word2vecを用いて自分のツイートデータを分析する第1弾です!!!
目次
- データの取得
- 前処理
- 学習
- 類似度
- おわりに
データの取得
まず、Twiterのデータを取得します。
ここでは、TwitterAPIを使うのではなく、自分のツイートデータをダウンロードする形で解析を行います。
まず、PC版Twitterを開きます。
次に、設定とプライバシーを選択します。
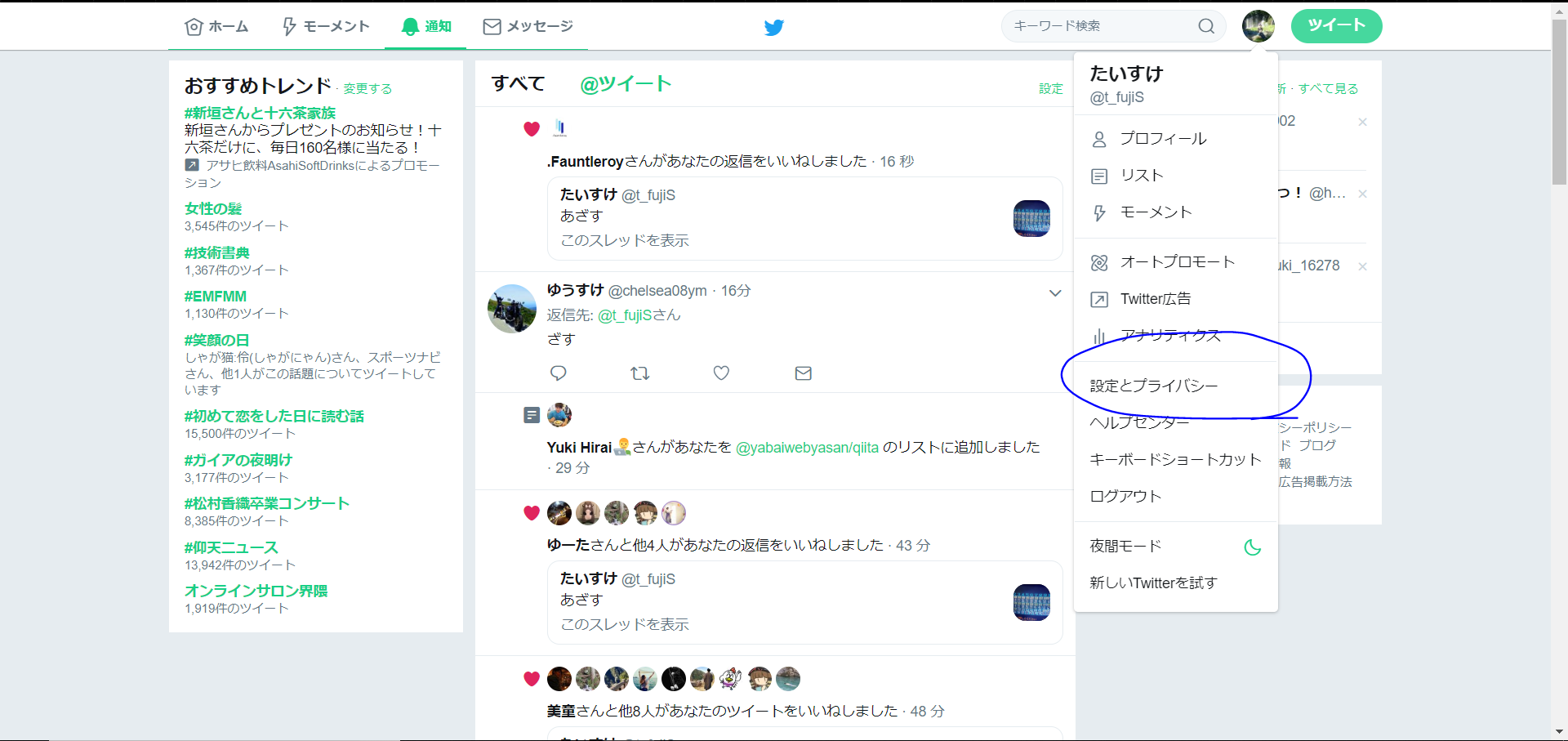
そして、Twitterデータを選択します。
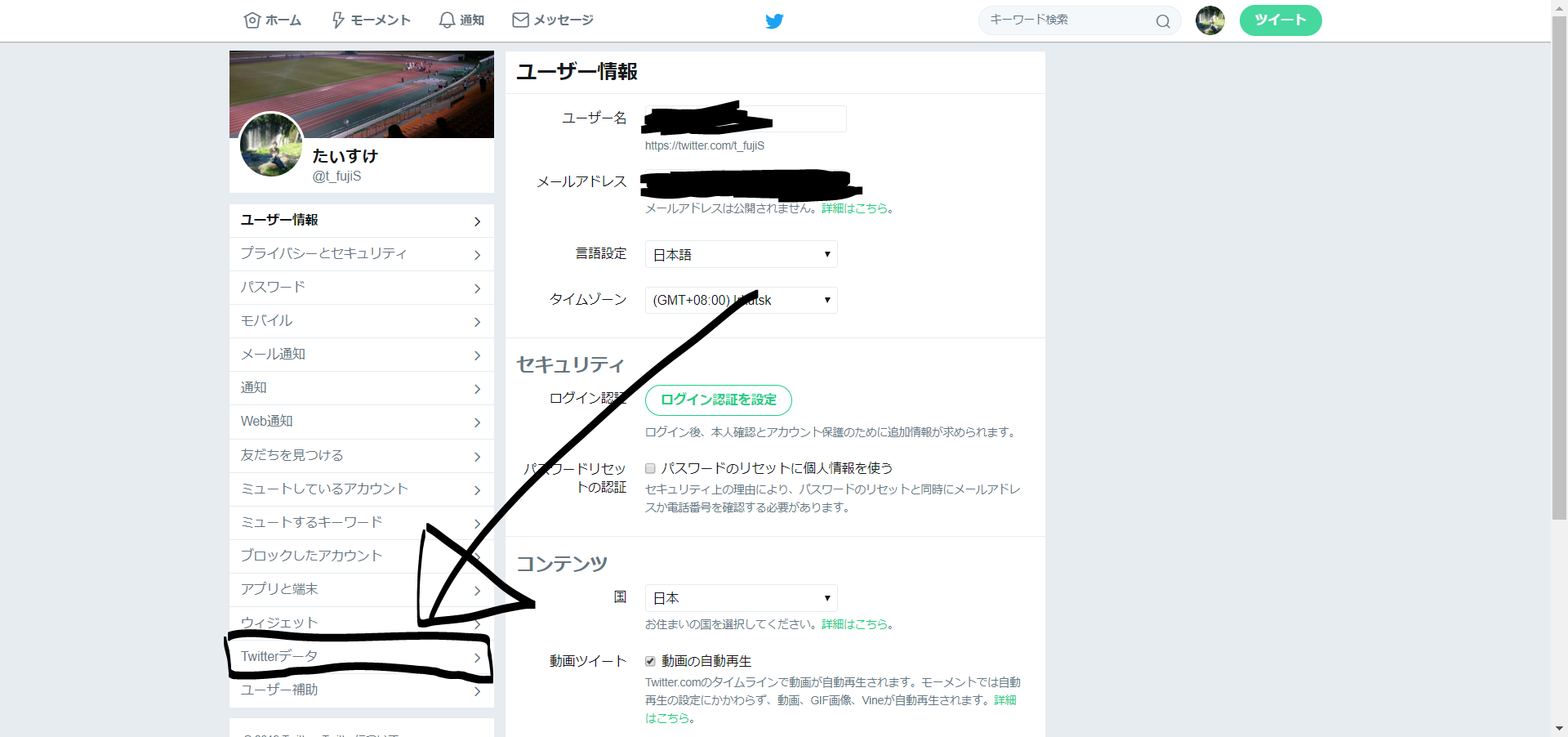
そして、パスワードの入力を求められるのでパスワードを入力します。
遷移後のページの下側にTwitterデータのダウンロードがあるのでクリックします。
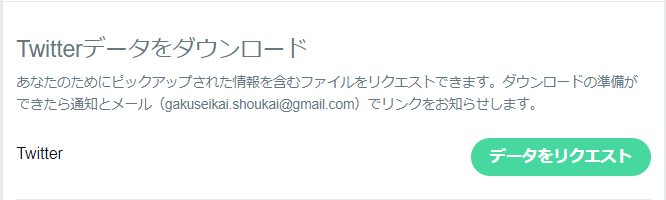
このボタンをクリック後、数分すると登録メールアドレスにzipファイルのダウンロードリンクが送られてくるのでそれをダウンロードします。
そのzipファイルを解凍すると ***.csv が出てくるのでそちらを使用します。
前処理
今回は形態素解析にjanome、解析にはword2vecを使用します。
形態素解析はMeCabが有名ですが、janomeの方がインストールが用意であることや、特に今回は高速である必要もないのでjanomeを使用します。ここは別にMeCabでも大丈夫です。
word2vecはgensimというライブラリに入っているので、
import janome
import gensim
という感じですね。インストールについては
pip install janome
pip install gensim
で大丈夫です。簡単ですね。
データを読み込みます。
import pandas as pd
import numpy as np
tweets = pd.read_csv("tweets.csv",engine = "python")
簡単ですね。engine="python"は好みです。
次に、いらないデータを削除してしまいます。
特に、今回は自分のツイート本文だけあればいいのでほかの列は削除してしまいます。
tweets = tweets.drop("tweet_id",axis=1)
tweets = tweets.drop("timestamp",axis=1)
tweets = tweets.drop("source",axis=1)
tweets = tweets.drop("retweeted_status_id",axis=1)
tweets = tweets.drop("retweeted_status_user_id",axis=1)
tweets = tweets.drop("expanded_urls",axis=1)
tweets = tweets.drop("retweeted_status_timestamp",axis=1)
[2019/02/16 追記]
そういえばこの形でスマートに削除できますね。
