この記事はIBM Cloud Advent Calendar 2017 - Qiitaの15日目の記事です。
「初めてのWatson」の書籍を勉強していたら
「初めてのWatson APIの用例と実践プログラミング」の書籍、Watson APIのNLC(Natural Language Classifier)とR&Rを勉強しようとしたが、R&Rのサービスが2018年10月3日でサポート廃止とのこと。
そこで後継のサービスWatson Discoveryを触ってみることにしました。
最初は、チュートリアルをやってみました。
Getting started with the toolingの内容の沿って始めました。
※ IBM Cloud ライト・アカウント作成の手順は、ここを参考にしてみてください。
1.はじめにサンプルをダウンロードします。
上記のチュートリアルからサンプルのHTMLファイルを4つ( test-doc1.html, test-doc2.html, test-doc3.html, test-doc4.html)ダウンロードします。
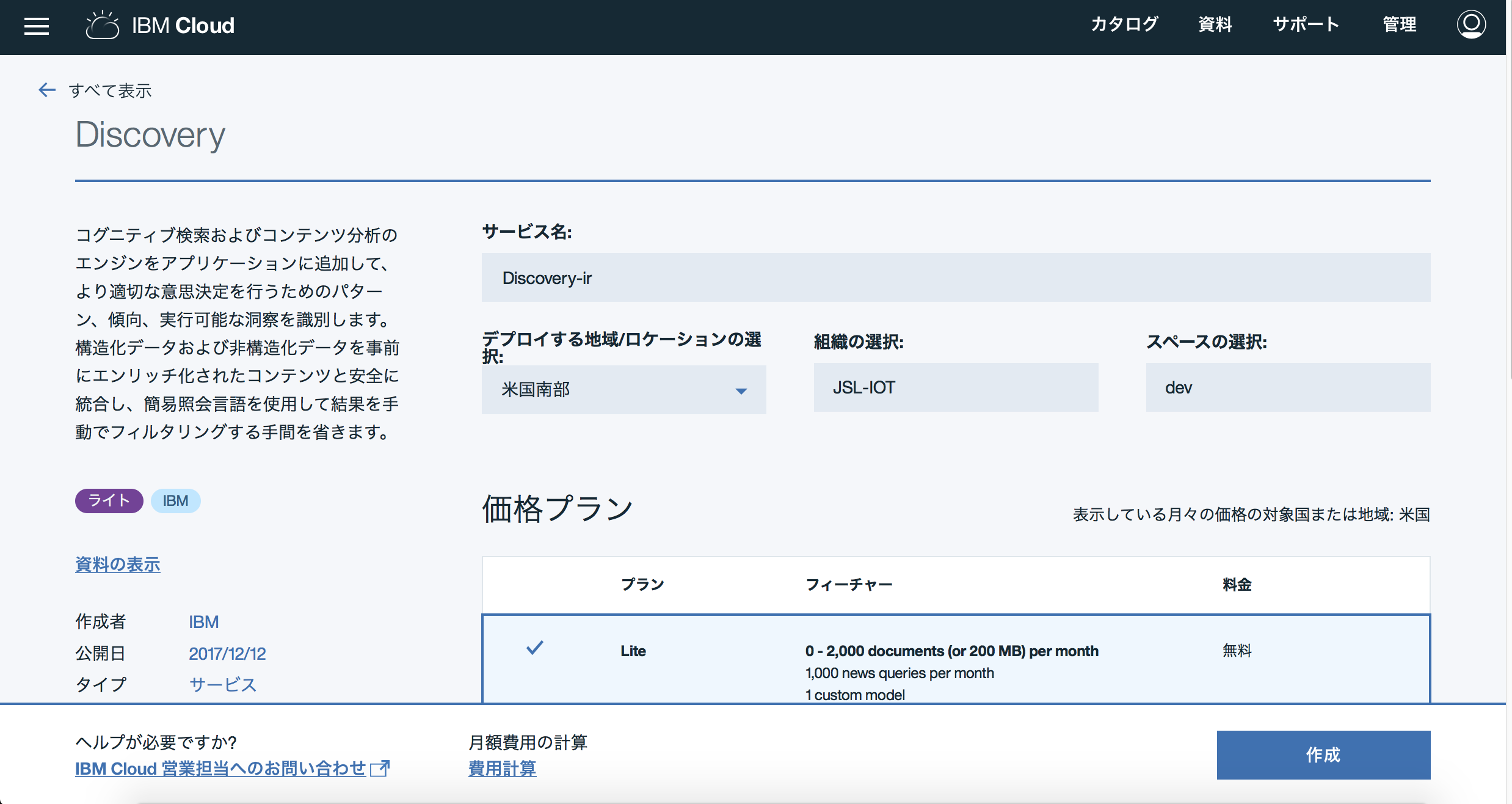
2.Discoveryのインスタンスを作成します
IBM CloudのカタログからDiscoveryを選択します。
サービス名は任意に入力、Liteプランで作成します。
こんな画面が表示されます。
3.Discovery toolingを起動します。
作成したサービスをクリックし、Launch Toolボタンをクリックします。

Discovery toolingが開いたら、右上のマーク![]() 「CREATE ENVIRONMENT」をクリックし、ストレージがセットアップされます。
