こんにちは!
ポーラ・オルビスホールディングスのITプロダクト開発チームでスクラムマスターをしている川田です。
今回は、開発チームで利用している技術や開発環境について、実例を交えてご紹介します!![]()
何を作っているのか
グループ企業のオルビスで使われている基幹システムから一部の領域を切り出し、独立した別のシステムとしてフルスクラッチで開発しています。機能追加や改善の要望が多い領域を内製化することで、ユーザーに対してアジリティ高く価値を提供することを目的にしています。
2023年から取り組んでいた領域は、複数回のリリースを経て、ついに先日正式リリースを迎えました!![]() 今年は新たな領域を開発する予定なのですが、本記事では昨年から取り組んでいた領域に関するものです。
今年は新たな領域を開発する予定なのですが、本記事では昨年から取り組んでいた領域に関するものです。
利用している技術
私たちが開発しているのは基幹システムから切り出したものなので、オルビスの方が利用する業務システムになります。ですが一般的なウェブアプリケーションのように直感的に使えるようにしたいという目標もあり、一般的に馴染みのある技術を利用しています。
- バックエンド/DB : API Gateway + Lambda (Python)、Aurora Serverless v2 (MySQL)
- フロントエンド : App Runner、Next.js (React) + TypeScript
全体としてAWSを活用したクラウドネイティブな構成となっており、完全なサーバレス環境となっています。対象が業務システムなのでアクセス頻度に偏りがあることと、一般のお客様向けのシステムよりは運用のコストを抑えたいこともあり、サーバレスなアーキテクチャを採用しています。
バックエンドはAPI Gatewayを利用してREST APIとして提供しており、実際の処理はPythonを用いてLambdaで実装しています。APIだけではなくバッチ処理もありますが、そちらもLambdaで実装しています。
今回の領域ではそこまで複雑な処理がなく問題にはなりませんでしたが、現時点でLambdaは最長15分までの処理を実行可能なので、サーバレスを活用できる範囲が広がっていますね!![]()
フロントエンドはNext.jsを利用したReactベースの実装となっており、ライブラリとしてMUI (Material UI)を利用しています。MUIはGoogleが提唱するマテリアルデザインの考え方をベースとしたコンポーネントを提供してくれるので、洗練されたデザインで統一感のあるUIを簡単に提供できるのは非常に魅力的です。
また、AWSにはApp Runnerを利用してデプロイを行っています。App Runnerはフルマネージド型のコンテナアプリケーションサービスで、インフラやコンテナの経験が無くてもアプリが構築できることが特徴です。
これは本当にその通りで、開発チームはインフラやコンテナを深く意識することなく、自部たちのアプリケーションの開発に集中できていると感じます。
開発環境
開発メンバーの環境としては、ソースコードはGitHubで管理しており、IDEにはVisual Studio Codeを利用しています。
コーディングに関するルールは各々の実装言語に沿ったリンターとフォーマッターを利用することで、意識しなくてもクリーンなコードが保てるようにしています![]()
- Python : Ruff (https://docs.astral.sh/ruff/)
- JS : ESLint (https://eslint.org/) + Prettier (https://prettier.io/)
特にリンターについてはVSCodeの拡張機能を利用してローカルで確認することに加えて、GitHubでのプルリク作成をトリガーにGitHub Actionsでもチェックしています。リンターのルールはリポジトリのルートに設定ファイルを配置することで、開発メンバー全員の設定とGitHub Actionsでの設定が全て同期するようにしています。
Pythonでの具体例として、Ruffはプロジェクトのルートに以下のような ruff.toml を配置して設定を行っています。
[lint]
# Enable Pyflakes ("F"), pycodestyle ("E"), flake8-bugbear ("B")
select = ["F", "E", "B"]
# Avoid enforcing line-length violations ("E501")
ignore = ["E501"]
# Set preview mode because import violations ("E402") supports sys.path.append
preview = true
ルールとしてPyflakes、pycodestyle、flake8-bugbearを有効にしていますが、E501 (Line too long) はプロジェクトの状況を考慮して無効としています。また、一部のimport時に sys.path.append を利用するケースがあり、こちらもプロジェクトの状況から許容したいのですがデフォルトではE402 (Module level import not at top of file)のエラーが発生します。公式ドキュメントによれば sys.path.append は preview モードでは許容されるとのことなので、preview = true の設定を追加しています。
CI/CDと自動テスト
ソースコードをGitHubで管理していることもあり、CI/CDにはGitHub Actionsを利用しています。ブランチ戦略としてgit-flowを採用しており、releaseブランチにマージされた時点でAWSへデプロイされるといった一般的なワークフローとなっています。
また自動テストにも取り組んでおり、Pythonはpytest、JSはCypressでのE2Eテストを実装しています。テストはまだまだ道半ばといった段階で、CIに組み込みたいのですが機能追加に伴って実行時間が長くなってしまう、テストのメンテナンスコストが高くなっている、という点が目下の悩みです![]()
