CORAL USBのドキュメントを自分のために雑に翻訳
Donkey Carの負荷を減らしたいので、CNNのモデルが動いたらOKな程度
Edge TPUのTensorFlowモデル
Edge TPUが低電力コストで高速ニューラルネットワーク性能を提供するために、Edge TPUは特定のニューラルネットワーク操作とアーキテクチャのセットをサポートします。このページでは、Edge TPUと互換性のあるモデルの種類、作成方法、および実行方法について説明します。
互換性の概要
Edge TPUは、コンボリューションニューラルネットワーク(CNN)などのディープフィードフォワードニューラルネットワークを実行できます。完全に8ビット量子化され、Edge TPU用に特別にコンパイルされたTensorFlow Liteモデルのみをサポートします。
あなたがTensorFlow Liteに慣れていないならば、それはモバイルと埋め込みデバイスのために設計されたTensorFlowの軽量版です。 TensorFlow Liteモデルとインタプリタカーネルの両方がはるかに小さいので、小さなバイナリサイズで低遅延の推論を実現します。 TensorFlow Liteを使ってモデルを直接訓練することはできません。代わりに、TensorFlow Liteコンバーターを使用して、モデルをTensorFlowファイル(.pbファイルなど)からTensorFlow Liteファイル(.tfliteファイル)に変換する必要があります。
TensorFlow Liteへのリンク
https://www.tensorflow.org/lite
TensorFlowは、Edge TPUで必要とされる量子化と呼ばれるモデル最適化手法をサポートしています。モデルの量子化とは、すべての32ビット浮動小数点数(重みやアクティベーション出力など)を最も近い8ビット固定小数点数に変換することを意味します。これはモデルをより小さくそしてより速くする。そして、これらの8ビット表現はそれほど正確ではないかもしれませんが、ニューラルネットワークの推論精度はそれほど影響されません。
注:Edge TPUは、トレーニング後の量子化を使用して構築されたモデルをサポートしません。これは、8ビット値を使用して小さいモデルを作成しますが、推論中にそれらを32ビット浮動小数点に変換するためです。したがって、トレーニング中に8ビット値の効果をシミュレートするために「偽の」量子化ノードを使用する量子化対応トレーニングを使用する必要があります。したがって、推論は量子化された値を使用して実行できます。この手法により、モデルの精度の低い値に対する耐性が高まり、一般にトレーニング後の量子化と比べて精度の高いモデルになります。
図1は、Edge TPUと互換性のあるモデルを作成するための基本プロセスを示しています。ほとんどのワークフローは標準のTensorFlowツールを使用しています。 TensorFlow Liteモデルを作成したら、次にEdge TPUコンパイラを使用してEdge TPUと互換性のある.tfliteファイルを作成します。

図1. Edge TPU用のモデルを作成するための基本的なワークフロー
ただし、Edge TPUのための優れたモデルを作成するためにこのプロセス全体に従う必要はありません。代わりに、Edge TPUと互換性のある既存のTensorFlowモデルを独自のデータセットで再学習することで利用できます。たとえば、MobileNetは、Edge TPUと互換性のある一般的な画像分類/検出モデルアーキテクチャです。このモデルのいくつかのバージョンを作成しました。さまざまなオブジェクトを認識する独自のモデルを作成するための出発点として使用できます。まず始めに、既存のモデルをトランスファーラーニングで再トレーニングする方法について以下のセクションを参照してください。
しかし、最初から自分のモデルを設計した(または設計する予定がある)場合は、モデル要件についての次のセクションを読む必要があります。
モデル要件
実行時にEdge TPUを最大限に活用する独自のTensorFlowモデルを構築する場合は、以下の要件を満たす必要があります。
テンソルパラメータは量子化されます(8ビット固定小数点数)。量子化対応トレーニングを使用する必要があります(トレーニング後の量子化はサポートされていません)。
