IBM Cloud Paks シリーズは、Experienceでお試しができますが、
AI機能のFor Data に続き、第2弾として、Automationが出たので、試してみます。
以下のIBM Cloud paks Experience サイトに Automationが追加されており、ここから試せます。
https://www.ibm.com/cloud/paks/experiences/cloud-pak-for-automation
IBM Cloud paks for Automationの概要は以下の紹介ページを見て頂くとして、
https://www.ibm.com/jp-ja/cloud/cloud-pak-for-automation
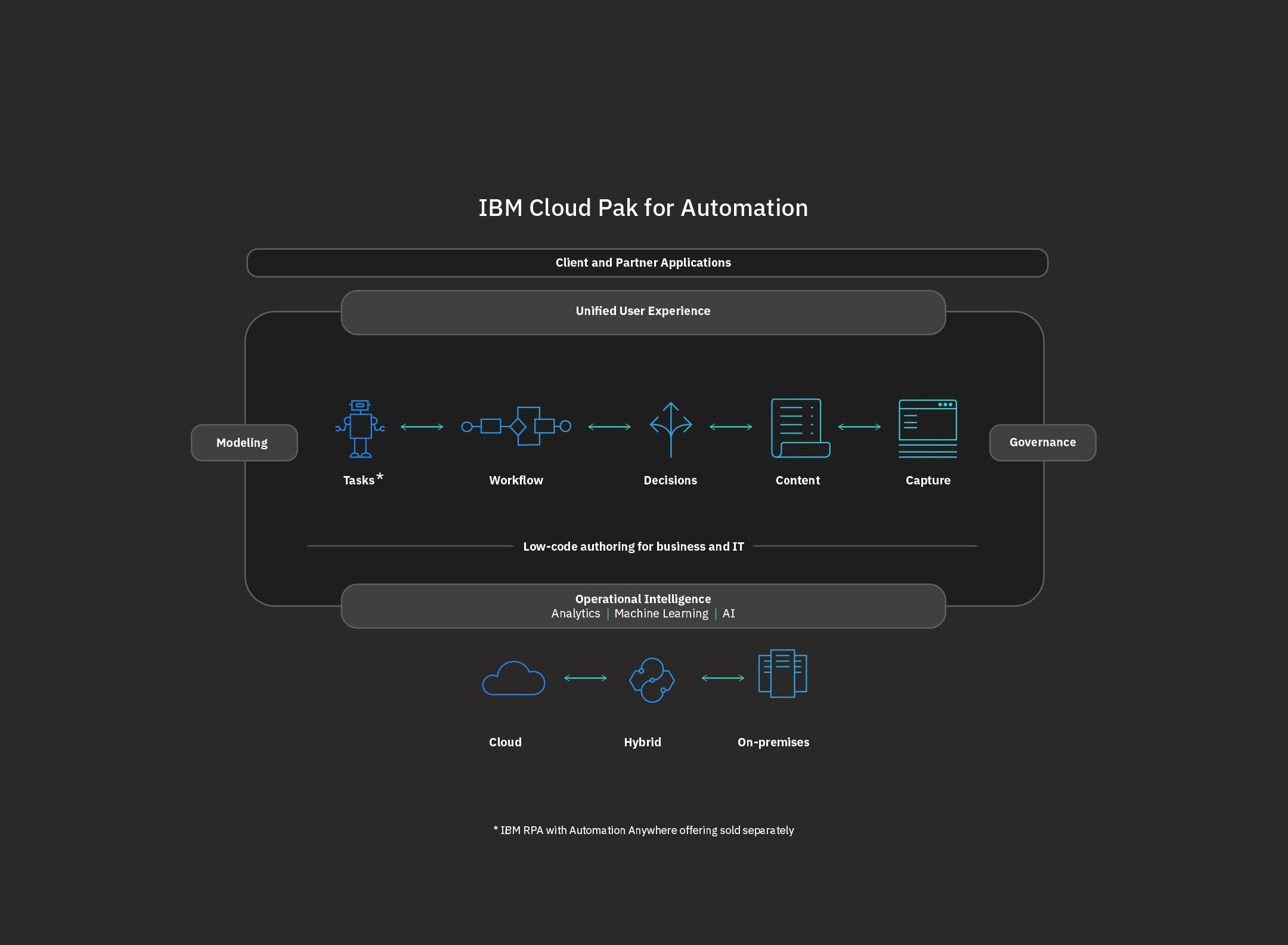
アーキテクチャーは以下となり、コンテンツに対して、ワークフローを構成することが可能であり、