「CREATE ENVIRONMENT」をクリックし、ストレージがセットアップされます。
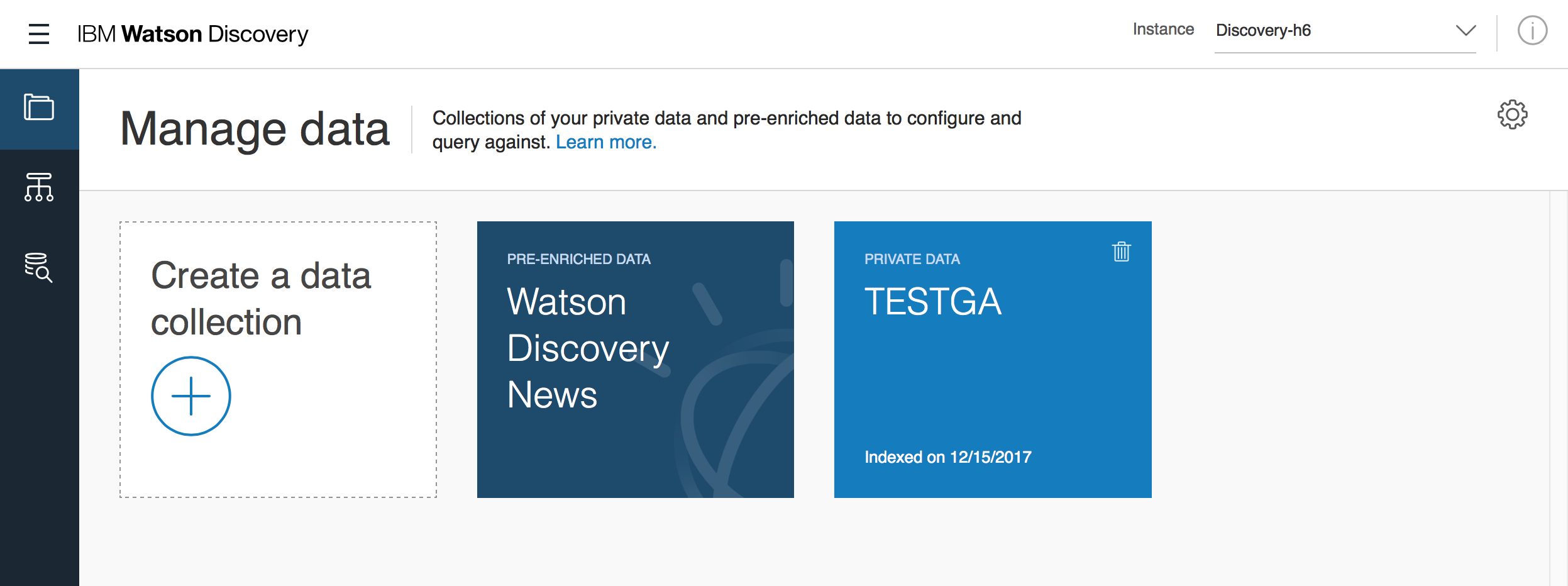
Collectionに好きな名前を入力して作成します。
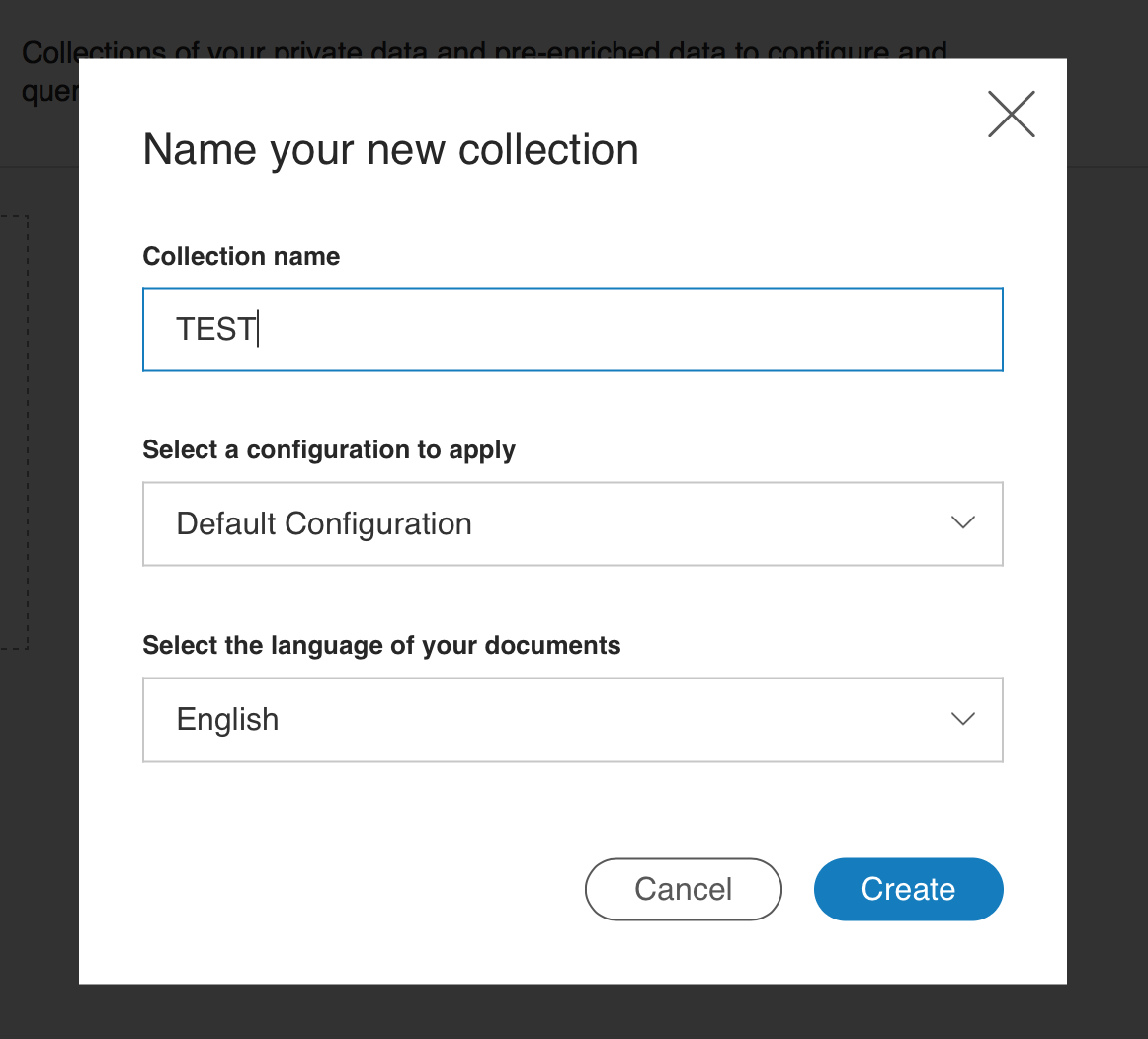
一つめのCollectionが作成されます。
4.文書のアップロードを行います
最初の初期画面に戻ったら作成したCollectionを開きます。
準備した4つのHTMLファイルをアップロードします。
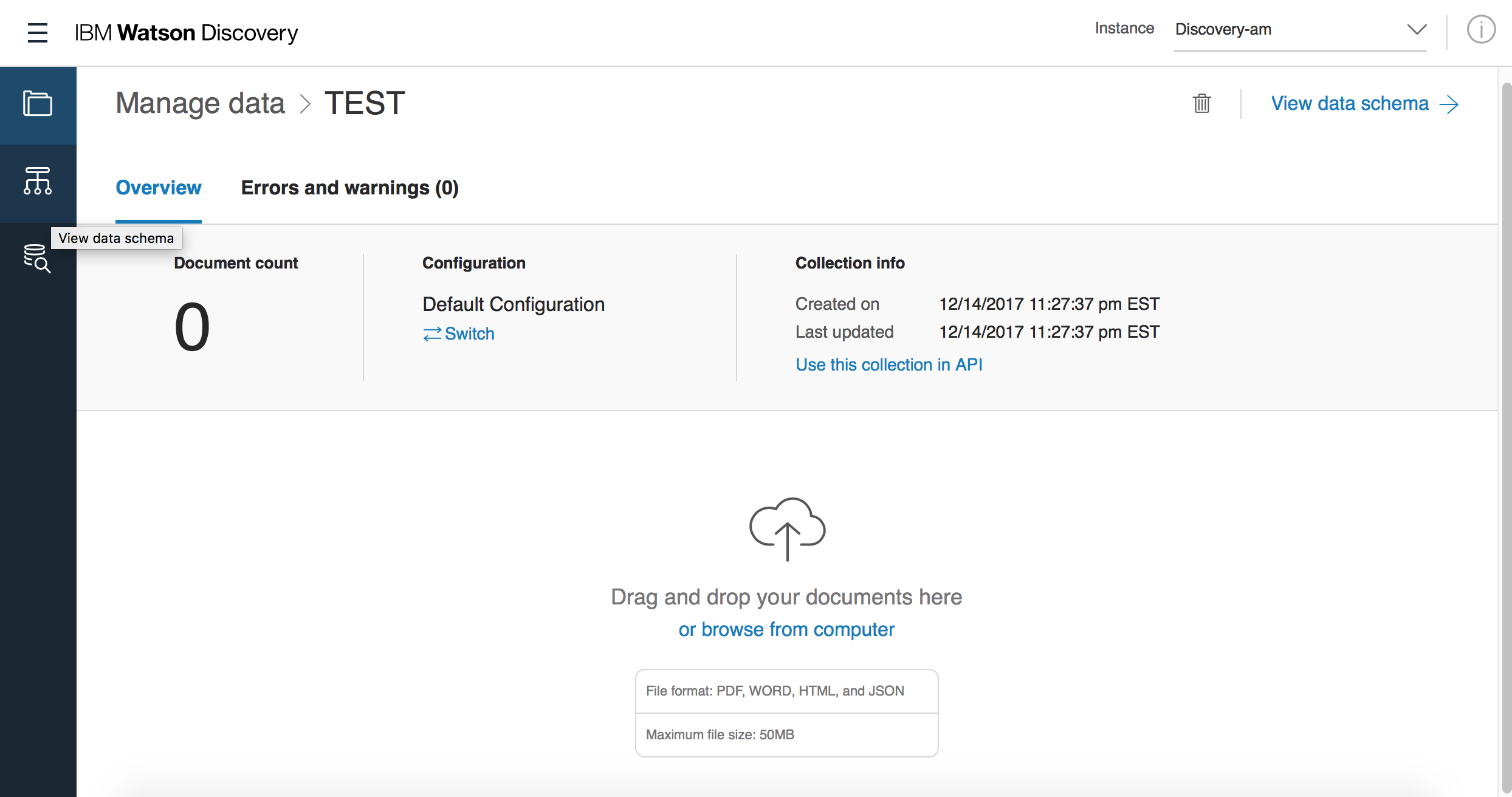
アップロードが完了すると下記の画面になります。
Documents countsが4なら大丈夫です。もう検索できますよ。
5.文書の照会(Query)をやってみる
