はじめに
みなさんこんにちは。このブログでは、2022年12月 (re:Invent直後) に発表された SageMaker Canvas の新機能である、モデル持ち込み機能 (BYOM; Bring Your Own Model) について深ぼってみたいと思います。
SageMaker Canvas について
SageMaker Canvas について詳しく説明するのがこのブログの趣旨ではないので手短に。
SageMaker Canvas は、いわゆる no-code の機械学習のサービスです。データを準備すれば、簡単な前処理、モデルの学習、学習したモデルの分析(混合行列見たりなど)、そして推論(リアルタイムもバッチも両方)を コードを書かずに 実現することができます。
コードを書かなくても良いことがポイントなので、想定しているユーザーは、非エンジニアや、エンジニアだが手軽に機械学習を回したい方々ですね。
SageMaker Studio (Canvas ではなく) がチョットワカル人向けですが、SageMaker Canvas のインフラ部分は SageMaker Studio の "domain" 上に実装されているので、ユーザー管理やリソース管理は SageMaker Studio と非常に近いです。ユーザーごとに Canvas の UI 環境と計算環境、ストレージ環境が立ち上がり、そこに対して課金が発生する形です。
詳細は公式ホームページと公式ドキュメントをご覧くださいませ。
SageMaker Canvas BYOM の概要
SageMaker Canvas BYOM について少しだけ登場の背景を説明します。これまで SageMaker Canvas を利用した モデルの活用方法 として以下の 2 つありました。
- Canvas 内でモデルを学習し、Canvas 内で分析・推論する
- Canvas 内でモデルを学習し、Canvas 外(例えば、SageMaker Studio や Amazon QuickSight)で分析・推論する
どちらもモデルの学習は Canvas 内である必要がありました。
新しい機能は、「Canvas 外でモデルを学習し、それを Canvas 内で分析・推論などの活用ができるようになった」というところが嬉しいポイントですね。
もう少し細かい概要については、公式ブログや公式 What's New や公式ドキュメントを読んだ方が正確かつわかりやすいと思うので割愛します。
SageMaker Canvas BYOM の深堀りまとめ
後半で実際のコードを記載していますが、まずは結論として、個人的に気になった点などをまとめます。
- 2023年2月現在では、公式ドキュメントに、持ち込みたいモデルの入出力の仕様がまとまっていない
- 検証すると、入力は 1 次元または 2 次元を考慮する必要がありそう
- 検証すると、出力は JSON で、構造として AutoGluon が出力する 3 つのキーに値を入れる必要がありそう
- SageMaker Canvas への import 失敗とエラーは、SageMaker Canvas の UI 側で表示されるので、例えば非エンジニアの SageMaker Canvas へモデルを import する際は、まずはエンジニアのユーザーで import を試してからが良さそうである
特に 2 点目、3 点目において、具体的にどのような設定を行えば import できるのか試してみます。
試してみる
まず具体的な手順を整理します。
- モデルは Kaggle の Titanic とする
- Kaggle の Titanic の公開している notebook の中で、最も評価の高いものをコピーする
- SageMaker Studio で上記の notebook を実行する
- 実行してできたモデルをファイル (
model.tar.gz) に出力する - モデルが正しく動作するか、SageMaker Endpoint を起動し、確かめる
- 正しく動作するならば、公式ドキュメントに従い、モデルを SageMaker Model Registry に登録する
- 登録後、公式ドキュメントに従い SageMaker Canvas へ共有する
- SageMaker Canvas で共有が成功したか確認する
- SageMaker Canvas でモデルの分析結果を確認する
- SageMaker Canvas で推論する
10 ステップですね。。。意外と長くなりました。順番に実行していきます。
1. モデルは Kaggle の Titanic とする
なるべくシンプルにしつつ、Canvas でちゃんと分析結果を見るために、今回は機械学習界隈では有名な Kaggle の Titanic のモデルを使うことにしました。NumPy とかで 2x2 行列をモデルとすることも考えましたが、おそらく Canvas に import した後虚無感がありそうだなと。
2. モデルは最も評価の高い notebook をコピーする
イチからモデルのコードを実装するのは面倒なので、既存のものを拝借します。適当に Kaggle で公開されている最も評価の高いこちらの notebook をコピーします。右上の 3 点メニューから "Download code" をクリックし、手元の PC にダウンロードしておきます。
更に、Kaggle の Titanic の学習データとテストデータも問題ページからダウンロードしておきます。
3. SageMaker Studio で notebook を実行する
ここから SageMaker Studio で操作を行っていきます。実際の操作に移る前に、環境の前提を整理しておきます。
