はじめに
少し前に、Amazon BedrockにKnowledge baseという機能が追加されました。
最近、LLMを利用したQ&Aシステムを構築する際、検索サービスの検索結果をContextとしてモデルに渡し、回答を生成するというアーキテクチャがよく見られるようになりました。
AWSでは従来Amazon Kendraを利用したアーキテクチャが存在していたのですが、Knowledge baseを利用することでAmazon OpenSearch Serviceなどの検索サービスとAmazon BedrockのLLMを組み合わせたQ&Aシステムを簡単に構築できるようになりました。
なお、現状東京リージョンでは提供されていないので、本稿ではバージニア北部リージョンを利用します。
利用する主なサービス
利用する主なサービスは以下だと思います。(抜け漏れあったらスミマセン)
なお、Knowledge baseを利用すること自体に料金はかからず、料金はそれぞれのサービスの利用料となるようです。
- 検索システム(ベクトルインデックス,以下のうちどれか)
- Amazon OpenSearch Serverless(Quick createの場合はコレ)
- Pinecone
- Redis Enterprise Cloud
- モデル
- Titan Embedding G1
- Embedding処理
- Titan Embedding G1
- 元データ
- S3
ためしてみる
インデックス作成前にS3バケットを作成し、データを配置します。
対応しているデータ形式は以下の通りです。
- Set up your data for ingestion
- txt,md,html,doc/docx,csv,xls/xlsx,pdf
Bedrockのコンソールからアクセスします。
「Orchestration」→ 「Knowledge base」からアクセスします。
サービスが無い場合はバージニア北部でアクセスしているかご確認ください。
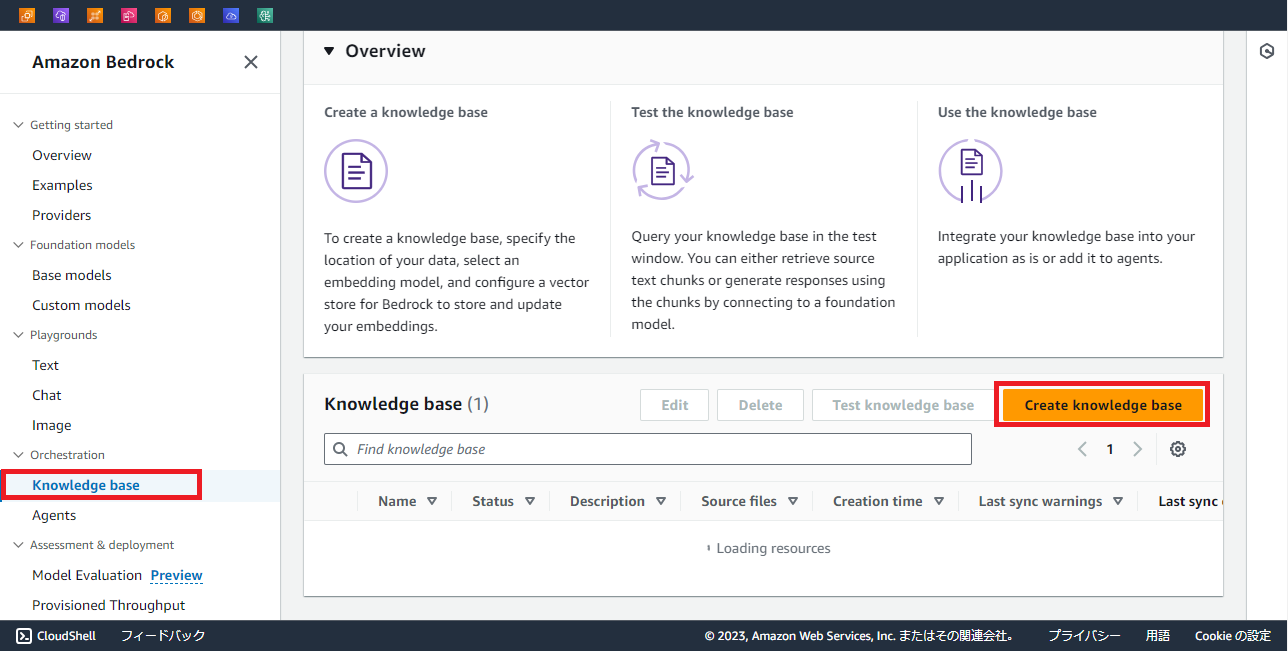
Create Knowledge baseを押下し、作成します。
