はじめに
クリスマスに雪が降るというのは幻想的なものですが、東京に住んでいるとなかなかそう上手い具合に雪は降りません。
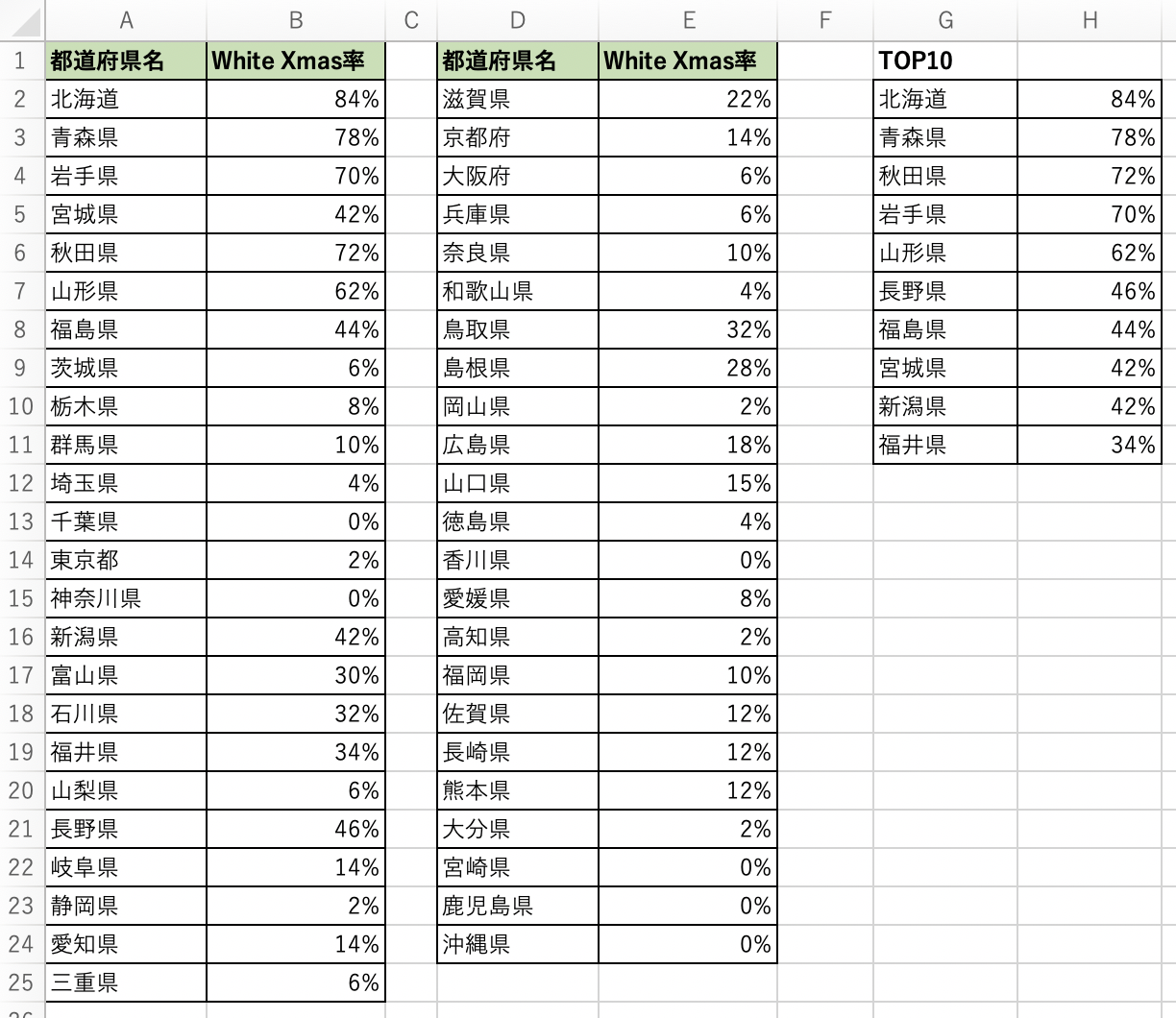
しかし、北海道なら?東北なら?・・・ということで、過去50年間の都道府県別の天気データを用いて、**「都道府県別ホワイトクリスマス率」**を求めてみます。
また、その結果を日本地図にプロットしてみます。
この記事で学べること
- データ分析の進め方、考え方
- データクレンジングのためのDataFrame操作
- japanmapによる日本地図の描画
etc...