それで意思決定プロセスを実装し、自動化することができます。
この対象コンテンツには非構造化データも含まれこれを構造データとして解析(OCR)やAIに組み入れる仕組みまで実装されています。
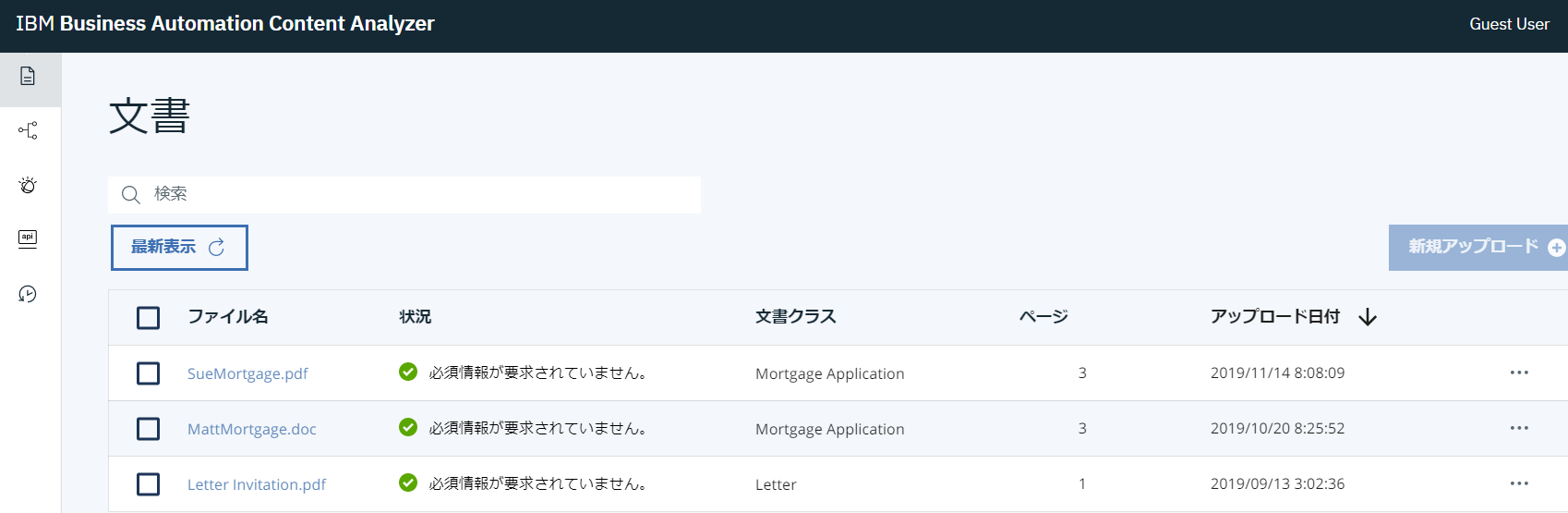
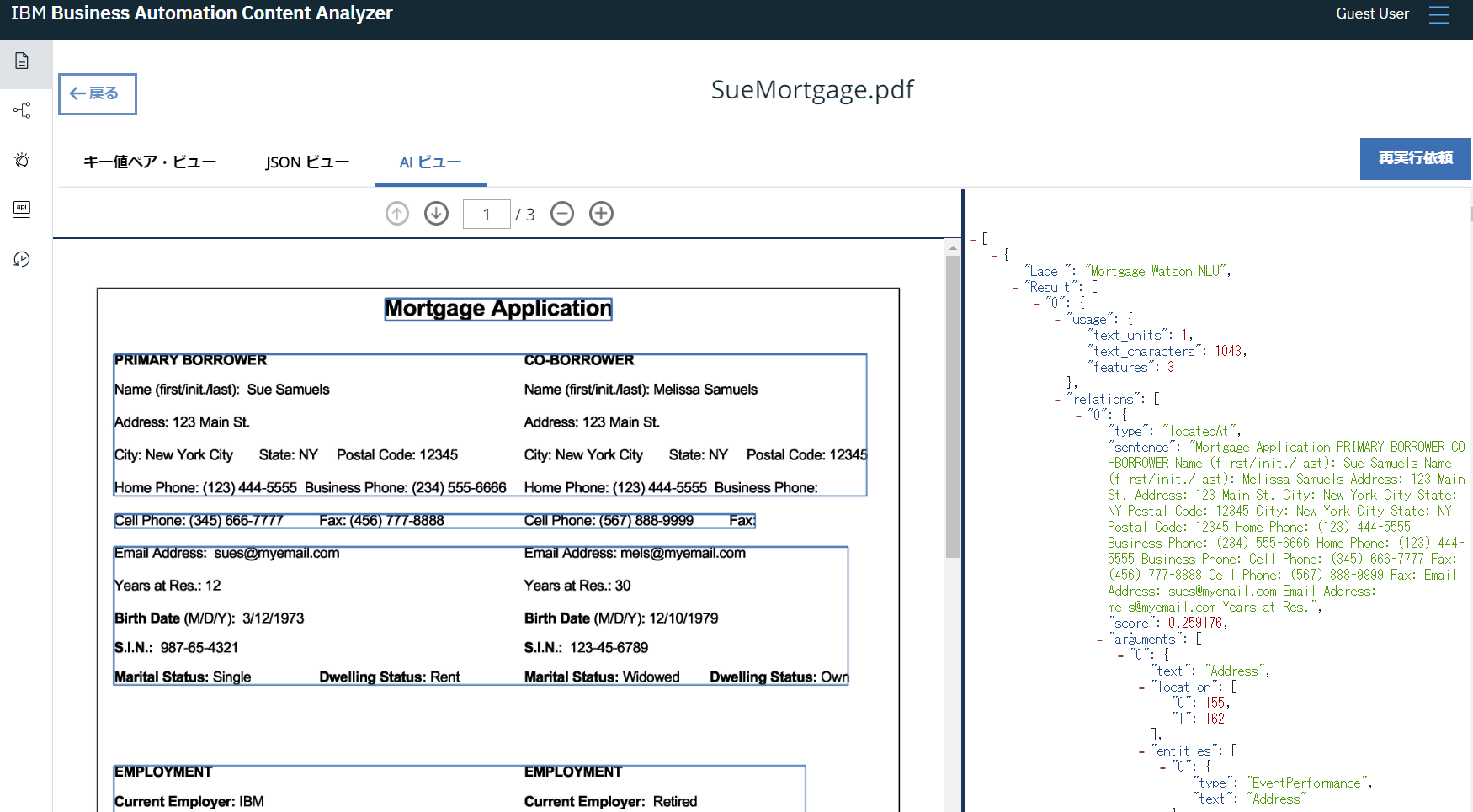
IBM Cloud paks for Automationで認識されているコンテンツは文書で確認することできます。