実行時間が長いことに対する対策としては、CIに組み込めなくとも定期的に実行する、テストを並列実行して短縮する、という2つを実施しました。テストの定期実行は、GitHub Actionsの on.schedule を使うことでスケジュール実行が可能になります。例えば平日の21時から実行したい場合は、以下のような設定で実現できます。時間の設定はcronと同等のフォーマットで、UTCで指定する必要がある点に注意です。
on:
schedule:
- cron: '0 12 * * 1-5'
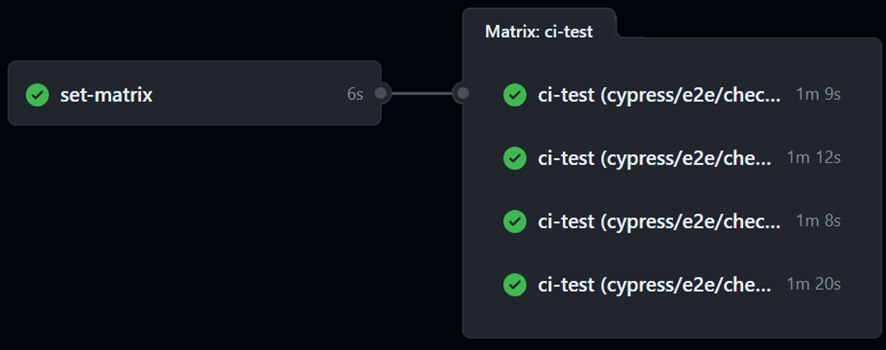
また、テストの並列実行はGitHub Actionsのマトリックスを使って実現しています。
公式ドキュメントではマトリックスを静的に定義していますが、GitHub Actionsの中で動的に設定することも可能です。実際の内容を抜粋してご紹介します。
jobs:
set-matrix:
outputs:
# 後続のジョブに渡す、動的に生成したマトリックスの内容
files: ${{ steps.set-matrix.outputs.files }}
steps:
- name: Checkout
uses: actions/checkout@v4
# テスト対象ファイルのリストアップ
# test_dirに含まれる*.cy.jsファイルを検索し、parallel_countの数でグルーピングする
# du + sortでファイルサイズ順に並べてから振り分けることで、テストの実行時間が均一化されることを期待
- name: Make matrix values
id: set-matrix
shell: bash
run: |
test_dir=cypress/e2e
parallel_count=4
test_group=()
files="files=["
test_files=($(find $test_dir -type f -name '*.cy.js' -exec du -h {} + | sort -h | awk '{print $2}'))
for ((i = 0; i < ${#test_files[@]}; i++)); do
test_group[$i % $parallel_count]+=${test_files[$i]}@
done
for group in ${test_group[@]}; do
files+=\"$group\",
done
echo "${files}]" >> $GITHUB_OUTPUT
ci-test:
needs: set-matrix
strategy:
# 並列実行されるいずれかのジョブが失敗しても、他のジョブの実行を継続するためfail-fastをfalseに設定
fail-fast: false
matrix:
# マトリックスの1要素
file: ${{fromJson(needs.set-matrix.outputs.files)}}
steps:
# マトリックスの1要素に複数ファイルが含まれる場合、@を区切り文字としている
# Cypressに複数ファイルを渡す場合はカンマ区切りでの指定だが、マトリックスの要素もカンマ区切りなので両者を区別するため
# このステップで、マトリックスの1要素に含まれる@をカンマに変換する
- name: Set test file path to env
shell: bash
run: |
echo "TEST_FILE_PATH=${{ matrix.file }}" | sed 's/@$//' | sed 's/@/,/g' >> $GITHUB_ENV
# Cypressでテストを実行する
# あらかじめpackage.jsonのscriptsに設定している内容を実行する
# "e2e": "start-server-and-test start http://127.0.0.1:3000 \"cypress run --e2e --spec \"$TEST_FILE_PATH\" \""
- name: Cypress run
uses: cypress-io/github-action@v6
with:
install: false
build: pnpm build
command: pnpm run e2e
例えばテストファイルが test01.cy.js ~ test10.cy.js という名称で10ファイル存在する場合、前述した設定でset-matrixジョブが実行されると以下の4グループに振り分けられ、マトリックスの要素として設定されます。
test01.cy.js@test05.cy.js@test09.cy.jstest02.cy.js@test06.cy.js@test10.cy.jstest03.cy.js@test07.cy.jstest04.cy.js@test08.cy.js
GitHubで実行結果を確認すると、ちゃんと並列実行されていますね!![]()
マトリックスを動的に生成することで、テストファイルが増えたときにメンテナンスを忘れて実行されていなかった、といったことが防げます。
今後の展望
現在はオルビスの基幹システムを対象に開発をしていますが、例えばECサイトなどの別の領域や、ポーラなどの他のグループ企業のシステムにも内製開発の対象を拡大していきたいと考えています![]()
最後に
いかがでしたでしょうか。ポーラやオルビスと聞くと化粧品やスキンケアのイメージが強いのでシステム開発とは程遠く、自分たちで手を動かして内製開発しているのは初めて知った!という方も多いのではないでしょうか?
この記事を通して私たちの取り組み内容を知っていただき、ご紹介した具体例が少しでも参考になれば嬉しいです。
また、弊社では一緒に働く仲間を募集しています。内製開発だけではなく、他にも様々な職種を募集しています。
カジュアル面談も随時実施していますので、お気軽にお問い合わせください!
募集内容の詳細は、是非採用サイトをご確認ください![]()