この記事とこの記事の続き.
プリアンブルや使うデータセットは前々回の記事を参照.
前々回でプロットの簡単な装飾には触れたが, もう少し細かく調整したいこともあるので, そのまとめ.
他の記事へのリンクも書いておく.
文字を記入する
文字列に限らないが, info{...} を用いるとその中で TikZ のコマンドが使えるようになる.
\begin{tikzpicture}
\datavisualization[
scientific axes,
visualize as line/.list={tri, qua},
tri={style={blue}},
qua={style={red}}
]
data[set=tri, headline={x, y}, read from file=triangle.csv]
data[set=qua, headline={x, y}, read from file=quadrangle.csv]
info{
\node[fill=lime] at (visualization cs: x=2, y=3) {テキスト};
\draw[orange, ->] (visualization cs: x=1.5,y=1) -- (visualization cs: x=5,y=4);
\node[above] at (visualization cs: x=3,y=4.5) {枠外もOK};
}
info'{
\fill[yellow] (visualization cs: x=4, y=2) circle [radius=2mm];
};
\end{tikzpicture}
出力:
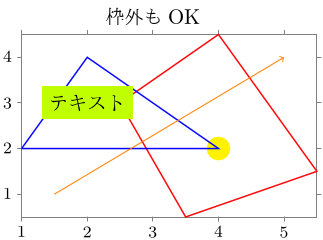
(visualization cs: x=x座標, y=y座標) で, プロット内の座標にアクセスできる (cs = coordinate system).
同じ tikzpicture 環境内かつ \datavisualization の外で座標を指定しても, 「tikzpicture 環境内での座標」になるだけで, プロット内の座標ではなくなるという点に注意が必要.
また, info' を用いると, データセットのプロットより先に描画する.
上の例で, 「テキスト」と書かれた黄緑色の四角形と, 座標 $(4,2)$ にある黄色い円とで, 青い三角系との上下関係が異なっていることに注意.
なお, info{...} の中は普通の tikzpicture 環境と同じような状況になるので, 各行ごとにセミコロンを付ける必要がある.
複数のプロットに同じ装飾をする
異なるデータセットに, 同じ装飾を施したい, ということがある.
tikzpicture 環境でスタイルシートのようなものを定義できるので, この機能を使えば良い.
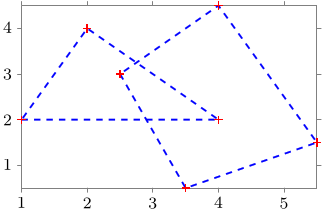
例えば2つのデータセットに, 共通して 青線, 破線, 太線, データ点に+印のマーカー, マーカーは赤色, というスタイル (これに mystyle という名前をつけることにする) を施したければ, 以下のようにすれば良い.
\begin{tikzpicture}[
mystyle/.style={blue, dashed, thick, mark=+, mark options={red}}
]
\datavisualization[
scientific axes,
visualize as line/.list={tri, qua},
tri={style=mystyle},
qua={style=mystyle}
]
data[set=tri, headline={x, y}, read from file=triangle.csv]
data[set=qua, headline={x, y}, read from file=quadrangle.csv];
\end{tikzpicture}
出力:
data point[outlier] を用いたバッドノウハウ
以下のようにサボってみると, 三角形と四角形がつながってしまって, 失敗する.
\begin{tikzpicture}
\datavisualization[
scientific axes,
visualize as line/.list={lines},
lines={style={blue, dashed, thick, mark=+, mark options={red}}}
]
data[set=lines, headline={x, y}, read from file=triangle.csv]
data[set=lines, headline={x, y}, read from file=quadrangle.csv];
\end{tikzpicture}
出力(失敗例):
これは当然で, 2つのデータセットに同じ名前をつけると, 1つのデータセットとみなされてしまうからである.
実は, data point[outlier]というコマンド(?)でデータセットを区切ることができるので, これを使ってちょっとズルをすることもできる.
\begin{tikzpicture}
\datavisualization[
scientific axes,
visualize as line/.list={lines},
lines={style={blue, dashed, thick, mark=+, mark options={red}}}
]
data[set=lines, headline={x, y}, read from file=triangle.csv]
data point[outlier]
data[set=lines, headline={x, y}, read from file=quadrangle.csv];
\end{tikzpicture}
出力:
異なるデータセットを同じデータセットだとみなしているという点は変わっていないので, これはバッドノウハウである.
本来は, $1/x$ や $\tan x$ などの関数に対して, 特異点付近でグラフを切って描画するときなどに data point[outlier] を用いることが想定されている.
閉曲線をプロットするときの始点-終点の処理
これは細かいことだが, 今のデータセットのように閉曲線になっている場合は, 始点(=終点)の部分がコーナーになっていない.
実際, 座標 $(2.5,3)$ の付近を拡大すると, 次のようになっている.
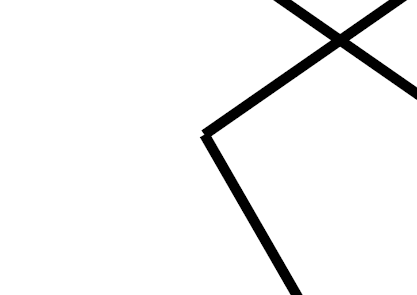
この現象は datavisualization とは関係なしに起きる. 例えば
\tikz \draw (0,0) -- (1,0) -- (1,1) -- (0,0);
としても同様の現象が起きる.
\draw の場合は, cycle というのを入れればちゃんとコーナーになる.
\tikz \draw (0,0) -- (1,0) -- (1,1) -- cycle;
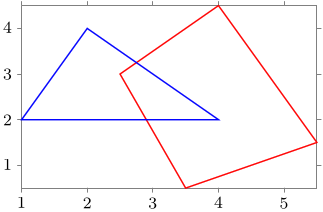
datavisualization の場合で同じようなことをするには, straight cycle または polygon というオプションを指定すれば良い.
\begin{tikzpicture}
\datavisualization[
scientific axes,
visualize as line/.list={tri, qua},
tri={style={blue}, straight cycle},
qua={style={red}, polygon}
]
data[set=tri, headline={x, y}, read from file=triangle.csv]
data[set=qua, headline={x, y}, read from file=quadrangle.csv];
\end{tikzpicture}
出力:
出力結果を拡大:
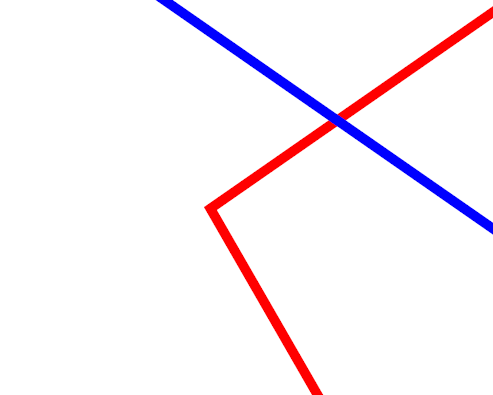
ちゃんとコーナーになっている.