名前、ロールは全てデフォルトで進めます。
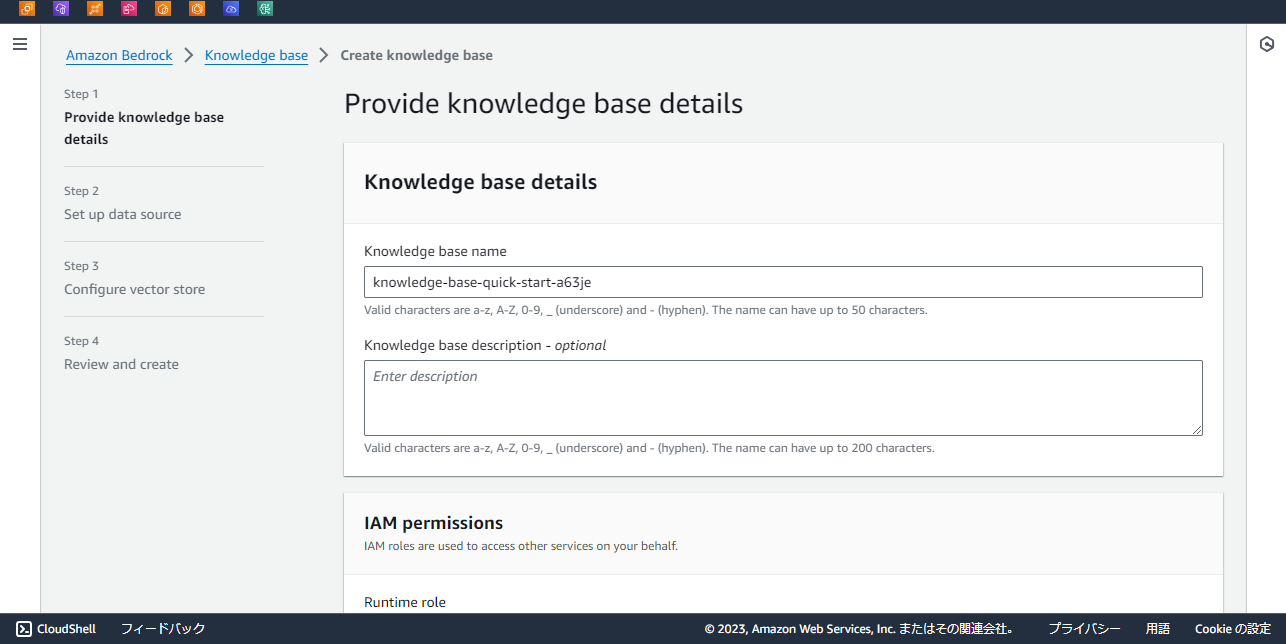
次へを押して、データの設定に移ります。
データを配置しているS3バケットをデータソースに指定します。
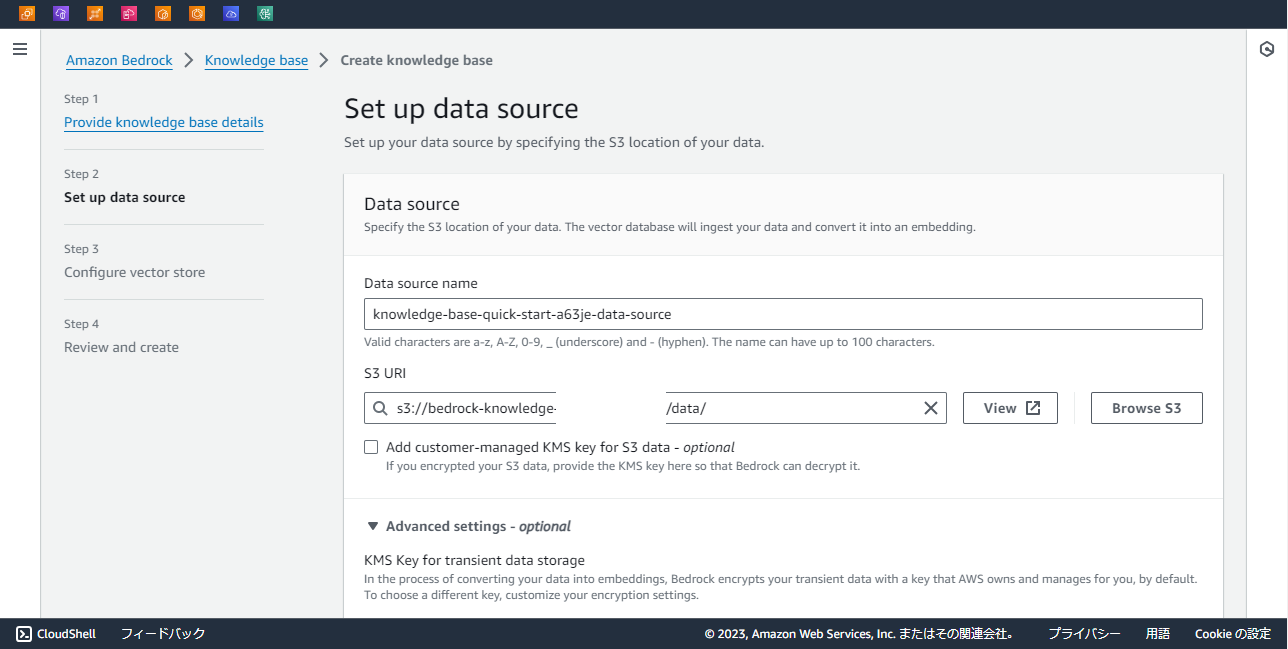
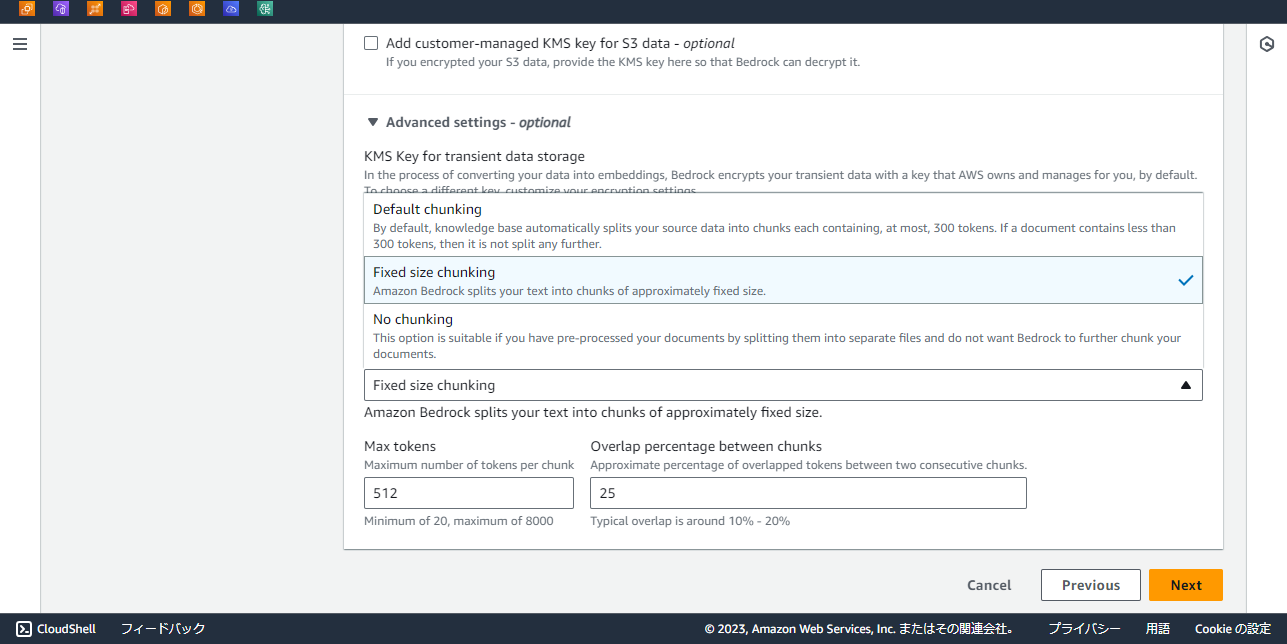
「Advanced settings」では、データの分割についての設定が行えます。
LLMにドキュメントを渡す際、入力トークン数に制限があるので、元データを分割して検索上位のドキュメントを渡すことが一般的かと思いますが、ここではその1ドキュメントのサイズを決めることができます。