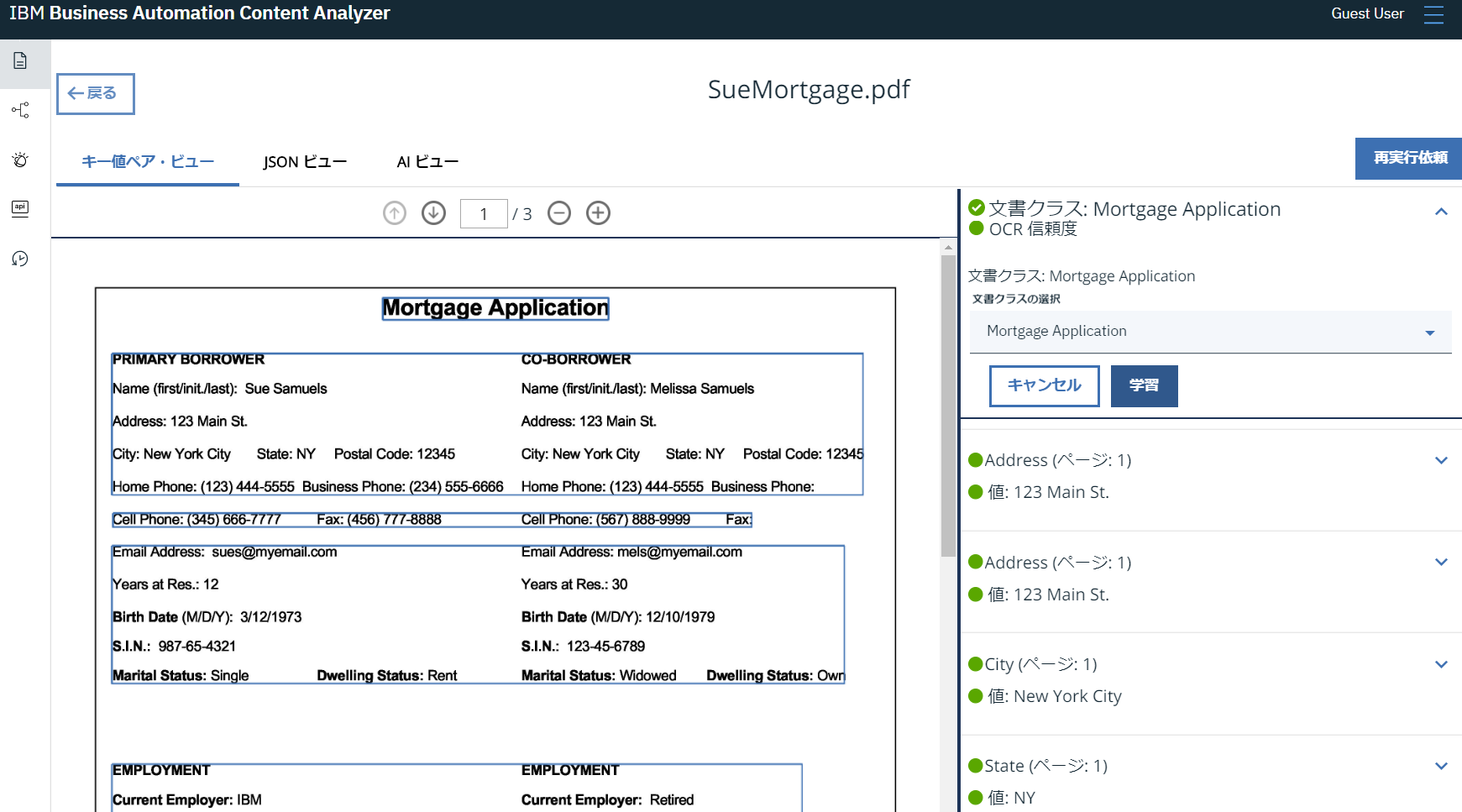
非構造データ形式であるPDFの文書をテキストマイニングし、KVSの形で構造化している例でです。
個別の属性ごとに学習データとして組み込むことができます。
JSON化も可能です。
Watson Natural Language Understanding が内部にあり、AIデータとしても構造化できます。
