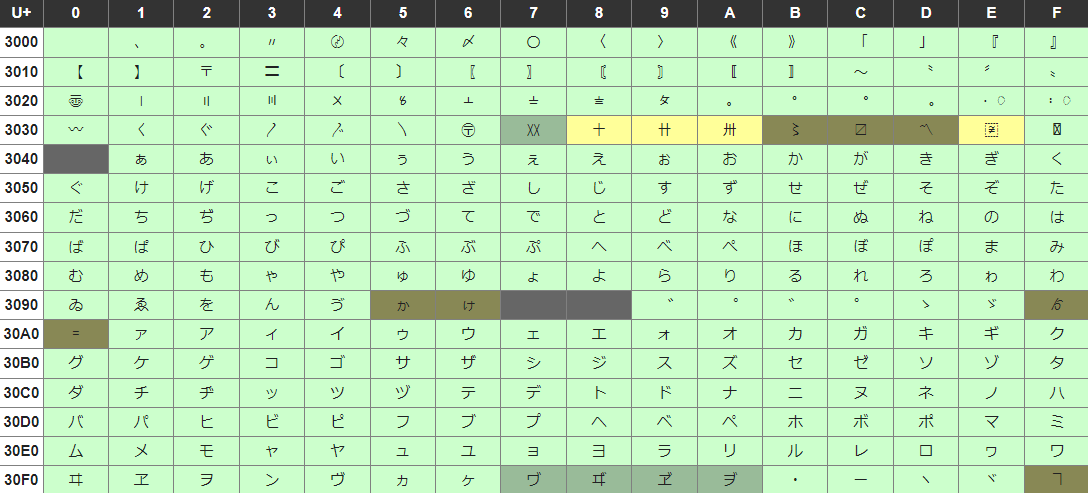
上記の表は、16進数の文字コードを表しています。
「ぁ」と「ァ」から「ゖ」と「ヶ」までが等間隔であることを利用して、文字コードの計算を元に変換が可能となる仕組みです。
isHiragana() / isKatakana()は10進数の文字コードを用いて、変換前の文字コードが、ひらがな / カタカナの範囲に存在するか検証しています。
16進数ではなく10進数を使用している理由は、組み込みのcodePointAt()で返却される文字コードが10進数なのでそのまま使っています。
10進数 → 16進数への変換も可能ではありますが、特に行う必要がないと判断したので、静的変数として定義している値は全て10進数です。
4. おわりに
文字コードを使った変換ではなく、愚直に書き殴ってやろうと思っていた時期もありました。
Map<String, String> charMap = new Map<Stirng, String>{
'ぁ' => 'ァ',
'あ' => 'ア',
'ぃ' => 'イ',
'ぃ' => 'ィ',
// 以下延々と続く
}
でもせっかくなら!という気持ちで、苦手意識のあった文字コードについて調べつつ実装してみました。
文字コードがどんな仕組みになっているのか・Apexではどう扱うのかを学ぶことで、若干ではあるものの苦手意識が薄まったような気がしています。
実装スピードだけなら、愚直に書いた方が確実に早かったでしょうが、しっかり調べて実装することで一歩成長できた感触です。
たまには少し回り道をして、より良い実装方法が無いか模索することは技術者として大事だなと改めて、、、
とにかく、今回はすっきりとしたコードが書けたので満足です!
本記事は以上となります。
ご覧いただきありがとうございました!