はじめに
夏目漱石、芥川龍之介、川端康成、太宰治、三島由紀夫・・・
これら日本を代表する作家たちが、小説に最も使用した単語は一体何なのでしょうか?
今回は名詞・動詞・形容詞それぞれについて、Pythonを使って分析してみました。
この記事で学べること
- テキストマイニングの進め方、考え方
- Pythonによるスクレイピング
- MeCabによる形態素解析
- Seabornによるグラフの描画
etc...
環境
- Python 3.7.4
- Anaconda 4.8.3
- Jupyter notebook
分析
それでは、早速分析していきましょう。
データ集め
今回使用する文章データは「青空文庫」様より拝借します。
まずは一例として夏目漱石のデータを取得してみます。
夏目漱石の作品一覧は以下のURLに収められています。
このURLの「148」が夏目漱石の作家IDとなります。
つまり、このIDの部分を変えれば、任意の作家のデータを収集する事ができます。
そして、このページに夏目漱石の作品一覧と、それらの作品IDが掲載されているようです。
例えば「草枕」であれば作品IDは「776」です。
この作品番号が分かると、青空文庫APIを用いて以下のURLにアクセスすれば、本文をhtmlで取得できます。
つまりは、夏目漱石のページから持って来た「作品ID」一覧を、このURLの「776」の部分にどんどん入れていけば、青空文庫に収められている夏目漱石の作品データを全て取得できることになります。
では、やっていきます。
from bs4 import BeautifulSoup
import requests
res = requests.get("https://www.aozora.gr.jp/index_pages/person148.html")
soup = BeautifulSoup(res.content,"html.parser")
ol_data = soup.find("ol").text
まずは夏目漱石のページにアクセスして、作品ID一覧をリスト形式で取得しています。
ソースを確認した所、作品名はolタグで箇条書きされていたので、上記URLのolタグ内の記述を全て引っ張って来ました。
ol_dataの中身はこんな感じです。
'\nイズムの功過\u3000(新字新仮名、作品ID:2314)\u3000\n一夜\u3000(新字新仮名、作品ID:1086)\u3000\n永日小品\u3000(新字新仮名、作品ID:758)...
...ここで、改めて作品一覧を見ると、同じ作品の旧仮名遣いバージョンなども収録されている事が分かりました。
"新字新仮名"と"新字旧仮名"と"旧字旧仮名"が別に収録されている場合があるんですね。
これを全て含めてしまうと、同じ作品の単語がダブルカウントされてしまうので、今回は**"新字新仮名"である作品のみ**に絞ります。
import re
id_list = re.findall("新字新仮名、作品ID:[0-9]+",ol_data)
id_list = [i.split(":")[1] for i in id_list]
ということで正規表現を用いて、ol_dataの中から「新字新仮名、作品ID:<数字>」という部分をlist形式で抽出します。
そしてsplitメソッドにて「:」で分割した後の文字列を、リスト内包表記を用いてlist化しています。
すると、id_listは
['2314',
'1086',
'758',
'2669',
'59017',
'792',...
...となりました。
無事に作品ID一覧が取得できたようです。
さて、それでは青空文庫APIのURLにこのIDを突っ込んでいき、各ページをスクレイピングしていきます。
import pandas as pd
import time
def get_text(id_num):
time.sleep(1)
res = requests.get("http://pubserver2.herokuapp.com/api/v0.1/books/"+ str(id_num) +"/content?format=html")
soup = BeautifulSoup(res.content,"html.parser")
title = soup.find("title").text
doc = soup.find("div",{"class":"main_text"}).text
return title,doc
get_textは、作品IDを与えると、その作品のタイトル名と本文テキストを返してくれる関数です。
html中のtitleタグに作品名、divタグのmain_textクラス内に本文が入っていたので、その通りにデータを引っ張ります。
そして、取得してきたデータを扱いやすくするため、最後にデータフレームに格納しました。
ちなみに、夏目漱石の作品数分だけスクレイピングしている訳ですが、これはつまり青空文庫のホームページに何度も自動アクセスしていることになります。
なので、一気に何百回、何千回とアクセスしてしまうと、もはやDoS攻撃と変わらず、非常に迷惑です。
よって、1回データを取得する事にsleep(1)で1秒ずつ処理を休ませています。(大切)
それでは、この関数を用いて、id_listの番号それぞれについてデータを取得して、データフレームに格納しましょう。
doc_list = []
for i in id_list:
title,doc = get_text(i)
doc_list.append([title,doc])
df_doc = pd.DataFrame(doc_list,columns=["作品名","本文"])
df_docを見てみると...