環境
- Python 3.7.4
- Anaconda 4.8.3
- Jupyter notebook
分析
前提条件
今回の検証では、ホワイトクリスマスを12/24 or 25の夜に、一時的にでも雪が降った日、と定義します。
また、1つの県に天気の観測地点は複数ありますが、基本的に県庁所在地の情報を用いるものとします。
ただし、観測地点が県庁所在地に存在しない場合はその限りではありません。
(調べた結果、埼玉県と滋賀県が該当しましたので、それぞれ熊谷、彦根の情報を用いました。)
データ収集
過去の天気データは、下記の気象庁のHPから拝借します。
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
選択地点は上記の通り47箇所選びます。
項目は「天気概況(夜:18時~翌日06時)」、期間は「12月24日から12月25日までの日別値を1970年から2019年まで表示」として、CSVをダウンロードしてきました。
また、上部の余計な行はExcel上で排除しておき、以下のような形式に整形しておきます。
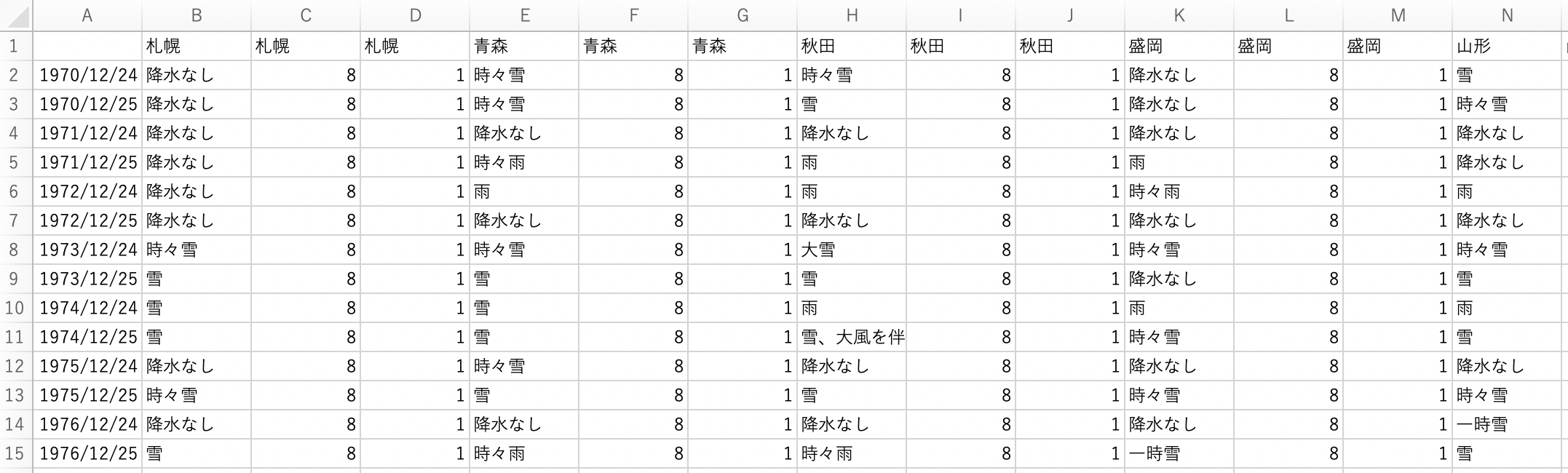
ファイル名はXmas.csvとしました。
ホワイトクリスマス率の計算
それでは、先ほどのデータを加工してホワイトクリスマス率を計算していきます。
まずはCSV読み込みから。
import pandas as pd
from datetime import datetime
df_xmas_master = pd.read_csv("Xmas.csv", encoding="shift_jis", index_col="Unnamed: 0", parse_dates=True)
まずは、csvから、「8」「1」だけ並んでいる余計な行を消します。
これは、以下のように行を2つ置きに選択していけばOKです。
df_xmas = df_xmas_master.iloc[:,::3]
その後、天候に「雪」が含まれるセルをTrue、含まれないセルをFalseに置換します。
for i in df_xmas.columns:
df_xmas[i] = df_xmas[i].str.contains("雪")
