Geopandas supports geocoding via a library called geopy, which needs to be installed to use geopandas’ ``geopandas.tools.geocode()
function <https://geopandas.org/en/stable/docs/reference/api/geopandas.tools.geocode.html>__. geocode() expects a list or pandas.Series of addresses (strings) and returns a GeoDataFrame with resolved addresses and point geometries.
Geopandasは geopyライブラリを経由でジオコーディングをサポートします。geopandas.tools.geocode()関数を使います。geopandas.tools.geocode()関数は、文字列のリストもしくはpandas.Series(文字列型)の住所情報を使って、ジオコーディングされた住所(緯度・経度を含む)とそのポイントジオメトリ(Point)を持つ GeoDataFrameを返します。
Let’s try this out.
We will geocode addresses stored in a semicolon-separated text file called addresses.txt. These addresses are located in the Helsinki Region in Southern Finland.
We have an id for each row and an address in the addr column.
ジオコーディングに用いる住所情報は、セミコロン区切りのテキストファイルaddresses.txtから読み込みます。
ファイルはここにあります。colaboratory のカレントディレクトリに、/data/helsinki_addresses/ ディレクトリを作成し、ダウンロードしたファイルを格納します。
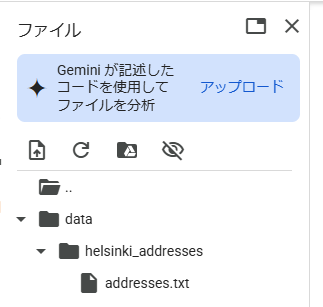

import pathlib
NOTEBOOK_PATH = pathlib.Path().resolve()
DATA_DIRECTORY = NOTEBOOK_PATH / "data"
import pandas
addresses = pandas.read_csv(
DATA_DIRECTORY / "helsinki_addresses" / "addresses.txt",
sep=";"
)
addresses.head()
住所情報は南フィンランドのヘルシンキ地方のものです。id・addr列があり、addr列が住所情報です。
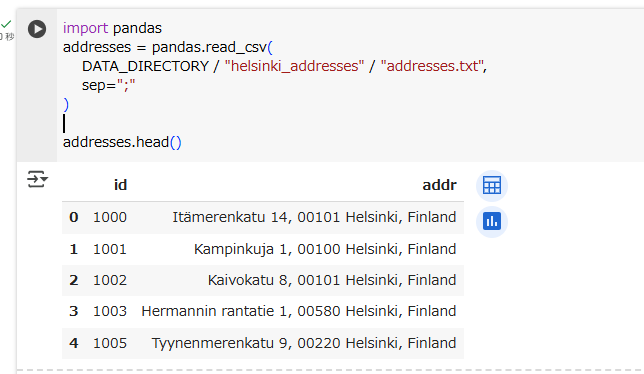
Geocode addresses using Nominatim
In our example, we will use Nominatim as a geocoding provider. Nominatim is a library and service using OpenStreetMap data, and run by the OpenStreetMap Foundation. Geopandas’
geocode() function <hhttps://geopandas.org/en/stable/docs/reference/api/geopandas.tools.geocode.html>__ supports it natively.
ジオコーディングのプロバイダーは、 Nominatim を使います。
Nominatim はOpenStreetMapのデータを使ったライブラリ・サービスであり、OpenStreetMap Foundationによって運営されています。
geopandas.tools.geocode()関数はNominatimに対応しています。
Fair-use
Nominatim’s terms of use require that users of the service ensure they don’t send more frequent requests than one per second and that a custom user-agent string is attached to each query.
Geopandas’ implementation allows us to specify a user_agent, and the library also takes care of respecting Nominatim’s rate limit.
Looking up an address is a quite expensive database operation. This is why the public and free-to-use Nominatim server sometimes takes slightly longer to respond. In this example, we add a parameter timeout=10 to wait up to 10 seconds for a response.
Nominatim の利用規約では、サービスのユーザーが 1 秒に 1 件を超えるリクエストを頻繁に送信しないこと、各クエリに固有のユーザーエージェント文字列が添付されていることを求めています。
Geopandasはユーザーエージェントを特定すること、Nominatimの送信限度(↑のやつ)を守るようになっています。
住所を探す処理はデータベースにとってかなりコストが高いです。なので、パブリックで無料使用できるNominitimサーバーの応答には、時間がかかることがあります。この例では、応答を10秒まで待つパラメータ ’timeout=10’ を追加します。
(補足)Lesson1や2では 最初に! pip install geopandasをしてgeopandasをインストールしていましたが、不要だった(不要になった?)ようです。失礼しました。
import geopandas
geocoded_addresses = geopandas.tools.geocode(
addresses["addr"],
provider="nominatim",
user_agent="autogis2023",
timeout=10
)
geocoded_addresses.head()
Et voilà! As a result we received a GeoDataFrame that contains a parsed version of our original addresses and a geometry column of shapely.geometry.Points that we can use, for instance, to export the data to a geospatial data format.