- SageMaker Studio の domain 上に最低 2 ユーザーがいる前提
- ユーザー 1 の名前は、今回は
user1とする - ユーザー 2 の名前は、今回は
user2とする - ユーザー 1 の SageMaker Studio notebook 上でモデルを作成する
- ユーザー 2 の SageMaker Canvas 上でモデルを import する
上の前提なので、notebook を実行するのは user1 です。
疑問として、「わざわざユーザーを分けずに、同じユーザーの Canvas に共有すればいいのでは?」、と思われるかもしれませんが、Studio から Canvas へ共有する際に、ユーザーが同じだとエラーとなったため、ユーザーを分けている形です。
SageMaker Studio を開いたら、先程ダウンロードした notebook と CSV データを drag-and-drop で SageMaker Studio にアップロードします。
アップロードした notebook を開きます。Kernel は Python 3 (Data Science)、Instance Type は ml.t3.medium で問題ないでしょう。そうしたら、上のセルから順番に実行していきます。が、ここで注意です。上から 2 つ目あたりのセルで CSV ファイルを Pandas dataframe として読み込んでいるコードがあるのですが、ここを適切なパスに変更してください。もし、notebook と同じ directory に CSV ファイル置いている場合は、次のようなコードになります。
train_df = pd.read_csv('./train.csv')
test_df = pd.read_csv('./test.csv')
combine = [train_df, test_df]
ここだけ変更したら、あとは最後のセルまで無心で実行していきます(Jupyter の一括実行でもいいです)。
4. モデルをファイルに出力する
先程実行した notebook のコードの最後の方を読むと、どうやら Random Forest で学習したモデルが最も良さそう、という結論になっています。ということで、このモデルをファイルとして出力します。
次のコードを、同じ notebook にセルを追加して実行していきます。
import joblib
import os
import tarfile
joblib.dump(random_forest, './model')
with tarfile.open('model.tar.gz', 'w:gz') as tar:
tar.add('./model')
わざわざ tar ファイルにして gzip で圧縮しているのは、SageMaker の仕様のためです。
5. モデルが正しく動作するか確認するために SageMaker Endpoint を起動する
SageMaker Canvas BYOM で、モデルを SageMaker Canvas へ import するためには、モデルを SageMaker Model Registry に登録する必要があります(SageMaker JumpStart や SageMaker Autopilot を利用すれば登録不要ですが、今回は「自分で作成したモデル」を利用したいので登録は必須)。SageMaker Model Registry の詳細は公式ドキュメントを参照希望ですが、SageMaker Canvas BYOM に関連するポイントは次の 2 点です。
- 登録する際に、モデルファイルが置かれている S3 bucket/key を指定する
- 登録する際に、モデルが動作するコンテナイメージの ECR repository を指定する
SageMaker Canvas モデルへ import した後にデバッグするのは、明らかにツラそうなため、import 前にモデルが「正しく」動作するか確認したいと思います。確認方法は、SageMaker Endpoint へのデプロイと、実際に推論リクエストを送ることで実施します。
ではやっていきましょう。
今回拝借した notebook は、モデルを Scikit-learn で作成しています(コードを読むとわかります)。そうなると、SageMaker Python SDK の Scikit-learn 用の SKLearnModel クラスを利用するのが良さそうです。クラスのリファレンスを読むと、モデルファイルが置かれている S3 bucket/key と、推論コードが必要なことがわかります。それぞれ model_data と entry_point 引数ですね。ということで、まずは、先程 tar.gz に固めたモデルファイルを S3 にアップロードします。
アップロード先の S3 bucket はどこでも良いのですが、よくある SageMaker のサンプルコードよろしく SageMaker Python SDK の default bucket を今回も使います。
import sagemaker
bucket = sagemaker.session.Session().default_bucket()
そしてモデルを AWS CLI でアップロードします。パスは適当なので、よしなに変更ください。
!aws s3 cp model.tar.gz s3://{bucket}/canvas/byom/titanic/model.tar.gz
続いては推論コードです。さて、SageMaker Canvas BYOM を利用する際は推論コードの実装がポイントになります。今回のモデルを、単に SageMaker Endpoint にデプロイしたい場合は次のコードで動作します。
