屋外で暴走するDonkeyCar
室内ではそこそこ安定して動作するDonkey Carですが、屋外ではまともに動かず、明後日の方向に行ってしまう。
そこで学習結果からどこを認識しているのかみてみようと思いました。
現在、CNNの中間部分を取り出して表示しているものが、下のような画像を出力しています。
が、濃淡を出しているようにしか見えない。
成果物を流用したいが・・・
色々な人が試みているので、その成果を流用したいところですが、DonkeyCarの学習環境や、Keras,tensorflowのバージョンがまちまちで、私の実行環境では動きませんでした。
そこでこれを機に、勉強を兼ねてじっくり取り組みました。
作業しながらメモとして残しています。
皆様のツッコミ、アドバイスがあれば、順次取り入れて改良して行きますので、よろしくお願いします。
こちらの記事を参考にさせていだたいております。
https://qiita.com/yakisobamilk/items/8f094590e5f45a24b59c
そういえば、GitHubも使ったことがない
仕事で使うのはもっぱらSVNで、人様のプログラムを入手する目的以外でGitHubを使ったことがなかったです。
https://github.com/kumaxxp/visCNNDonkey
一応、ここに更新して行きますが、細かい使い方を全く理解していないので、突然消えたりするかも。
AnacondaでJupyterNotebook使って実装しています。
必要なのはvisCNNDonkey.ipynbだけ。
環境はCNNvis.ymlを参照。
サンプルとして自分の学習結果、mypilot。
Tensorflow 2.0を使って、Colaboで学習したものです。
あとで、Readme.mdも書いておかないと・・・
問題点 load_model()でモデルを読み込めない
皆さん、load_model(学習器)で、サクッとモデルを読み込んでいますが、私のところではエラーを起こしています。
DonkeyCarと同じ構成で学習器を作って、load_weight()で読み込んでいますが、ちょっと不便です。
自分の環境がTF1.13で、学習環境はTF2.0(Colabo)でした。
「load_modelはTensorFlow1.11で動くようです」
とアドバイスを頂いたので、試しにAnacondaの環境を変更してみますと、あっさり動きました。
環境のファイルを変更しておきます。
呼び出し方の間違いで、治っていませんでした。Kerasのバージョンに依存するようです。使用バージョンは2.2.4で、1.xからのバージョンアップで大きく変更されたとか。
使用していたKERASのバージョンは同じでした。
実行すると、延々長いエラーを吐いて止まります。
最終的には
ValueError: Unknown initializer: GlorotUniform
で停止。Colaboで学習するときに、TensorFlow2.0を使っていることが原因か?
(同様に学習を行なっている人で、load_model()が正常に実行できているという方もいる)
Colaboratoryで実行すると普通に動きました。
多分、TensorFlowをGPUオプションでインストールしていなとダメなんでしょうね。
問題点 解析結果は濃淡を別の色に置き換えただけではないか?
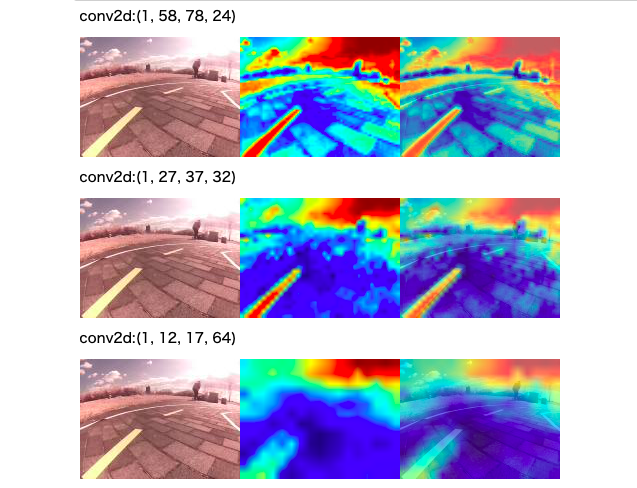
CNNで圧縮した経過の表示を出しています。
フィルタを通した順番に、表示すると




conv1の1を通した後は、単純に濃淡だけに見えましたが、処理が進むと別のところが赤く反応しています。
そもそも、赤いと反応しているのか、青いと反応が強いのか?