テンソルのサイズはコンパイル時には一定です(動的サイズはありません)。
モデルパラメータ(バイアステンソルなど)はコンパイル時に一定です。
テンソルは1次元、2次元、3次元のいずれかです。テンソルの次元数が3より大きい場合、最も内側の3つの次元のみが1より大きいサイズになります。
このモデルは、Edge TPUでサポートされている操作のみを使用します(下記の表1を参照)。
モデルがこれらの要件を完全には満たしていない場合でも、コンパイルは可能ですが、モデルの一部のみがEdge TPUで実行されます。サポートされていない操作が発生するモデルグラフの最初の点で、コンパイラはグラフを2つの部分に分割します。サポートされている操作のみを含むグラフの最初の部分は、Edge TPU上で実行されるカスタム操作にコンパイルされ、その他すべてはCPU上で実行されます(図2を参照)。
注:現在、Edge TPUコンパイラはモデルを複数回分割できないため、サポートされていない操作が発生するとすぐに、サポートされている操作が後で発生しても、その操作とCPUでの実行後のすべての操作が行われます。
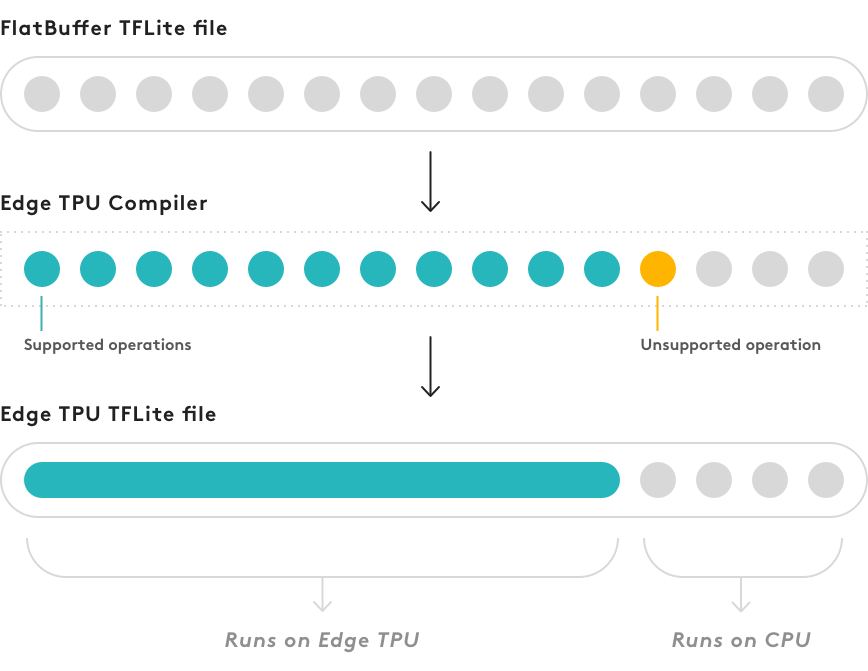
図2.コンパイラーは、すべてのEdge TPU互換操作用に単一のカスタム操作を作成します。他に何も変わらない
コンパイルしたモデルを(visualize.pyなどのツールを使って)調べても、グラフの先頭にカスタム操作があることを除けば、それはまだTensorFlow Liteモデルです。このカスタム操作は、実際にコンパイルされるモデルの唯一の部分です。EdgeTPU上で実行されるすべての操作が含まれています。グラフの残りの部分(最初のサポートされていない操作で始まる)は変わりません。
モデルの一部がCPU上で実行される場合は、Edge TPU上で完全に実行されるモデルと比較して、推論速度が大幅に低下することが予想されます。この状況でモデルのパフォーマンスが大幅に低下することは予測できないため、さまざまなアーキテクチャを試して、Edge TPUと100%互換性のあるモデルを作成するようにしてください。つまり、コンパイルしたモデルにはEdge TPUカスタム操作のみを含める必要があります。
注:コンパイルが完了すると、Edge TPUコンパイラーは、Edge TPUで実行できる操作の数と、代わりにCPUで実行する必要がある操作の数(ある場合)を通知します。ただし、Edge TPU上で実行される操作とCPU上で実行される操作の割合は、全体的なパフォーマンスへの影響とは一致しません。モデルのごく一部でもCPU上で実行されると、推論速度が1桁遅くなる可能性があります。 (Edge TPU上で完全に動作するモデルのバージョンと比較して)
表1. Edge TPUでサポートされているすべての操作と既知の制限事項
表は省略
トランスファーラーニング
上記の要件に準拠するように独自のモデルを構築してから最初からトレーニングする代わりに、転送学習と呼ばれる技法(「微調整」とも呼ばれる)を使用して、Edge TPUと既に互換性のある既存のモデルを再トレーニングできます。
最初からニューラルネットワークをトレーニングすること(計算された重みやバイアスがない場合)は、数日分の計算時間がかかる可能性があり、膨大な量のトレーニングデータを必要とします。しかし、移動学習を使用すると、関連タスクについてすでにトレーニングされたモデルから始めて、さらにトレーニングを実行して、より小さなトレーニングデータセットを使用してモデルに新しい分類を教えることができます。モデル全体を再訓練する(ネットワーク全体の重みを調整する)ことでこれを行うことができますが、分類を実行する最後の層を削除し、新しいクラスを認識する新しい層を単純に訓練することで非常に正確な結果を得ることもできます。
このプロセスを使用して、十分なトレーニングデータとハイパーパラメータの調整を行うことで、一回の作業で非常に正確なTensorFlowモデルを作成できます。モデルのパフォーマンスに満足したら、それをTensorFlow Liteに変換してからEdge TPU用にコンパイルします。また、モデルアーキテクチャはトランスファーラーニング中に変更されないため、Edge TPU用に完全にコンパイルされることがわかります(互換性のあるモデルから始めると仮定して)。