すると、データフレームが以下のようになりました。

ここまで来れば、あとは集計すれば良さそうです。
df_white_rate = df_xmas.resample("Y").max().mean()
df_white_rate = df_white_rate.to_frame().reset_index()
df_white_rate.columns = ["県庁所在地","White Xmas率"]
True = 1、False = 0であることを考えると、年別に集計しその最大値を計算するようにしておけば、12/24 or 12/25の天気に「雪」が1つでも含まれていたら1、いずれにも「雪」が含まれていなければ0という計算になります。
その上でmean()をすれば、年ごとに雪が降った割合が分かります。
(もし天気が取得されていない=NaNが含まれていれば、計算から省かれます。)
ちなみにソースコードの下の2行は、mean()をすると形式がSeries型になってしまうので、今後扱いやすくするためにデータフレーム形式に直し、新たに列名を定義しただけです。
この処理により、df_white_rateは以下のようになります。
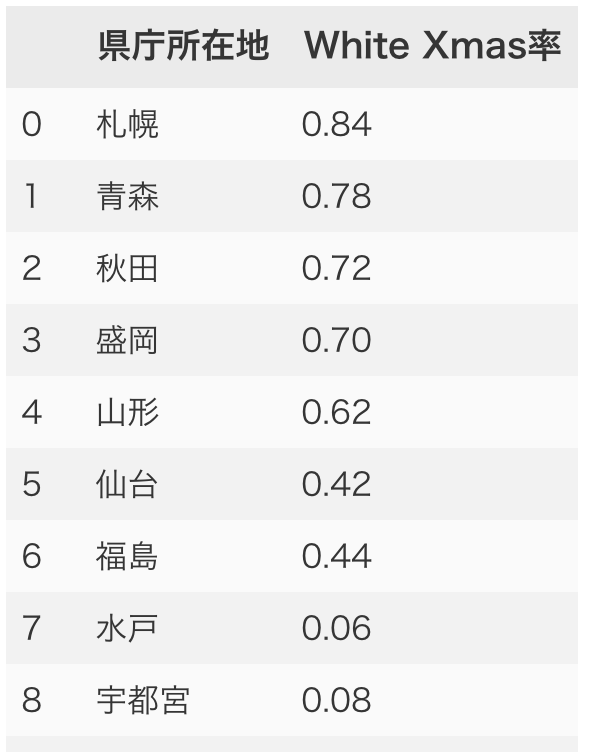
既に、年別のホワイトクリスマス率は計算できましたね。
それでは、ここからはこの結果を日本地図に良い感じにマッピングしていきましょう。
都道府県別ホワイトクリスマス率データフレームの作成
さて、日本地図に結果を図示していく訳ですが、これにはjapanmapという便利なライブラリを使います。
これは**「都道府県名」と「色」の一覧をSeries型で与えるだけで、カラーリングされた日本地図が得られる優れ物**です。
が、ここで問題が。
先ほど作成したデータフレームは「都道府県名」でなく「県庁所在地名」です。
県庁所在地名と都道府県名を紐付けなくてはなりません。
という事で、都道府県名-県庁所在地名テーブルを以下のサイトより拝借します。
ソースは以下。
df_center_master = pd.read_html("https://sites.google.com/site/auroralrays/hayamihyou/kenchoushozaichi")