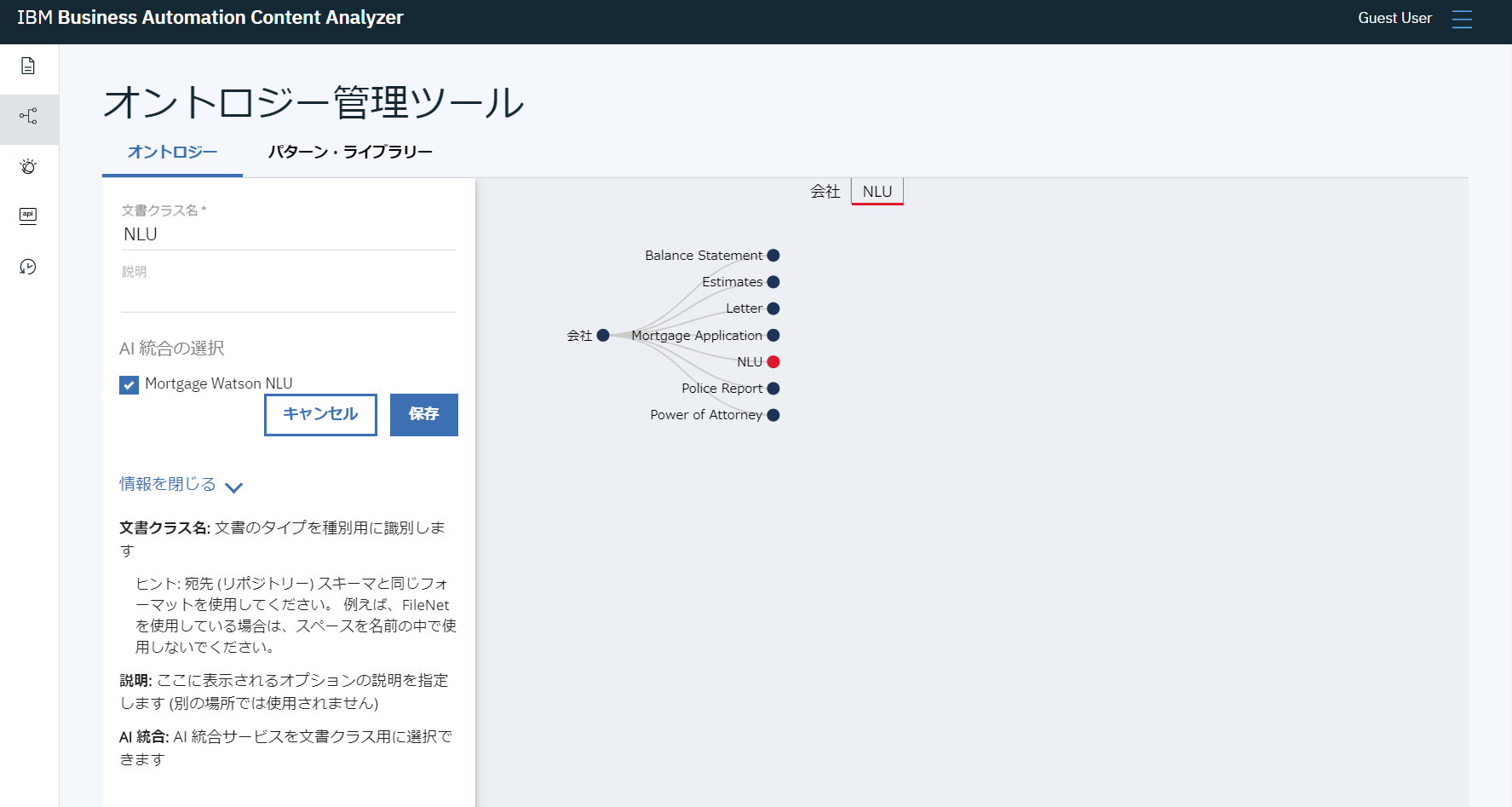
学首したデータをOntologyの構造化モデルとして表現することもできます。
以下の例では、トップ階層の文書クラスはコンテンツファイル単位ですが、
同じ階層にNLUという文書クラスを追加します。
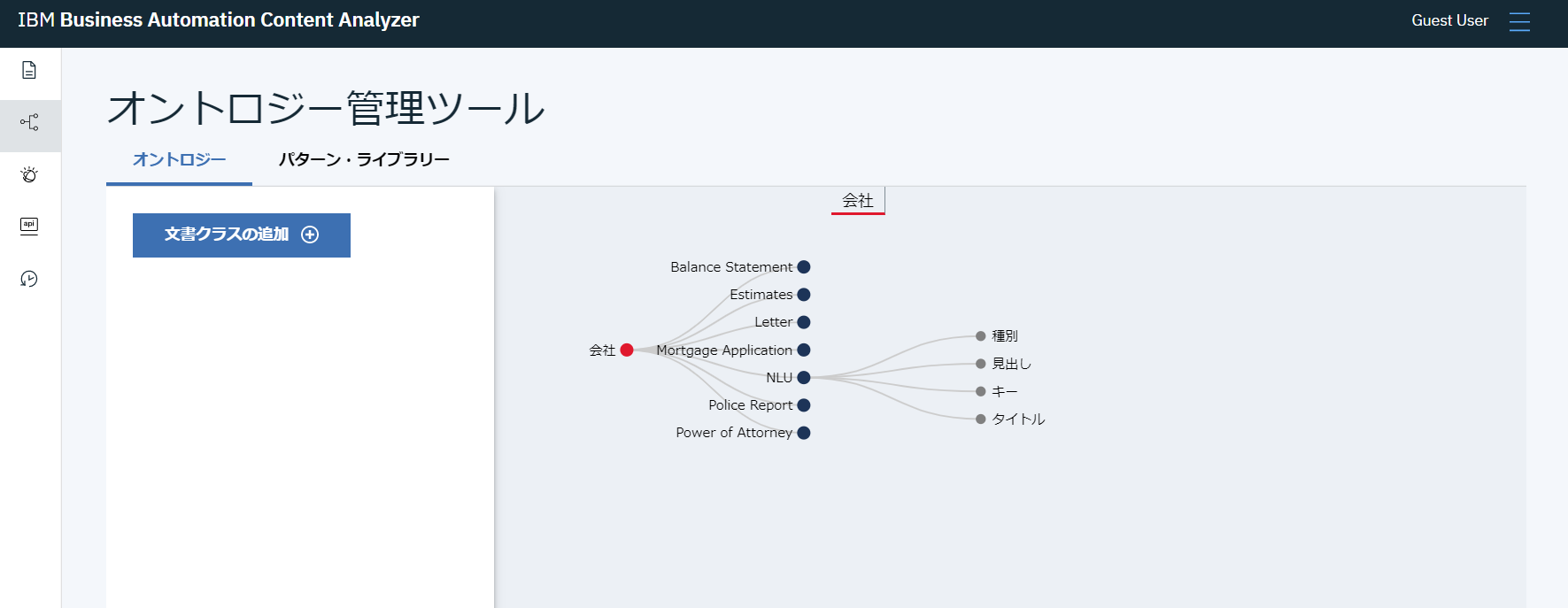
追加すると、下の階層に学習したクラスが分岐で追加されます。