無事に夏目漱石の作品一覧がデータフレーム形式で取得できたようです。
形態素解析
さて、データも手に入った事ですので、いよいよ分析していきます。
まずは、テキストデータを入力したら形態素解析して、そこから名詞・動詞・形容詞をそれぞれ抽出するメソッドを定義します。
import MeCab
m = MeCab.Tagger("-Ochasen")
def word_analysis(doc):
node = m.parseToNode(doc)
meishi_list = []
doshi_list = []
keiyoshi_list = []
while node:
hinshi = node.feature.split(",")[0]
if hinshi == "名詞":
meishi_list.append(node.surface)
elif hinshi == "動詞":
doshi_list.append(node.feature.split(",")[6])
elif hinshi == "形容詞":
keiyoshi_list.append(node.feature.split(",")[6])
node = node.next
return pd.Series([list(set(meishi_list)), list(set(doshi_list)), list(set(keiyoshi_list))])
今回、形態素解析器にはMeCabを使用しました。
新語や固有名詞を多数収録したmecab-ipadic-NEologdもありますが、今回扱うのは古い文章なので、あえて使用していません。
※試してはみましたが、「あなたに」で一語になってしまったりしたので...(おそらく同名の楽曲あるため)
また、動詞と形容詞に関しては、単語の活用形があります。
これを別々に取得すると、「行く」「行った」「行こう」・・・という言葉が別の単語となってしまうのであまり宜しくありません。
そこで、node.featureを「,」で分割した6番目に用語の原型が入っているので、そこを取得するようにしています。
returnはSeries型で名詞リスト・動詞リスト・形容詞リストを返却しています。
今回、1つの小説で複数回出てくる単語はすべて「1回」と数えることにしました。
そのためにset関数を噛ませて、1つの文章内で重複する単語を排除しています。
逆に、1つの小説で複数回出てくる単語もそのまま集計したければset関数を除いてください。
では、この関数を用いて、作品ごとの名詞リスト・動詞リスト・形容詞リストを先のデータフレームの左側にくっつけます。
df_doc[["名詞","動詞","形容詞"]] = df_doc["本文"].apply(word_analysis)
さて、では再びdf_docを確認してみます。

なかなか良い感じですね。
結果の集計、グラフ化
では、集計に移ります。
list内の要素数をカウントして、ランキング化するのはcollectionsメソッドを使うのが便利です。
...が、現在、データフレームの中にlistが入っているという形になっています。
つまり、2次元リスト"風"になっているため、collectionsメソッドを使うにはまずこれを1次元にする必要があります。
そこで、itertools.chain.from_iterableメソッドを用いると、2次元リストが1次元になります。
では、試しに「動詞」の列を用いて出現頻度ランキングを作ってみましょう。
import itertools
import collections
words = list(itertools.chain.from_iterable(df_doc["動詞"]))
c = collections.Counter(words)
c.most_common()
collectionsのCounterで用語ごとの出現頻度が計算でき、most_common()で降順に並び替えられます。
では、結果を確認してみましょう。
[('する', 84),
('れる', 83),
('いる', 83),
('思う', 83),
('ある', 83),
('なる', 82),
('見る', 81),
('来る', 78),
('出る', 77),...