df_center = df_center_master[2].iloc[2:,1:]
df_center[2] = df_center[2].str[:-1]
df_center = df_center.reset_index().iloc[:,1:]
df_center.columns = ["都道府県","県庁所在地"]
df_center.iloc[10]["県庁所在地"] = "熊谷"
df_center.iloc[12]["県庁所在地"] = "東京"
df_center.iloc[24]["県庁所在地"] = "彦根"
先ほどのサイトには県庁所在地名の後ろに「市」が付いているので、先ほど作成したWhite Xmasデータフレームの形式と合わせるために削除しました。
また、東京の県庁所在地が「新宿」となっていたため、「東京」に合わせます。
そして今回、埼玉県は「熊谷」、滋賀県は「彦根」と県庁所在地でないデータを取得しているので、そこも変えておきます。
こうして出来たデータフレームdf_centerは以下。

このデータフレームと、先ほど作成したWhite Xmasのデータフレームを結合すれば良さそうです。
df_all = pd.merge(df_center,df_white_rate,on="県庁所在地")
df_all = df_all[["都道府県","White Xmas率"]]
df_allを確認すると。。。

無事に都道府県名-White Xmas率データフレームが完成したようです。
White Xmas率を色に変換
続いては、数値をどうにかして色に変えていきます。
色合いは何でも良いのですが、ホワイトクリスマス率が高いほど白に近く、低いほど緑に近い、となるようにしてみましょう。
これをカラーコードで言うと、ホワイトクリスマス率が高いと#ffffffに近づき、低いと#00ff00に近づく・・・と言い換えられます。
カラーコードは頭の2桁が「赤色の強さ256段階を16進数に変換したもの」、中2桁が「緑色の強さ256段階を16進数に変換したもの」、下2桁が「青色の強さ256段階を16進数に変換したもの」です。10進数で言う0〜255が16進数では00〜ffとなるので、必ず2桁で収まります。