トランスファーラーニングに慣れている方は、Edge TPU互換モデルをチェックしてください。あなたが自分自身のモデルを作成するための出発点として使用できます。クリックするだけで "All model files"をダウンロードしてTensorFlowモデルと事前学習済みのチェックポイントを取得し、移動学習を開始する必要があります。
この方法に慣れておらず、すぐに結果を確認したい場合は、新しいクラスを使用してMobileNetモデルを再トレーニングするプロセスを単純化する次のチュートリアルを試してください。
画像分類モデルの再学習
物体検出モデルを退避させる
私たちのPython APIを介したウェイトインプリントと呼ばれる少し異なる手法を使用して、Edge TPUを使用してデバイス上で直接モデルを再トレーニングすることもできます。
画像分類モデルをデバイス上で後退させる
Edge TPUランタイムとAPI
モデルをEdge TPUで実行するには、ホストシステムにEdge TPUランタイムとAPIライブラリがインストールされている必要があります。
Coral Dev BoardまたはSoMを使用している場合、Edge TPUランタイムおよびAPIライブラリは既にMendelオペレーティングシステムに含まれています。 Coral USB Acceleratorなどのアクセサリデバイスを使用している場合は、両方をホストコンピュータにインストールする必要があります。現在サポートされているのはDebianベースのオペレーティングシステムのみです(セットアップ手順を参照)。
ご使用のホストシステムから、Edge TPUライブラリで提供されている次のいずれかのAPIを使用して推論を実行できます。
Edge TPU C ++ API:これはTensorFlow Lite C ++ APIのほんの小さな拡張(edgetpu.h)なので、ほとんどの場合後者を使用してモデルとの推論を実行します。
Edge TPU Python API:これは、ClassificationEngineなど、C ++には含まれていない便利なAPIをいくつか追加したC ++ APIのラッパーです。これにより、コンパイル済みの.tfliteモデルと分類したい画像を提供するだけで画像分類を実行できます。
ここまでのまとめ
Edge TPUランタイムとAPIライブラリをラズパイにインストールして、TensorFlow Liteにコンバートしたモデルを動かせ。
画像分類とかよく使うタイプのモデルは、転移学習すると便利ですよ。
・・・というまとめで良いかな?
Edge TPU Modelコンパイラを翻訳してみる
エッジTPUモデルコンパイラ
モデルをEdge TPU用にコンパイルします。
下記の.tfliteファイルをアップロードして、Edge TPUとの互換性のためにTensorFlow Liteモデルをコンパイルしてください。
必要条件
実行時にEdge TPUを最大限に活用するTensorFlowモデルを作成するには、次の要件を満たす必要があります。
- テンソルパラメータは量子化されます(8ビット固定小数点数)。量子化対応トレーニングを使用する必要があります(トレーニング後の量子化はサポートされていません)。
- テンソルのサイズはコンパイル時には一定です(動的サイズはありません)。
- モデルパラメータ(バイアステンソルなど)はコンパイル時に一定です。
- テンソルは1次元、2次元、3次元のいずれかです。テンソルの次元数が3より大きい場合、最も内側の3つの次元のみが1より大きいサイズになります。
- モデルは、Edge TPUでサポートされている操作のみを使用します(次のリンクを参照)。
互換モデルの作成について詳しくは、Edge TPUのTensorFlowモデルを参照してください。
モデルをアップロードする
コンパイルが完了するまでに約1分かかります。
モデルデータは常に非公開です。このツールでは、モデルのデータを記録することはできません。
*Googleの利用規約を読み、確認しました。
*私のモデルは、GoogleのAI原則に準拠するアプリケーションにのみ使用されることに同意します。