tweets = tweets.drop(["tweet_id","timestamp","source","retweeted_status_id","retweeted_status_user_id","expanded_urls","retweeted_status_timestamp"],axis=1)
axis=1で列の指定ができるのでdrop()でいらないものを消してしまいます。
tweets["in_reply_to_status_id"].fillna("No_data",inplace=True)
new_tweet = []
# 誰かへのリプを削除
for i in range(len(tweets)):
if(tweets["in_reply_to_status_id"][i] == "No_data"):
new_tweet.append(tweets["text"][i])
このような形で、だれかへのリプを削除します。
通常リプでないツイートには、"in_reply_to_status_id"という列にNaNが入力されています。
そのため、一度NaNをNo_dataという文字列に置き換えます(ここは好みです)。
その後、No_dataであるとき(誰かへのリプではないとき)にnew_tweetに文字列を格納します。
ツイートデータは、RTも含んでしまっています。
そのため、RTは削除する必要がありますね。(ここも好みで、実は削除する必要ない気もします)
import re
import glob
# RTを削除
data = []
pattern = r"RT"
for j in range(len(new_tweet)):
if(not(re.match(pattern,new_tweet[j]))):
data.append(new_tweet[j])
RTの際には、RTという単語が本文に入ります。
ですので、RTという文字が入っていない文字列をdataというリストに格納します。
また、リンクを含むツイートもノイズになりそうですね。
きっと消した方がいいと思います。
# リンクを含むツイートを削除
data_ = []
patterns = r"https"
for k in range(len(data)):
if(not(re.search(patterns,data[k]))):
data_.append(data[k])
悲しいことに実はリプを消せ切れていなかったのです
ということでさらなる処理を加えます。
# リプが消せ切れてなかったので
data__ = []
pattern_ = r"@"
for l in range(len(data_)):
if(not(re.search(pattern_,data_[l]))):
data__.append(data_[l])
理由はわかっていないので誰か教えてくれると嬉しいです。
形態素解析を行うtokenize()関数を定義します。
from janome.tokenizer import Tokenizer
def tokenize(text):
t = Tokenizer()
tokens = t.tokenize(",".join(text))
word = []
for token in tokens:
part_of_speech = token.part_of_speech.split(",")[0]
if part_of_speech == "名詞":
word.append(token.surface)
#if part_of_speech == "動詞":
#word.append(token.surface)
if part_of_speech == "形容詞":
word.append(token.surface)
if part_of_speech == "形容動詞":
word.append(token.surface)
return word
このようになっています。今回は名詞・動詞・形容詞・形容動詞を抜き出しています。
token.part_of_speech.split(",")[0]で品詞が取り出すことがコツですね。
これで、wordというリストにその単語たちが入っていることになります。
さて、ここまでできたので最後はまとめちゃいます
tweet_data = pd.DataFrame(data__)
tweet_data.head(120)
tweets = np.array(tweet_data)
word = ""
for text in tweets:
word += text
text = tokenize(word)
こんな感じでtextにツイートのデータを入れられました。
前処理は以上です。
学習
from gensim.models import word2vec
model = word2vec.Word2Vec([text], size=400, min_count=20, window=15)
以上です。word2vecについては以下のリンクがわかりやすい気がするのでそちらを見てください。
https://code.google.com/archive/p/word2vec/
類似度
print(model.most_similar(positive=["高専"]))
ある単語に関する類似度は、model.most_similar()で求めることができます。
[('ん', 0.9999973177909851), ('こと', 0.9999971389770508), ('の', 0.9999970197677612), ('人', 0.9999968409538269),
('マジ', 0.999996542930603), ('いい', 0.999996542930603), ('学校', 0.9999963045120239),
('ない', 0.9999962449073792), ('笑', 0.9999961256980896), ('...', 0.9999960064888)]
...
('マジ', 0.999996542930603), ('いい', 0.999996542930603), ('学校', 0.9999963045120239)
高専、マジ、いい、学校みたいです。
おわりに
こんな感じでゆるっとword2vecを用いた分析を行ってみました。
次回は、このデータをもとにLSTMかCNNを使ってネガポジ分類とかやってみたいと思います。