デフォルトでは1ドキュメント300トークンですが、せっかくなので512トークンかつ25%分をオーバーラップさせた形で作成します。
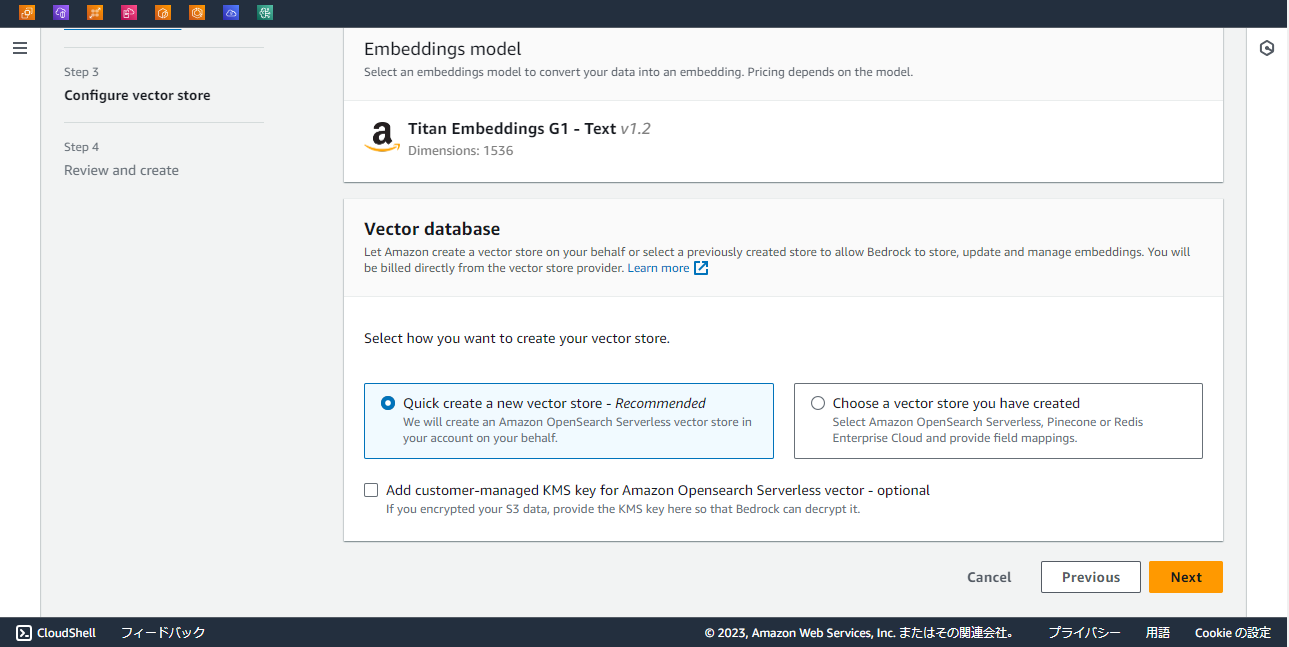
Vector DatabaseではQuick createを利用します。これにより、ベクトルインデックスにOpenSearch Serverlessが利用されます。
最後に確認画面で「Create Knowledge base」を押します。
すると、リソースが作成されます。(完了まで数分かかりました。)
作成が完了したら最後にデータを同期します。
データソースから「Sync」を押します。