Contens AnalyserのPythonサンプルは以下から確認できます。
https://github.com/ibm-ecm/content-analyzer-samples
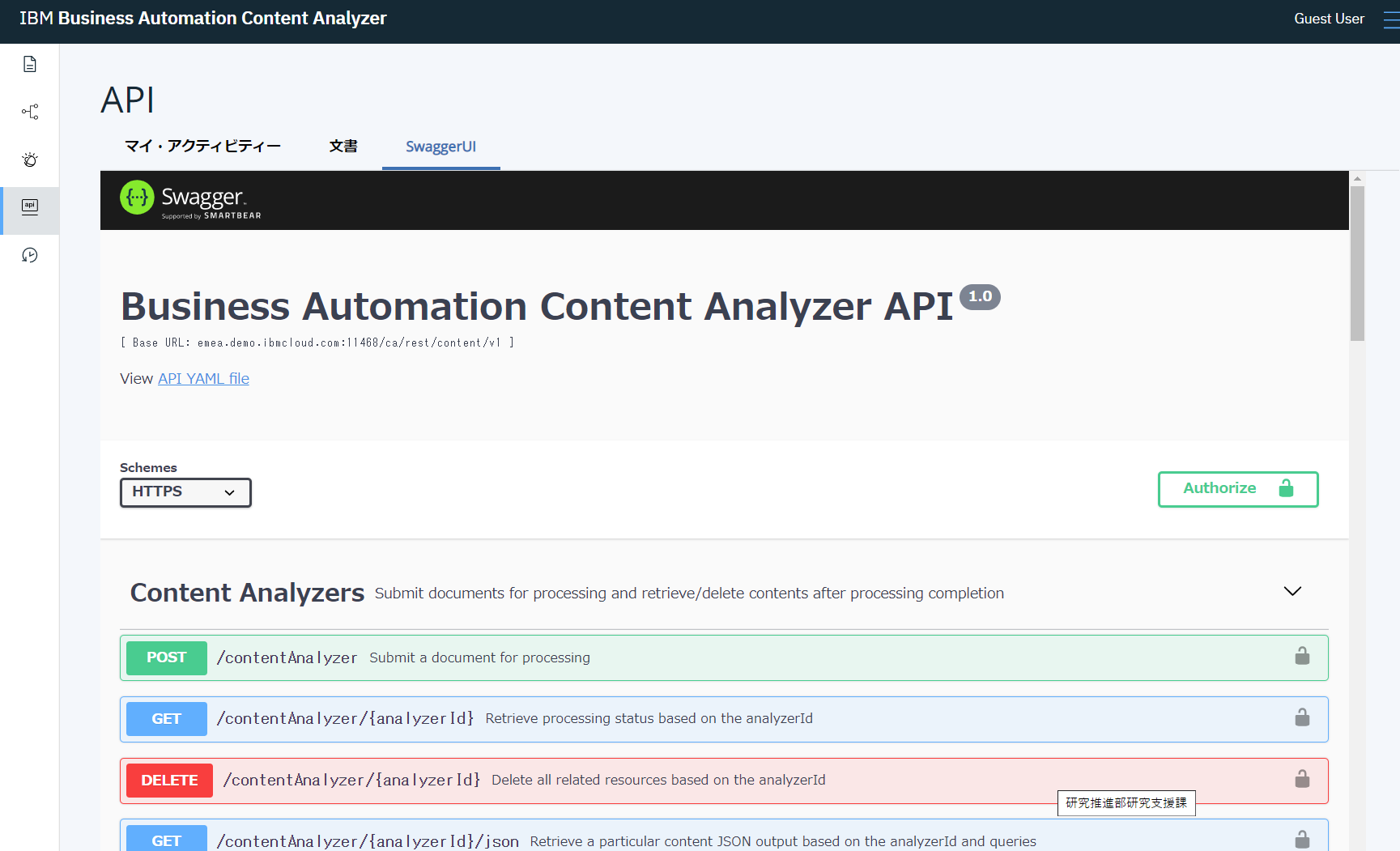
また、これらの操作はAPI操作が可能で、Swaggerも提供されています。
ぜひ、IBM Cloud paks for Automation のお試しと実装を。