どうやら、これで夏目漱石が小説に多用した動詞ランキングが完成したようです。
折角なので(?)、グラフ化して視覚的に分かりやすくしてみます。
import seaborn as sns
import matplotlib.pyplot as plt
fig = plt.subplots(figsize=(8, 10))
sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white")
sns.countplot(y=words,order=[i[0] for i in c.most_common(20)],palette="Blues_r")
グラフ作成には、matplotlibとseabornを使います。
回数を棒グラフにするのはseabornのcountplotです。
フォントやサイズ、色合いなどはお好みで。
countplotで、上位〜件のみを表示する方法はリスト内包表記を用いた、ちょっとしたテクニックです。
今回は上位20位までを出力します。すると・・・
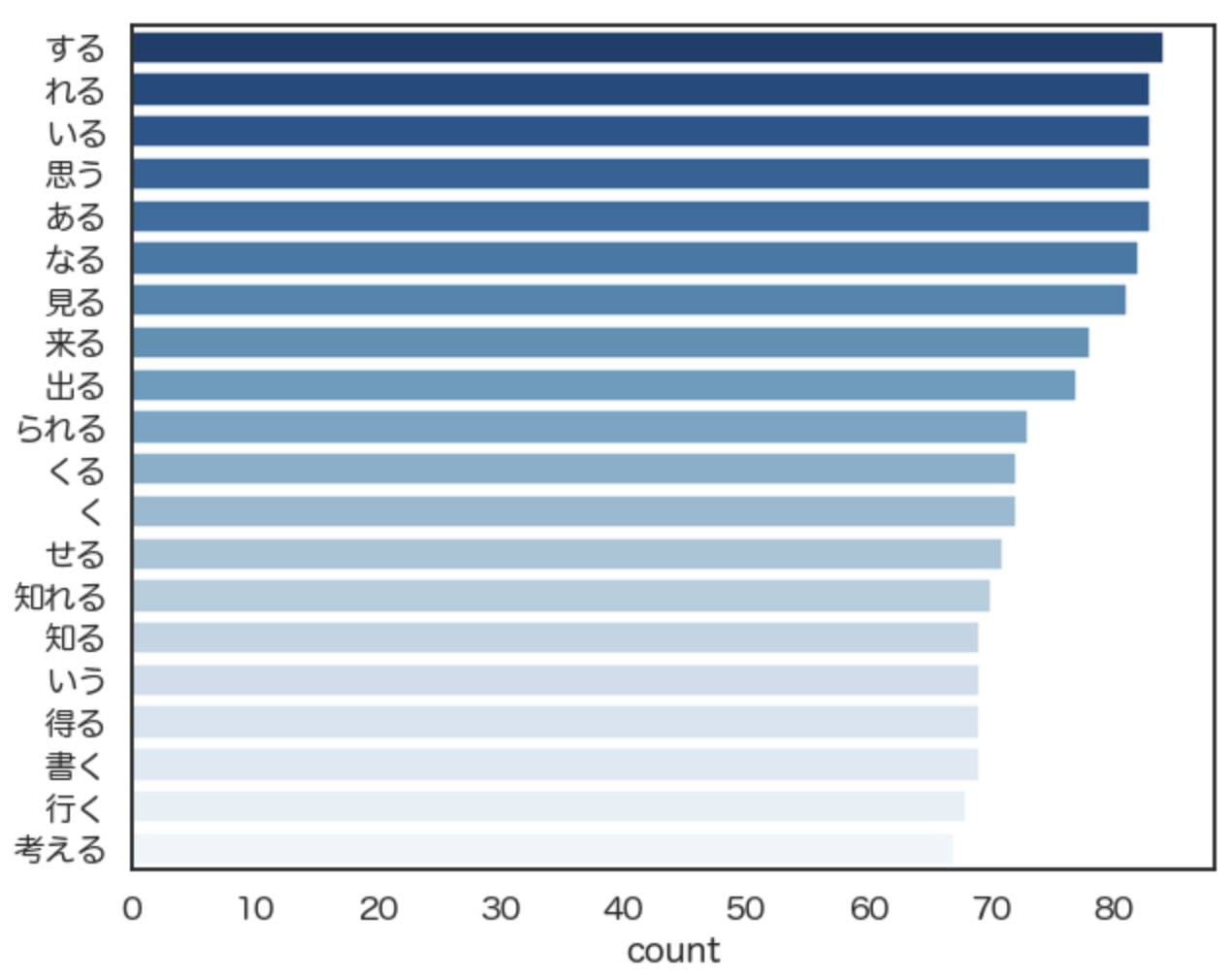
無事にグラフ化できました。
分析の目的によって適宜変わって来ますが、「する」「いる」などは大概の文章で頻出するので除いてしまってもいいかもしれません。
また、形態素解析も完璧ではないので、例えば「く」という言葉が絶対に動詞として用いられているのか、などは不確実なのでご留意ください。