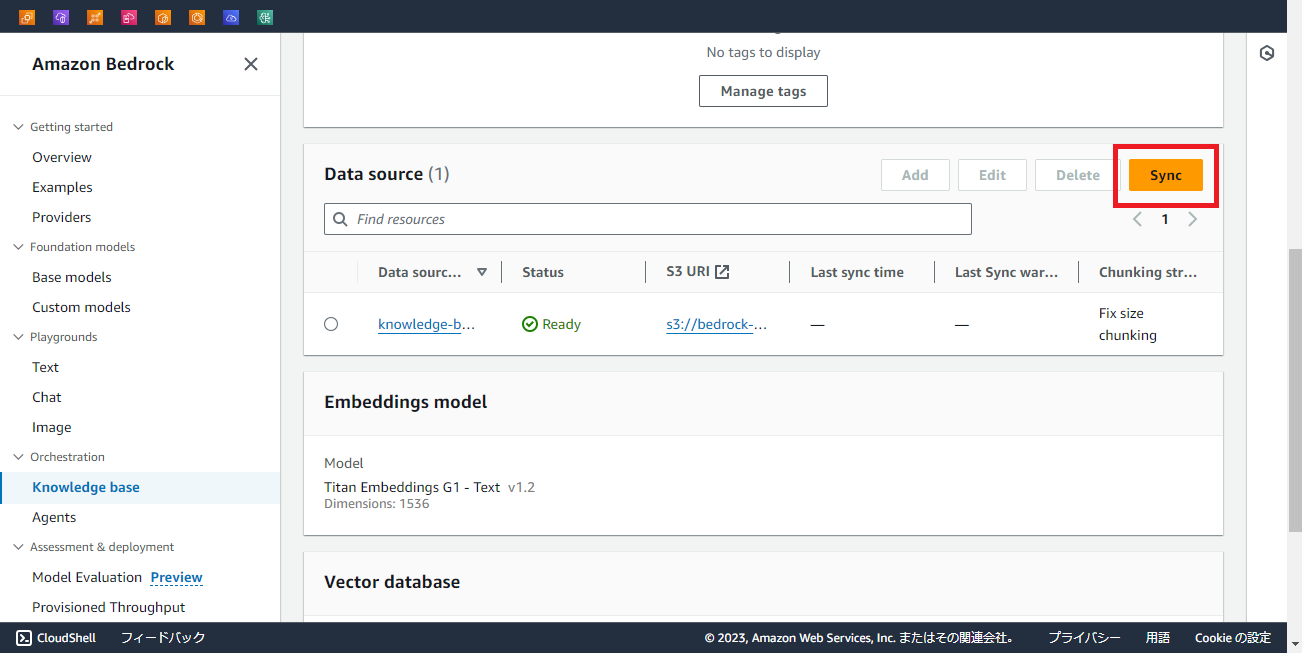
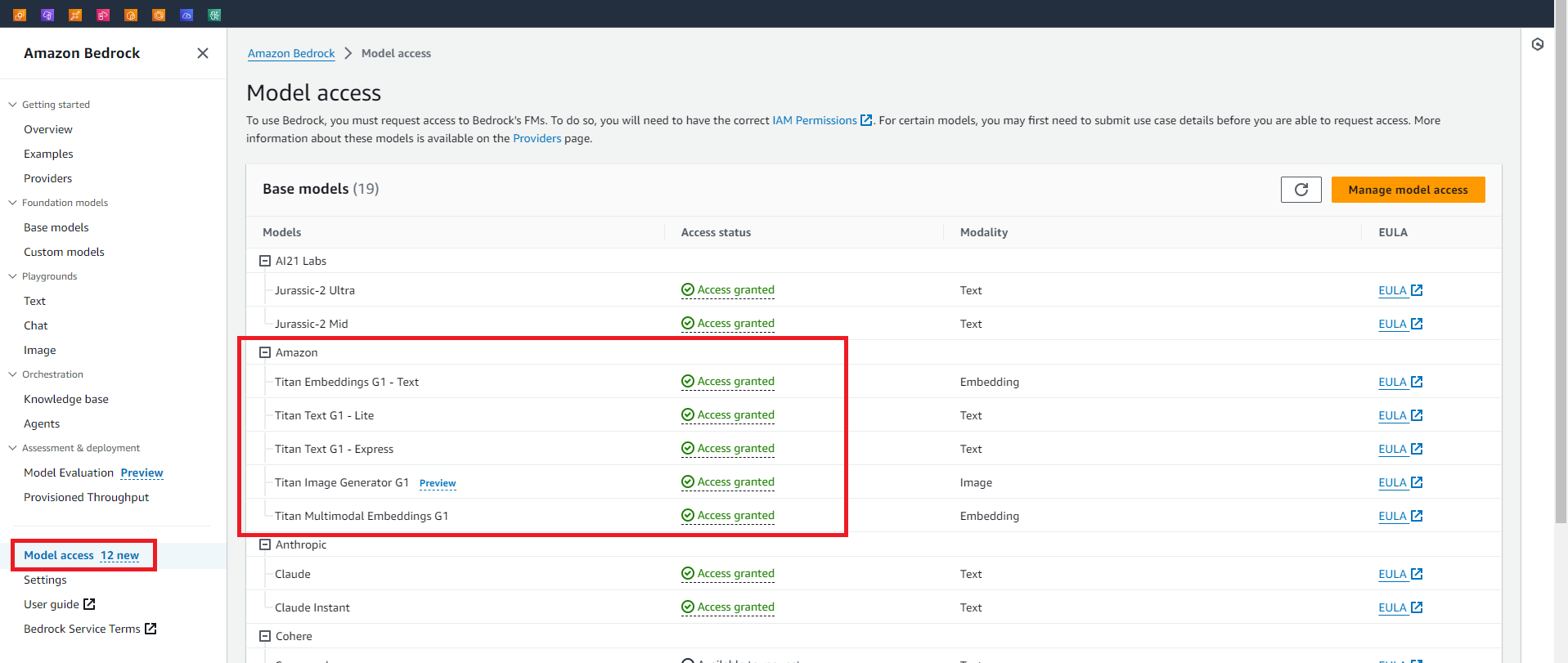
ここでエラーが発生する場合は、Embeddingモデルが有効化されていない可能性があります。
Amazon Bedrockの「Model access」から「Titan Embeddings G1」が有効化されていることを確認してください。
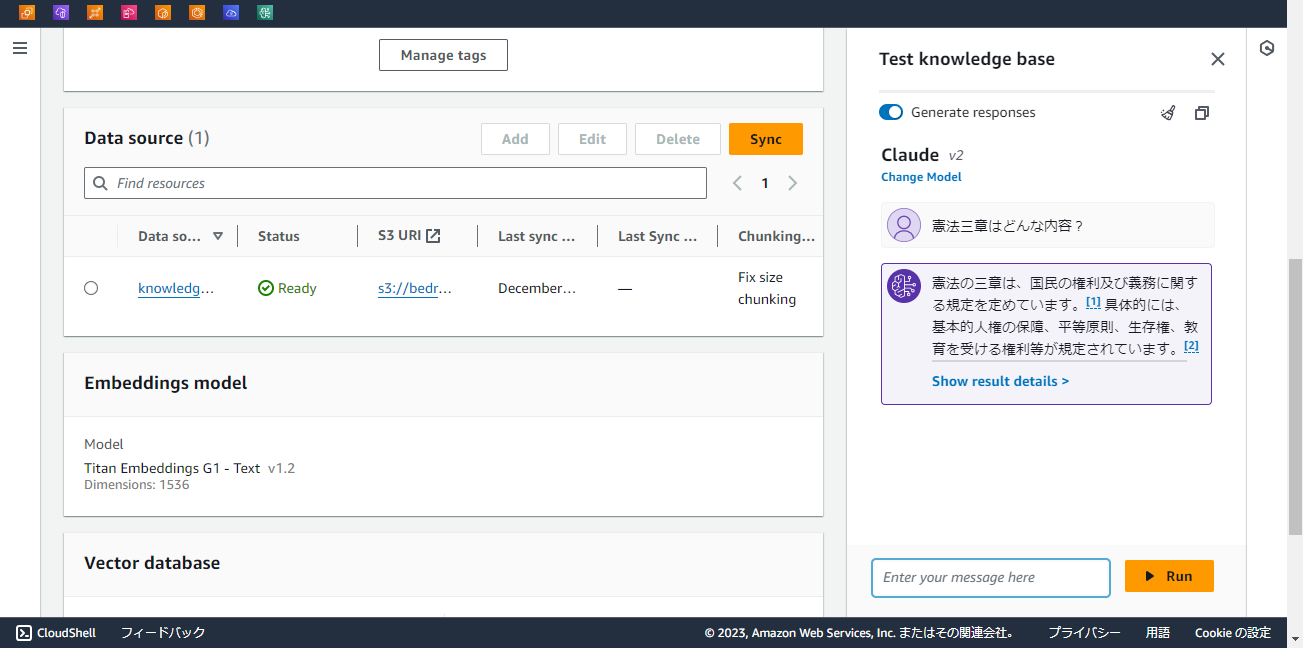
同期が完了するとチャットウィンドウが表示され、ここからテストできます。
LLMにClaude v2を選択し、テストするとドキュメントを参照した回答が表示されました。