左のバーの一番したのアイコンをクリックし、照会対象であるご自身のCollectionを選択のうえ「Get Started」をクリックします。

Visual Query Builder(VQB)が使えるようになります
チュートリアルでは、エンティティに「IBM」という単語を含む文章を抽出するのですが、
ここでは、下記のHTMLファイルでどのようになるか試してみました。
- 機動戦士ガンダム- Wikipedia の英語サイト
- 機動戦士ガンダム 逆襲のシャア- Wikipediaの英語サイト
- 機動戦士ガンダムUC - Wikipediaの英語サイト
エンティティに「Amuro」とうい単語で文章を抽出することにした。
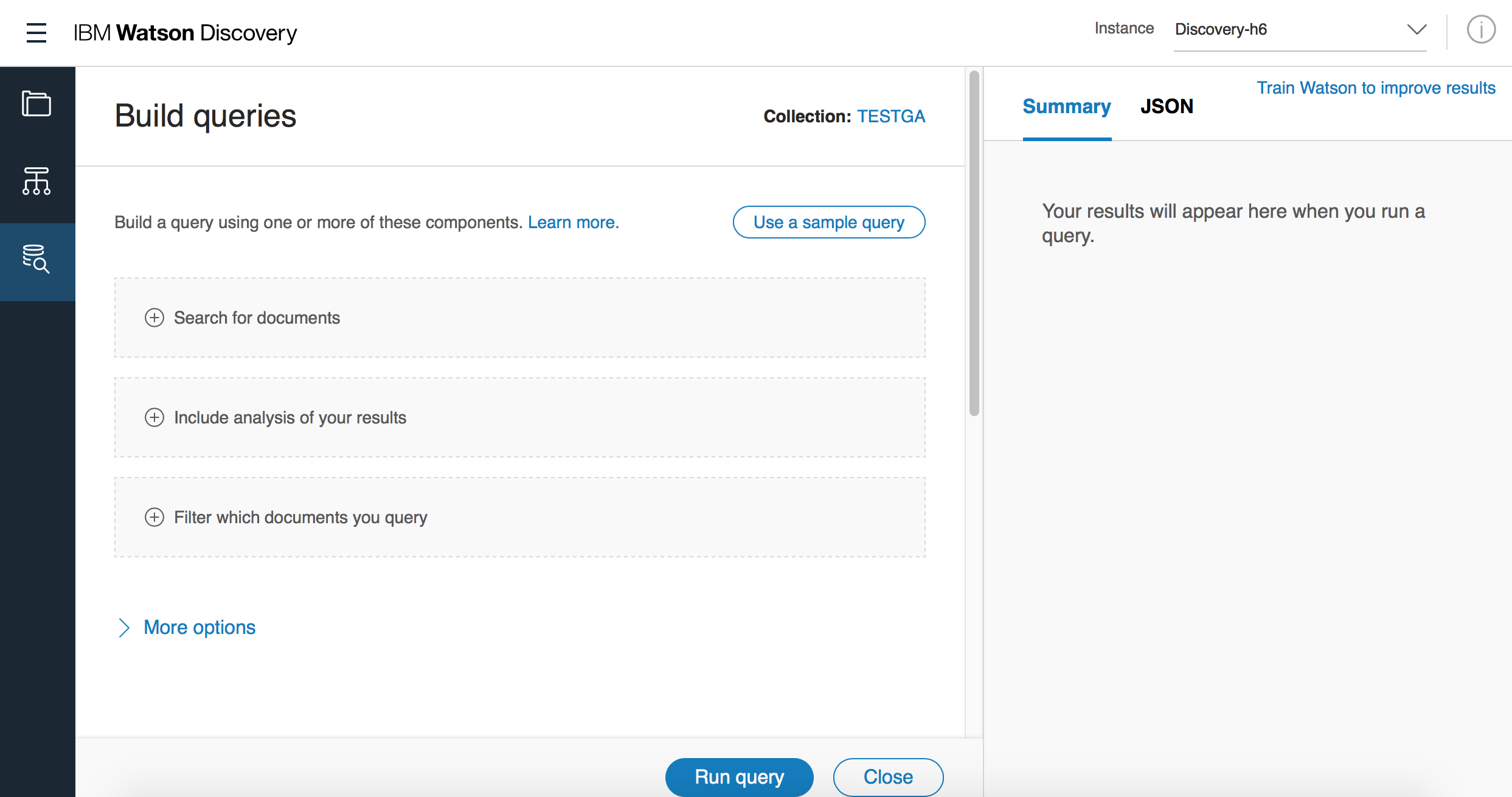
- ① Search for documentsを展開し「Use the Discovery Query Language」のタブを選択します