# !!!!!!!! 注意 !!!!!!!! この推論コードでは SageMaker Cavnas BYOM は動作しません!
import joblib
import os
def model_fn(model_dir):
return joblib.load(os.path.join(model_dir, 'model'))
余裕がある方は、試しにこの推論コードを inference.py にし、デプロイして推論してみてください。おそらく問題なく動作するはずです。しかし、この推論コードでは SageMaker Canvas へのモデル import は失敗します。失敗するのは、SageMaker Canvas が想定しているモデルの入出力と推論コードの入出力が合っていないためです。では、SageMaker Canvas が想定している入出力は何か?という話になりますが、実は(まだ)ドキュメントにまとまっていないので、少なくとも私の環境で試した結論だけお伝えしたいと思います。
まず入力は大きく 2 つの場合を考慮する必要があります。
- (B, N) という 2 次元の入力。B はバッチサイズ。N は入力の特徴量のサイズ。
- N という 1 次元の入力。N は入力の特徴量のサイズ。
特に 2 つ目がポイントで、(1, N) という入力にしてほしいところですが、どうも SageMaker Canvas では単一推論リクエストでは、入力を 1 次元のリストとして投げてしまうらしいです。
続いて出力。こちらは形式が重要です。
- 出力形式は JSON
- JSON には 3 つのキーが必要
predicted_labelprobabilityprobabilities
調べると、3 つのキーはどうも SageMaker Autopilot の出力形式の一部であるように推測できます。入れ込む内容も同じで行けました。
さてさて、この入出力の仕様に従って推論コードを実装していきます。具体的には predict_fn 関数を追加します。predict_fn って一体全体なんなんだ!という方は SageMaker の Black Belt の推論パートに目を通してもらえると理解できるかと思います。
先程の推論コードには model_fn 関数しか実装していませんでした。predict_fn 含め、他 3 つの関数はどうなっているんだ?という疑問をいだくかもしれません。実は、SKLearnModel クラスを利用すると、推論用のコンテナイメージとして Scikit-learn 用にカスタマイズされたものが利用され、推論コードも、関数の実装がない場合、デフォルトの関数が呼ばれる仕組みになっています。デフォルトの関数はこちらのGitHubで確認できます。
次の推論コードが、SageMaker Canvas BYOM で正しく動作するものです。
import joblib
import os
import numpy as np
def model_fn(model_dir):
return joblib.load(os.path.join(model_dir, 'model'))
def predict_fn(input_data, model):
if input_data.ndim == 1:
print('INFO: input_data.ndim was 1. Reshaping to np.array([input_data])')
input_data = np.array([input_data])
elif input_data.ndim > 2:
raise ValueError('ERROR: input_data.ndim was larger than 2. It must be 1 or 2.')
predicted_label = model.predict(input_data).tolist()
proba = model.predict_proba(input_data)
probabilities = proba.tolist()
probability = proba[:,1].tolist()
output = {
'predicted_label': predicted_label,
'probability': probability,
'probabilities': probabilities,
}
return output
predict_fn 関数の出力は Python の辞書型 (dict) になっていますが問題ありません。デフォルトの output_fn が正しくこれを JSON に変換してくれます。この推論コードを inference.py という名前で保存しておきます。
これでようやく準備が整ったので、実際に SageMaker Endpoint へデプロイします。
import sklearn
from sagemaker.sklearn.model import SKLearnModel
model = SKLearnModel(
model_data=f's3://{bucket}/canvas/byom/titanic/model.tar.gz',
role=sagemaker.get_execution_role(),
entry_point='./inference.py',
framework_version='0.23-1',
py_version='py3',
)
predictor = model.deploy(initial_instance_count=1, instance_type='ml.m5.xlarge')
上記を実行して数分待つと ----! と表示されて、デプロイが完了します。続いて推論リクエストを投げてみます。
predictor.deserializer = sagemaker.deserializers.JSONDeserializer()
predictor.predict(np.array(X_test)[:10])
predictor の deserializer はデフォルトでは NumpyDeserializer となってしまっているので、JSONDeserializer に変更しています(出力の形式は NumPy array じゃなくて、JSON なので)。推論結果として、正しく 3 つのキーがある JSON が返ってくるはずです。