ということで、数字を緑色の強さに変換する関数を作ります。
def num2color(x):
color_code = "#" + format(round(x*255),"#04x")[2:] + "ff" + format(round(x*255),"#04x")[2:]
return color_code
今、数字は0〜1の範囲なので、これを255倍して0〜255の範囲に変えます。それを四捨五入し、2桁の16進数に置き換えるという処理になっています。
緑色の強さはそのままにして、赤色と青色の強さのみ調整することによって、「白〜緑」のカラー調整ができます。
それでは、この関数を使って都道府県名-カラーコード一覧を作りましょう。
df_all = df_all.set_index("都道府県")
df_all = df_all["White Xmas率"].apply(num2color)
さて、df_allはどうなったでしょうか。

都道府県名-カラーコードの一覧が出来上がったみたいです。
日本地図へのマッピング
いよいよ日本地図にマッピングしていきます。
これはmatplotlibとjapanmapを読み込み、japanmapメソッドにdf_allを与えるだけです。
import matplotlib.pyplot as plt
from japanmap import picture
fig = plt.subplots(figsize=(10,10))
plt.imshow(picture(df_all))
さて、結果は・・・
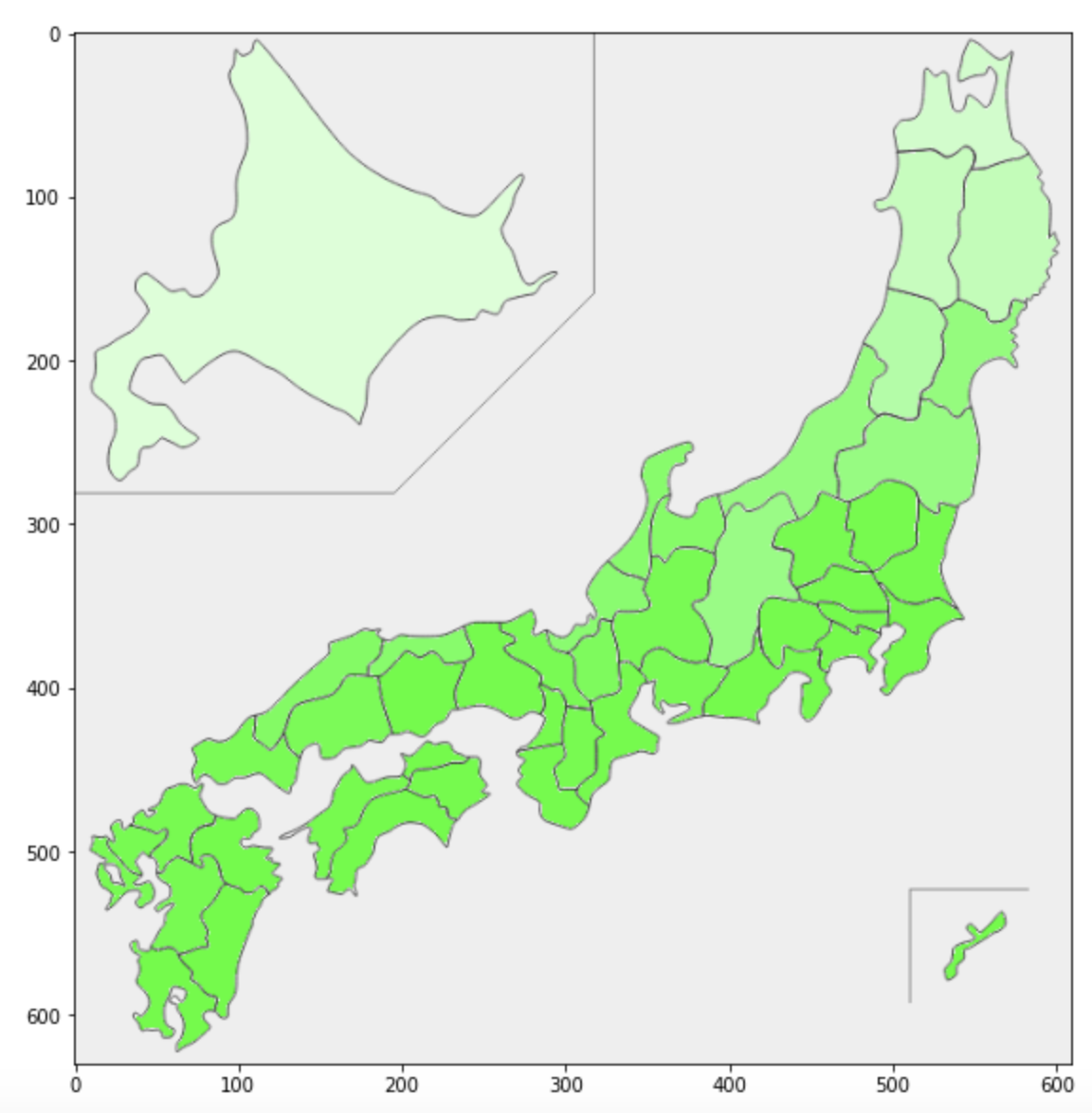
これで、都道府県別ホワイトクリスマス率のマップが完成しました。
いまいちカラー設定が良くないかもしれませんが、ここはセンスの問題もあるのでご愛敬を...
おわりに
以上、Pythonで、ホワイトクリスマス率のマッピングをやっていきました。
是非、この記事を通してデータ分析の方針や可視化の方法など、ご参考になれば幸いです。
最後に、図だといまいちホワイトクリスマス率が分かりづらかったので、都道府県別の、過去50年間のホワイトクリスマス率の割合を貼って終わりにします。(可視化した意味...)