このように、作者IDや、取得する品詞などを色々と変えれば、様々な結果が得られます。
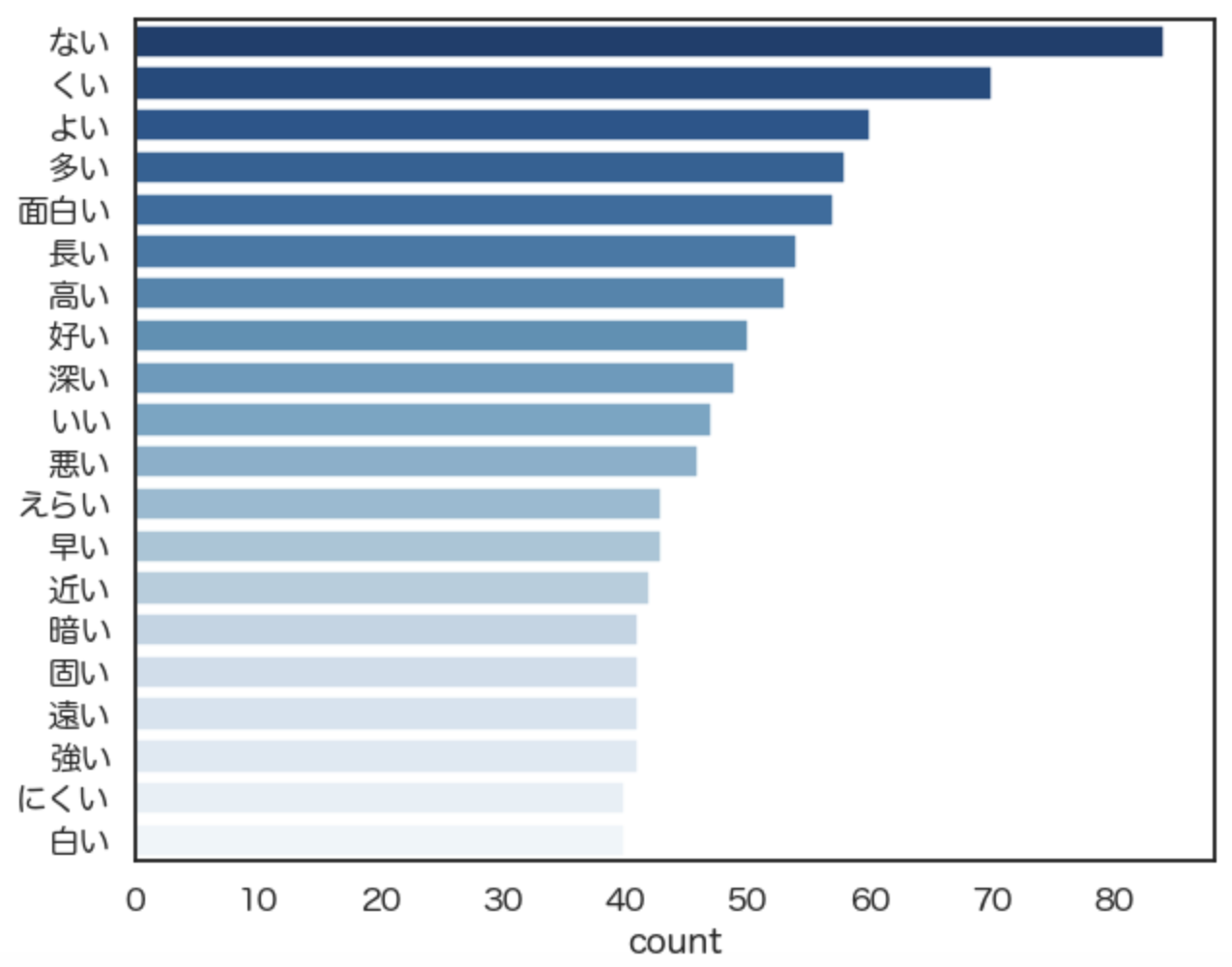
では、試しに夏目漱石が使った形容詞のTOP20のグラフを書いてみます。
続いては、太宰治が使った形容詞のTOP20のグラフを書いてみると、
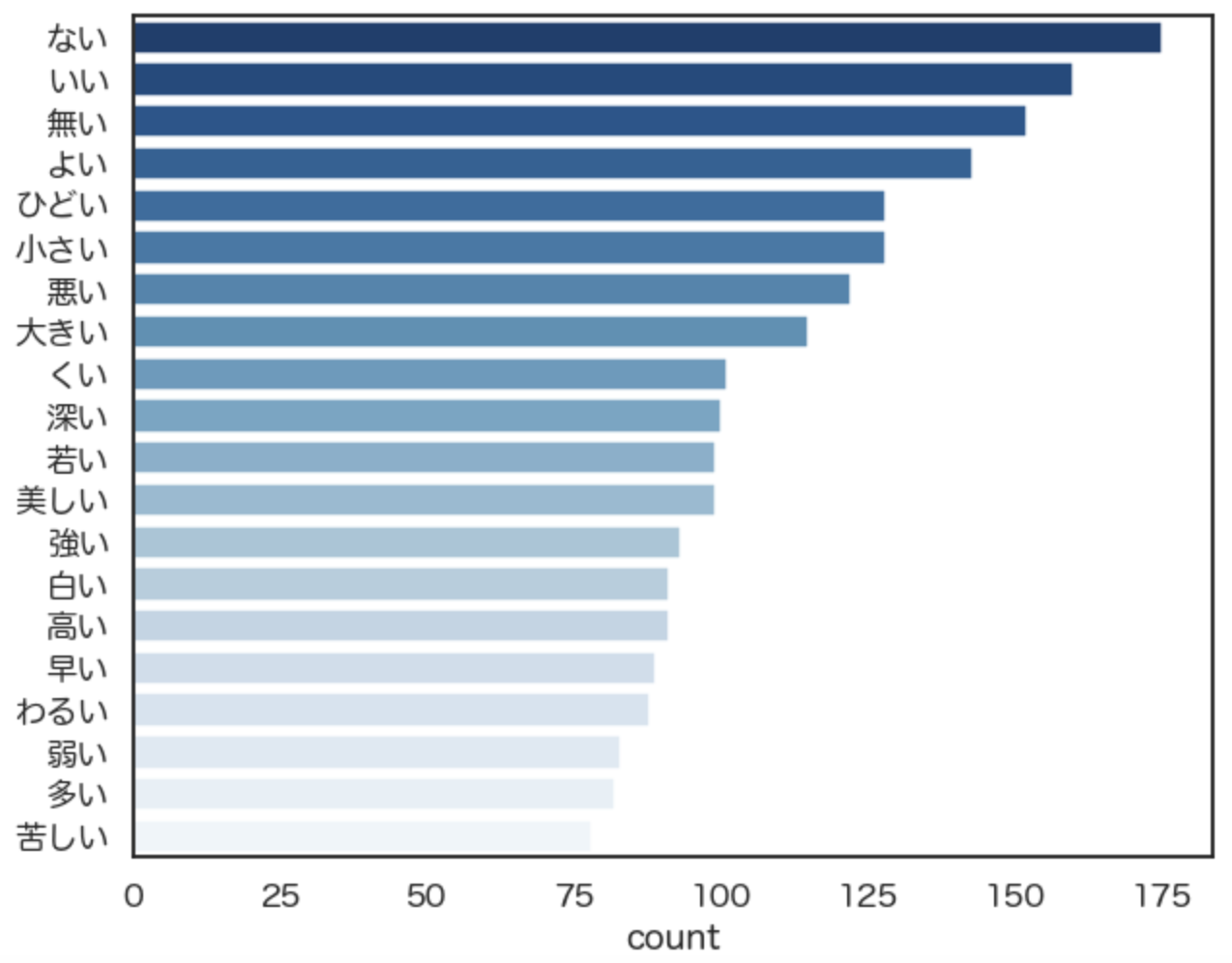
・・・となりました。
夏目漱石よりも、太宰治はネガティブな単語が上位に来るように見受けられます。
作者自身のイメージと一致するような気がしますね。
おわりに
以上、Pythonで、文学作品のテキストマイニングをやっていきました。
この記事を通してテキスト分析の方針や具体的な手法など、ご参考になれば幸いです。