(強い=スロットルやステアリングに反応している?)
conv5の画像がもっともそれらしい画像のように思われます。
とりあえず、これを保存して動画を作ってみます。
動画にしてみた
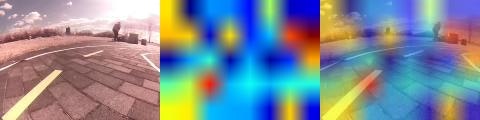
Convlustionの最初の方。
色彩を変換しているようにしか見えませんね。
空の雲やラインの白っぽいところが赤く表示されています。

そして、こちらは最終段階。
どこを特徴として捉えているのか謎な状況です。
白い線を捉えているわけでもなく、あちこちに赤い領域が飛び跳ねています。

結果、何を捉えているのか全くわからないという状況です。
次のアプローチ 解析の問題か、学習の問題か
現在、自分の手元には、学習が成功しているデータがありません。
何らか、安定してラインを追っているという結果が得られる実例が欲しいところ。
一旦、置いといて、Grad-camをやってみる
畳み込みの出力を重ねただけではわからないので、Grad-Camの手法を試してみることにします。
CNNの可視化手法Grad-CAMとは何か?
検索で参考にでてくるのが、クラス分けの学習機を対象にしたものが多いです。
もし、猫を検索するときの反応を見るなら、猫の出力のみ1で、他の出力を0で逆伝播をとれば簡単です。
DonekyCarの場合、ステアリングとスロットルの出力が両方とも幅を持っているので、出力値も幅を持たせる必要があるかもしれません。
そもそも、分類機以外でGrad-CAM手法が有効なのかどうかもわかりません。
細かいことは詳しい他の人にお願いするとして、Donkey Carでは
最終出力のステアリングで右方向の出力のみ値を入れる。
他を0とし、その信号を逆伝播させて、特徴マップでの勾配を求める。
と、言ったところでしょうか。
def DonkeyGradCAM(model_path = "" , file_path = ""):
#モデル読み込み
model_path = 'mypilot'
model = default_linear()
model.load_weights(model_path)
model.summary()
DonkeyGradCAM("mypilot","./tub_07_19-03-24/83_cam-image_array_.jpg")
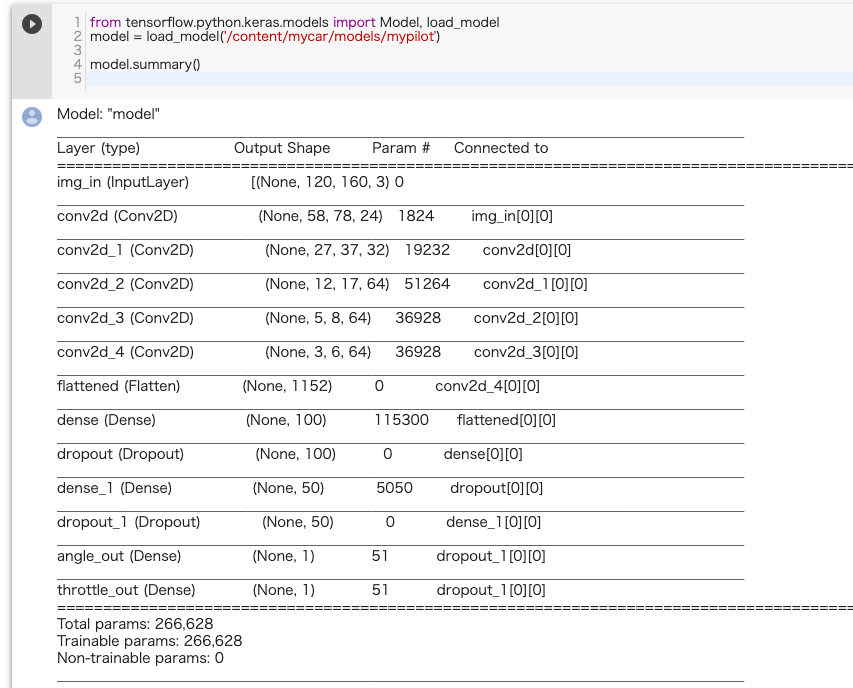
Dokey Carのモデルの出力は
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
img_in (InputLayer) (None, 120, 160, 3) 0
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 58, 78, 24) 1824 img_in[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, 27, 37, 32) 19232 conv1[0][0]
__________________________________________________________________________________________________
conv3 (Conv2D) (None, 12, 17, 64) 51264 conv2[0][0]
__________________________________________________________________________________________________
conv4 (Conv2D) (None, 5, 8, 64) 36928 conv3[0][0]
__________________________________________________________________________________________________
conv5 (Conv2D) (None, 3, 6, 64) 36928 conv4[0][0]
__________________________________________________________________________________________________
flattened (Flatten) (None, 1152) 0 conv5[0][0]
__________________________________________________________________________________________________
dense_8 (Dense) (None, 100) 115300 flattened[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (None, 100) 0 dense_8[0][0]