これで、モデルが正しく動作することが確認できました。次は、このモデルを SageMaker Model Registry に登録します。
6. モデルを SageMaker Model Registry に登録する
登録は簡単です。次のコードを実行します。
model_package = model.register(
content_types=['text/csv'],
response_types=['application/json'],
inference_instances=['ml.m5.xlarge'],
transform_instances=['ml.m5.xlarge'],
model_package_group_name='sklearn-canvas-pkg-grp-sample',
approval_status='Approved',
)
正しくモデルが SageMaker Model Registry にアップロードされたか確認するには、SageMaker Studio の UI もしくは AWS CLI (API) で確認します。SageMaker Studio の UI の場合は、左の navigation bar の🏠マークから Models > Model registry と選択し、Model group name に sklearn-canvas-pkg-grp-sample があれば成功です。sklearn-canvas-pkg-grp-sample をクリックすれば、version 1 の model package が存在しているはずです。CLI の場合は次を実行し、sklearn-canvas-pkg-grp-sample の model package group があれば成功です。
# Jupyter notebook の cell 実行想定です。
!aws sagemaker list-model-package-groups
念の為に、model package も確認しておきましょう。
# Jupyter notebook の cell 実行想定です。
!aws sagemaker list-model-packages --model-package-group-name sklearn-canvas-pkg-grp-sample
SageMaker Model Registry への登録が完了したので、続いては SageMaker Canvas への共有を行います。
7. モデルを SageMaker Canvas へ共有する
モデルを SageMaker Canvas へ共有するためには、SageMaker Studio の UI が必須になります。先程のセクションのモデルアップロードの確認と同じように、左の navigation bar の🏠マークから Models > Model registry と選択し、Model group name が sklearn-canvas-pkg-grp-sample のものをクリックします。すると、version 1 の model package が下図のように確認できるはずです。

この version 1 の model package を SageMaker Canvas へ共有していきます。このページで、version 1 の行をクリックします(特に画面遷移もなく、フィードバックも薄いですがクリックすれば選択されます)。この状態で、右上の Share ボタンをクリックすると、次のような画面が出ます。
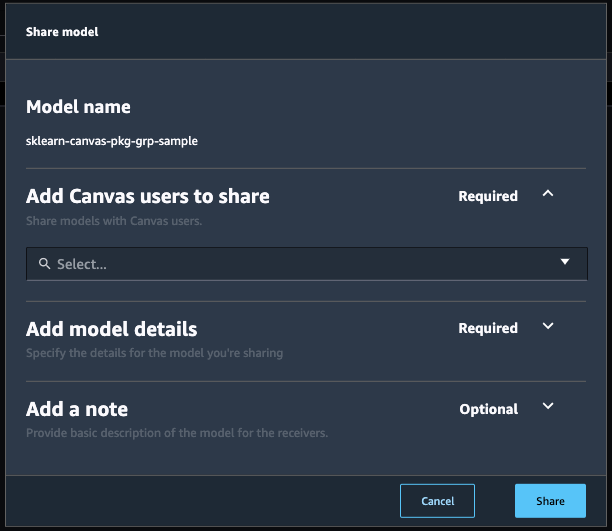
早速、上から順番に入力していきます、と言いたいところですが、一旦 Cancel をクリック して閉じてください。ここまで一切説明していませんでしたが、モデルを SageMaker Canvas へ共有するためは、SageMaker Model Registry に登録したモデルに加えて、SageMaker Canvas がモデルの分析に利用する学習データ (CSV) と評価データ (CSV) が必要となります。この学習データと評価データは S3 に置かれていることが前提なので、まずはこれらを準備をしてから、改めて先程の画面に戻ります。
学習データは、モデルの学習時に入力したものをそのまま再利用しましょう。拝借した notebook では train_df という変数に学習データが Pandas dataframe として保存されているので、これを CSV に出力します。
import csv
train_df.to_csv('./train-cleaned.csv', index=False)
今作成した train-cleaned.csv の中身を見てみます。SageMaker Studio であれば (Jupyter であれば) CSV のファイルをそのまま開くことができるので、navigation bar から train-cleaned.csv をクリックして開きます。開くと、一行目が列名となっていること、一列目が目的変数 (target) の Survived になっていることがわかります。では、このファイルを S3 にアップロードします。
!aws s3 cp ./train-cleaned.csv s3://{bucket}/canvas/byom/titanic/train-cleaned.csv
本来ならば、学習データとは別の評価データ (validation data) も用意してアップロードする必要がありますが、今回は動作確認とのことで、同じものを利用します。
それでは、再度 navigation bar の🏠マークから Models > Model registry と選択し、Model group name が sklearn-canvas-pkg-grp-sample のものをクリック、さらに vesion 1 の model package をクリックし、右上の Share ボタンをクリックします。上から順番に入力していきます。
- Add Canvas users to share
- ここには
user2のみを選択します。user1つまり自分自身も選択可能ですが、選択するとエラーになるので注意です。
- ここには
- Add model details
- Training dataset
- ここには
s3://{bucket}/canvas/byom/titanic/train-cleaned.csvと入力します。 -
注意!