Et voilà!(フランス語で「はい、どうぞ」)
住所情報とshapely.geometry.Point型のgeometryの列からなるGeoDataFrameができました。
こんなかんじで、 データを地理空間データ形式にエクスポートする目的で使用できます。
(補足)私の環境では、処理が終わるまで数秒かかりました。
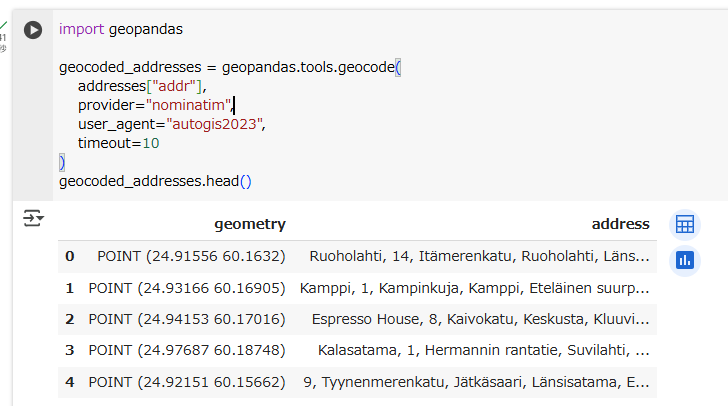
However, the id column was discarded in the process. To combine the input data set with our result set, we can use pandas’ join operations.
しかし、id列がいなくなってしまいました。そこで、入力データセットと結果セットを結合するために、pandasのjoin操作を使います。
Join data frames
Joining data from two or more data frames or tables is a common task in many (spatial) data analysis workflows. As you might remember from our earlier lessons, combining data from different tables based on common key attribute can be done easily in pandas/geopandas using the
merge() function <https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.merge.html>__. We used this approach in exercise 6 of the Geo-Python course.
複数のデータフレームやテーブルを結合することは、空間処理に限らず、データ分析をするうえで普通にあることです。pandasのmerge()関数で簡単に実現できます。
However, sometimes it is useful to join two data frames together based on their index. The data frames have to have the same number of records and share the same index (simply put, they should have the same order of rows).
We can use this approach, here, to join information from the original data frame addresses to the geocoded addresses geocoded_addresses, row by row. The join() function, by default, joins two data frames based on their index. This works correctly for our example, as the order of the two data frames is identical.
ただ、行数とインデックスが一致していれば、インデックスをベースに結合することもできます。
join()関数は、インデックスに基づいて2つのDataFrameを結合します。今回の場合、2つのDataFrameの順序は同じなので、問題ありません。
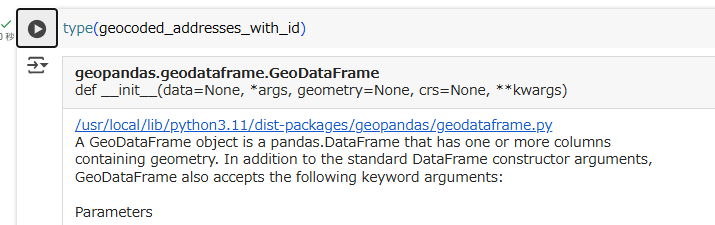
geocoded_addresses_with_id = geocoded_addresses.join(addresses)
geocoded_addresses_with_id


(脱線)プロダクションコードの場合は、何らかの理由によりこの条件(行数とインデックスが一致)を満たせないことにより、期待する結果にならない(=バグになる)ことがありえます。なので、基本はmerge()を使うほうがいいかなと思います。テストコード?テストコードは、まあどっちでも(暴論)
The output of join() is a new geopandas.GeoDataFrame:
The new data frame has all original columns plus new columns for the geometry and for a parsed address that can be used to spot-check the results.
join()関数の戻り値は新しいgeopandas.GeoDataFrameとなります。
新しいGeoDataFrameは元のGeoDataFrameのすべての列に加えて、geometryとパースされた住所情報の新しい列を持ち、抜き取り検査(spot-check)で使うことができます。
It’s now easy to save the new data set as a geospatial file, for instance, in GeoPackage format:
地理空間ファイルとして保存することは簡単です。たとえば、GeoPackageフォーマットの場合です。
geocoded_addresses.to_file(DATA_DIRECTORY / "addresses.gpkg")
ちょっと脱線します。せっかくなので、geocoded_addresses_with_idをplotしてみます。
geocoded_addresses_with_id.plot()
・・・。
今のところはよくわかりませんね。
Understanding the difference between join and merge in GeoPandas
GeoPandasにおけるjoinとmergeの違い
GeoPandas provides both join and merge functions, and while they may seem similar, they are used differently depending on the context.