__________________________________________________________________________________________________
dense_9 (Dense) (None, 50) 5050 dropout_8[0][0]
__________________________________________________________________________________________________
dropout_9 (Dropout) (None, 50) 0 dense_9[0][0]
__________________________________________________________________________________________________
angle_out (Dense) (None, 1) 51 dropout_9[0][0]
__________________________________________________________________________________________________
throttle_out (Dense) (None, 1) 51 dropout_9[0][0]
==================================================================================================
Total params: 266,628
Trainable params: 266,628
Non-trainable params: 0
最後の畳み込み層は conv5 (Conv2D) で、conv4[0][0]からの入力を受け取って、(None, 3, 6, 64) を出力。
入力に対して3*6の行列が64チャンネルあるということ。
Grad-CAMのアルゴリズムは畳み込み出力の最終出力への勾配を求めるので、3*6*64の値を変化させたときに、最終出力に大きく影響を与えるものが、判定に影響のある場所。ということ。(?)
Angle(ステアリング)への影響を調べる
モデルの最終出力をAngleと仮定して、その出力への影響を調べることとします。
def DonkeyGradCAM(model_path = "" , file_path = ""):
#モデル読み込み
model_path = 'mypilot'
model = default_linear()
model.load_weights(model_path)
#angleの出力レイヤーを取得
model_output = model.get_layer('angle_out')
#畳み込みの最終出力を取得
last_conv = model.get_layer('conv5')
#最終畳み込み層の出力と、Angleの出力に関して勾配を計算する関数を定義する
grads = K.gradients(model_output, last_conv.output)[0]
DonkeyGradCAM("mypilot","./tub_07_19-03-24/83_cam-image_array_.jpg")
と、考えて実行してみると・・・エラーがずらずら吐き出されます。
訂正してみます。
K.gradients()に入れるのは、レイヤーではなく、レイヤーのoutputですね。
書き換えて訂正します。
def DonkeyGradCAM(model_path = "" , file_path = ""):
#モデル読み込み
model_path = 'mypilot'
model = default_linear()
model.load_weights(model_path)
#angleの出力レイヤーを取得
model_output = model.get_layer('angle_out').output
#畳み込みの最終出力を取得
last_conv = model.get_layer('conv5').output
#最終畳み込み層の出力と、Angleの出力に関して勾配を計算する関数を定義する
grads = K.gradients(model_output, last_conv.output)[0]
DonkeyGradCAM("mypilot","./tub_07_19-03-24/83_cam-image_array_.jpg")
続きはまた明日。
ほどほどに知見を得たら、改めて
https://github.com/ermolenkodev/keras-salient-object-visualisation?fbclid=IwAR2m13vsYrIgQ1hkA7e738NLqTE5OaoHePs9NgM6d8ph2Pfkrx4yq4OMyRA
を読んでみよう。