{bucket}はご自身の notebook で出力して、展開したものを入力してください(そのまま{bucket}じゃなく)。
- ここには
- Validation dataset
- ここにも
s3://{bucket}/canvas/byom/titanic/train-cleaned.csvと入力します(Training datasetと同じ)。
- ここにも
- Target column
- Use the first column を選択します。
- 先程
train-cleaned.csvを確認したように、学習データの1列目が目的変数に対応しています。
- Column header
- Use the first row を選択します。
- 先程
train-cleaned.csvを確認したように、学習データの1行目がヘッダー(列名)に対応しています。
- Problem type
- Binary classification を選択します。
- Training dataset
- Configure model outputs
- User mapping relation file のトグルはオフにします。
- 0:
Not Survivedと打ち込みます - 1:
Survivedと打ち込みます
上記すべて入力したら、右下の Share をクリックします。すると右上に下記のようなバナーが表示されるはずです。

もし失敗した場合は、入力項目を再度チェックしてみてください。SageMaker Studio からのモデル共有は成功したので、SageMaker Canvas 側で正しく共有されているか確認しましょう(次へ)。
8. SageMaker Canvas でモデルの共有が成功しているか確認する
ここからは SageMaker Canvas の画面を操作していきます。これまで user1 で操作していましたが、SageMaker Canvas は user2 で操作する必要があります。同じブラウザで、user2 で SageMaker Canvas の画面を開いてしまうと user1 で操作している SageMaker Studio からもログアウトしてしまうので、引き続き SageMaker Studio の画面も同時に確認したいかたは、別のブラウザなどで SageMaker Canvas を開くのがオススメです。
SageMaker Canvas の画面を開くと、左下に下記のようなバナーが表示されているはずです(手元環境だと user-2 から user-1 へ共有してしまったので、表示があれですが、気にしないでください)。表示されていれば、View All をクリックします。もし表示されていない場合は、左の navigation bar で Models をクリックしてモデル一覧を表示します。

モデル一覧を表示すると sklearn-canvas-pkg-group-sample という名前のモデルが存在するはずです。Import 中ならば "importing" という表示されるはずです。Import が完了すれば "Ready" と表示されるはずです。私の環境では次のように表示されていました。

モデルの共有が成功したので、次はモデルの分析結果を見てみます。
9. SageMaker Canvas でモデルの分析結果を確認する
モデル一覧のページで import が完了した sklearn-canvas-pkg-group-sample をクリックします。すると "Analyze" タブに移動します。

この画面で分析できる項目などは通常の SageMaker Canvas と共通ので、ここでは深ぼりません。興味ある方はドキュメントやブログなどを参照ください。
10. SageMaker Canvas で推論する
分析同様に、BYOM のモデルで推論を行うこともできます。右上の "Predict" もしくは "Predict" タブをクリックします。通常の SageMaker Canvas 同様にリアルタイム推論もバッチ推論も可能です。好きなように値を変更しながら、SageMaker Canvas BYOM を味わいましょう。

さいごに
まとめです。SageMaker Canvas BYOM は、Canvas 外でモデルを学習し、そのモデルを Canvas へ import し、no-code で分析・推論できる機能です。機械学習エンジニアが作成したモデルを、非エンジニアの方などへ共有して見てもらう際に非常に使いやすい機能であると感じしいます。
SageMaker Canvas BYOM は2022年12月に発表された、(ブログ執筆時点では)比較的新しい機能です。公式ドキュメントや公式ブログにおいて、完全に揃いきっていないように感じています。特にモデルの入出力周り(このブログのセクション 5で記述した内容)は、ハマりやすい箇所ですが、このあたりの記載はまだまだこれからという印象です。
このブログの内容を参考に、皆さんも試してみてください。それでは。