- ② enriched_text.entities.text / contains / Amuroと入力します。結果、enriched_text.entities.text:AmuroというDQLが生成されます
- ③「Run Query」
- ④ 右側のペイン「Results」に結果が表示されます。

いい感じに 機動戦士ガンダム、機動戦士ガンダム 逆襲のシャアの2件分が検出されていることが確認できます。
6.自然言語照会
VQEで「Edit query language」をクリック
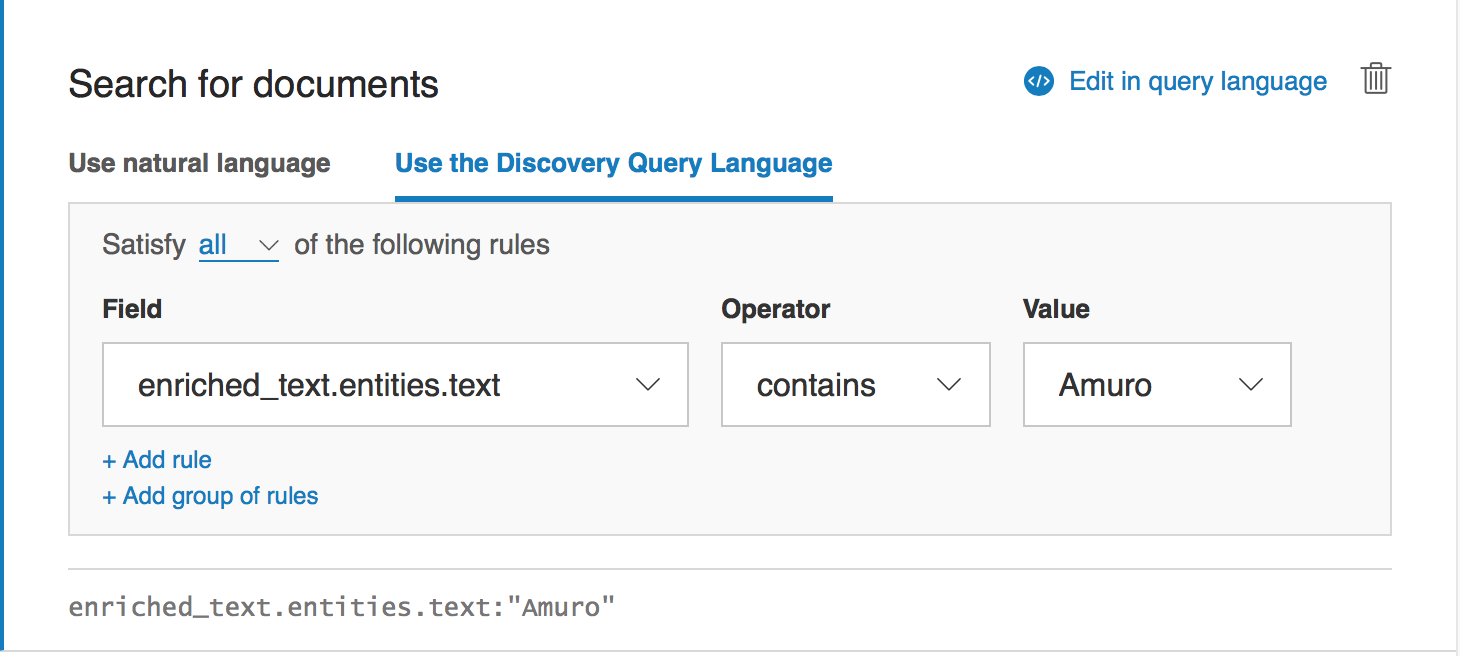
パネルが切り替わるので「Use Natural Language」タブをクリックすると自然言語で質問が入力できます。
「Amuroは何を操縦したか?」(Amuroは何を操縦したか??)との質問をしてみました。(Gundamとの回答を期待) 結果は3件全部ヒットしてしまいました。ユニコーンの記事は検出されないと思ったのですが、pilot、Whatで検出されたみたいです。(笑)
チュートリアルでもそうですが、JSONのスコアで見ると機動戦士ガンダムの記事が最も高く、Passageも機動戦士ガンダムのAmuroのスニペットが先頭に来ていました。(笑)
まとめ
まだ、この時点で、Discoveryの日本語対応で全機能は対応していませんでした。
それで全機能がある英語で試してみました。
早く日本語対応も全機能になることを切に願います。(笑)
トレーニングする基の文書データもキチンと精査してアップロードするべきだと思いました。
今度こそは上手く行くように考えます。(笑)
はじめて書きましたが、これをきっかけにどんどん書きたいと思います。![]()