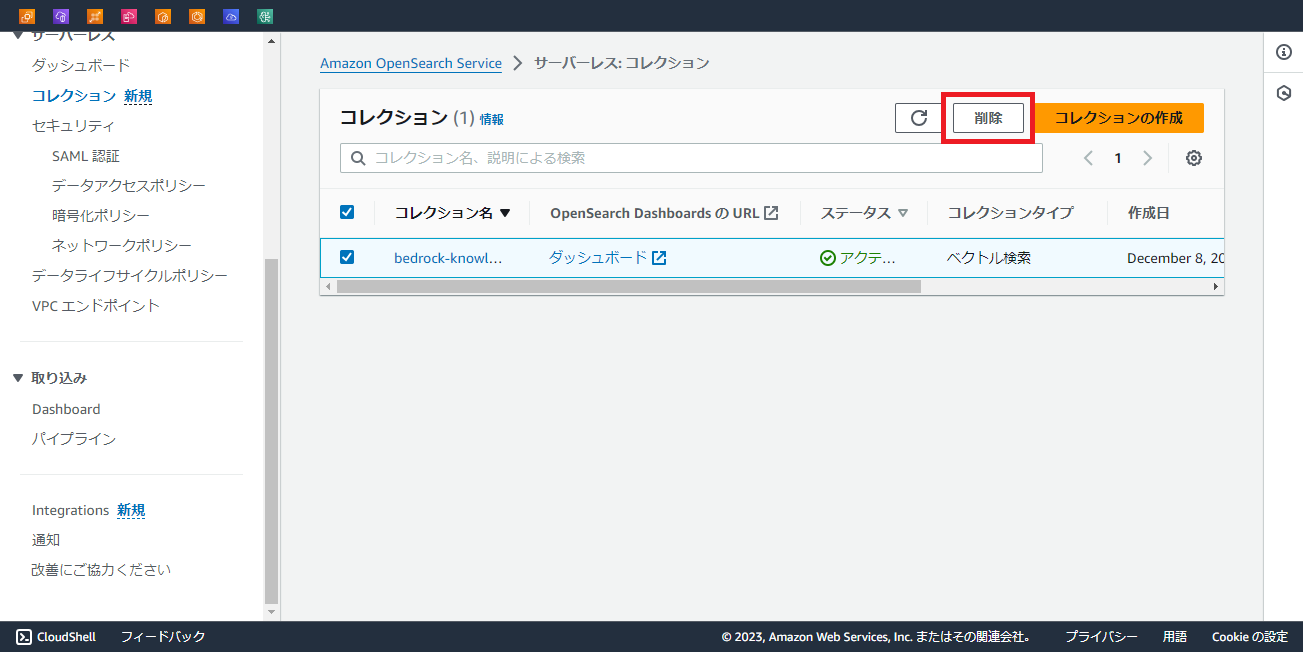
リソースの削除
Knowledge baseを選択し、削除するだけではすべてのリソースは削除できません。
別途OpenSearch Serverlessのコレクションと各ポリシー,S3バケットを削除してください。
おわりに
Amazon BedrockのKnowledge baseを利用することで、簡単に検索サービスとLLMを組み合わせたQ&Aアーキテクチャが構築できました。より検索精度を出したい場合等はベクトルインデックスをカスタム実装することを検討する必要がありますが、ライトに試したい場合はquick createが楽で良いと思います。