参考
https://qiita.com/maskot1977/items/082557fcda78c4cdb41f [1]
Andreas C. Muller、Sarah Guido 「Pythonではじめる機械学習」 (2017年 株式会社オライリー・ジャパン)[2]
主成分分析について
主成分分析とは、データの特徴量を相互に統計的に関連しないように座標軸を回転する時限削減の手法です。 [2]
それぞれのデータの分散が最大になるような軸を作成します。
MDシミュレーションで取得した生体分子の座標をストラクチャーアライメントの後、重要原子の座標をPCAにかけることで構造の変異を可視化することができます。
使用したライブラリ
環境は Anaconda3で構築しました。
Ubuntu18、MacOS Monterey 12.5での作動は確認しています。
MDシミュレーションはGROMACSを使用しているので、トラジェクトリーが.xtc、トポロジーが.gro形式となっています。マルチプルpdbファイルでも同様にできます。
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from mpl_toolkits.mplot3d import Axes3D
import mdtraj as md
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import matplotlib.ticker as ticker
import matplotlib.colors as mcolors
データ読み込み,座標の取得
予めCαのみの座標を抽出したトラジェクトリを読み込ませています。1フレームごとにCαの数だけ要素を持ったベクトルとしposに格納します。
t = md.load('trajctory.xtc', top='topology.gro')
pos=[sum(i.tolist(),[]) for i in t.xyz]
df=pd.DataFrame(pos)
PCA解析
ここからは[1]のコードを参考に進めます。主成分得点に関しては、[1]を参照ください。
#標準化
dfs = df.iloc[:, 0:].apply(lambda x: (x-x.mean())/x.std(), axis=0)
#オブジェクトの作成
pca = PCA()
#PCAの実行
pca.fit(dfs)
# データを主成分空間に写像
feature = pca.transform(dfs)
#寄与率
pca.explained_variance_ratio_
#累積寄与率
np.cumsum(pca.explained_variance_ratio_)
#各種成分に対する変数の寄与度
pd.DataFrame(pca.components_, columns=df.columns[:], index=["PC{}".format(x+1) for x in range(len(dfs.columns))])
PCA座標のヒートマップ
fig = plt.figure()
ax = fig.add_subplot(111)
g = ax.hist2d(feature[0:10001, 0], feature[0:10001, 1], bins = 100, cmap = cm.jet,range=[[-30,30],[-30,30]])
ax.set_xlabel("PCA1")
ax.set_ylabel("PCA2")
fig.colorbar(g[3], ax = ax)
plt.show()

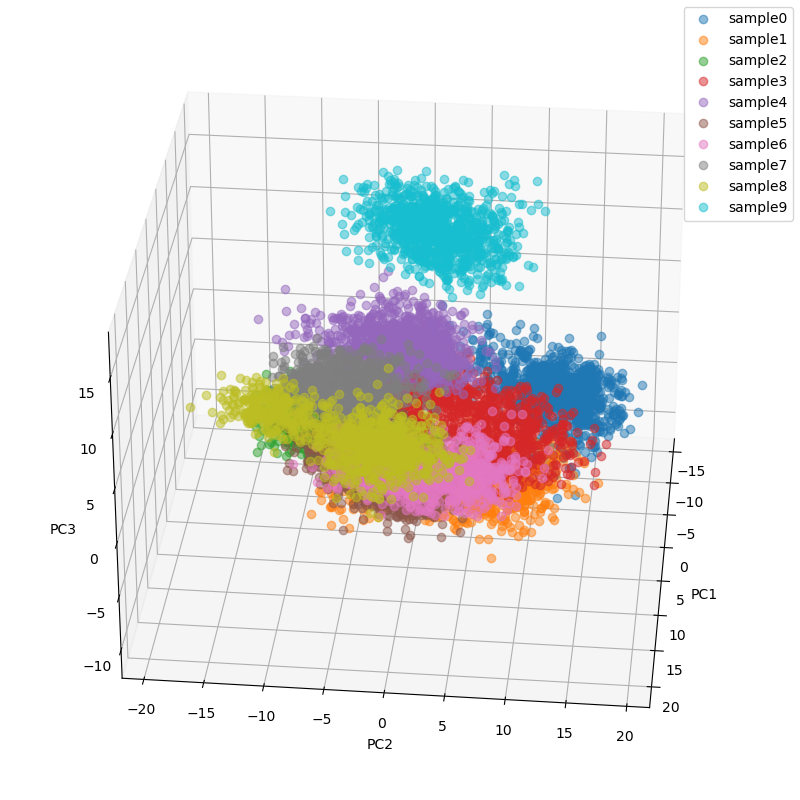
3次元描画
%matplotlib notebook
colors = list(mcolors.TABLEAU_COLORS.keys())
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw={'projection' : '3d'})
ax = Axes3D(fig)
cm = plt.cm.get_cmap('RdYlBu')
# X,Y,Z軸にラベルを設定
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_zlabel("PC3")
for i in range(10):
ax.plot(feature[i*1000+1:(i+1)*1000+1, 0], feature[i*1000+1:(i+1)*1000+1, 1],feature[i*1000+1:(i+1)*1000+1, 2],marker="o",
linestyle='None',c=colors[i],label="sample"+str(i),alpha=0.5)
# 最後に.show()を書いてグラフ表示
plt.legend()
plt.show()
最後に
私自身の技術的な覚書で、各情報を複合したものとなっています。よろしくお願いします。