似ているように見えるが、文脈によって違う使われ方をします。
join:
- This is primarily used for joining GeoDataFrames with a shared index. It works similarly to a SQL join based on the index of the two tables.
- It is ideal for adding columns from one GeoDataFrame to another based on the index or a pre-aligned structure.
merge:
- merge allows more flexibility by enabling joins based on specific columns, not just the index. It works similarly to pd.merge in pandas.
- It is useful for spatial joins when you want to match features based on attribute values in specific columns rather than just the index.
joinはインデックスを共有している GeoDataFrameの結合で使用されます。ある GeoDataFrameから別の GeoDataFrameに列を追加する場合が理想的な使い方です。
一方、mergeはpandasのpd.merge()と同じく、インデックスだけでなく、特定の列による結合ができます。特定の属性値に基づいて特徴(feature)を一致させる、空間結合で使用します。
import geopandas as gpd
# Sample GeoDataFrames
gdf1 = gpd.GeoDataFrame({
'ID': [1, 2, 3],
'Name': ['Park', 'Lake', 'Forest'],
'geometry': gpd.points_from_xy([10, 20, 30], [10, 20, 30])
})
gdf2 = gpd.GeoDataFrame({
'ID': [1, 2, 3],
'Area_km2': [1.5, 2.1, 3.3]
})
# Using `join` - joins based on index
joined = gdf1.set_index('ID').join(gdf2.set_index('ID')) # IDをインデックスに変換して、インデックスをキーにして結合
print("Using `join`:\n", joined)
print("\n")
# Using `merge` - joins based on a column
merged = gdf1.merge(gdf2, on='ID') # ID列をキーにして結合
print("Using `merge`:\n", merged)
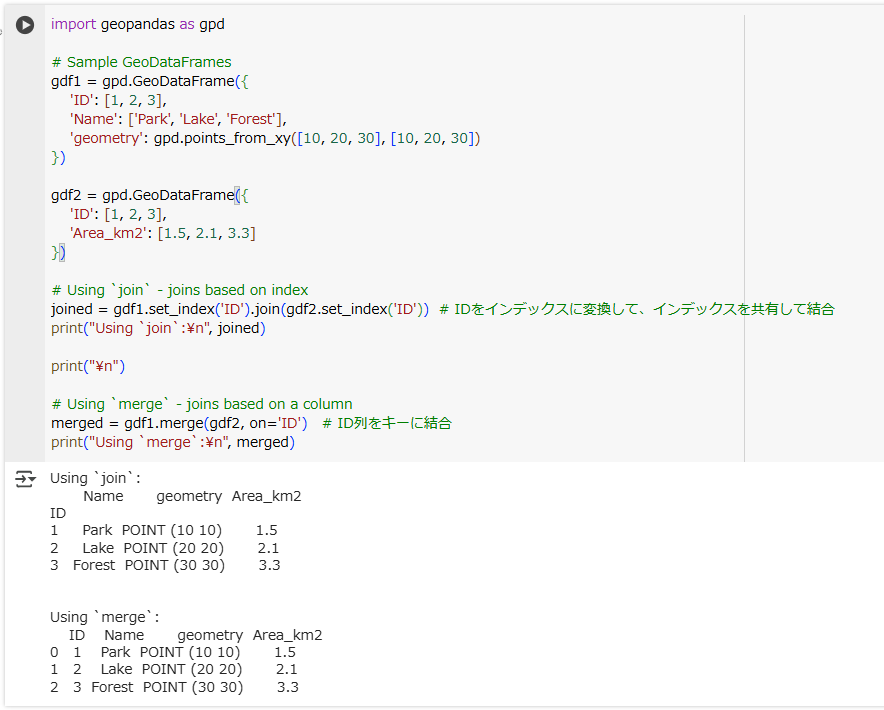
ぱっと見だと結果の違いが分かりにくいですが、列とインデックスに違いがあります。
join()の場合は、IDが列ではなくインデックスです。set_index()したからです。
