この記事は弁護士ドットコムアドベントカレンダーの20日目の記事です![]()
みなさん。こんにちは
クラウドサインの SRE チームで働いております。 @t2ynkmr です。
Aurora のカスタムエンドポイントの挙動を掴みづらく利用を断念した話をします。
なお、この記事で記載される Aurora MySQL は基本的に 2.10 系となります。
TL;DR
- カスタムエンドポイントを利用する場合、フェイルオーバーでプライマリインスタンスがメンバーに含まれることがある
- ただカスタムエンドポイントのタイプ次第でプライマリインスタンスへの接続を制御できる(と思われる)
クラウドサインと Aurora について
クラウドサインは AWS でインフラを構成しており、データベースには Amazon Aurora MySQL (以下 Aurora)を採用しています。
Aurora は接続先としてデフォルトでクラスターエンドポイントとリーダーエンドポイントと呼ばれるエンドポイントを提供しています。
それぞれ以下です。
- クラスターエンドポイント: 書込み可能な接続先(プライマリ DB インスタンスへ接続する)。ライターエンドポイント
- リーダーエンドポイント: 参照用途で利用される接続先(レプリカ DB インスタンスに接続する)
これらを利用することで、フェールオーバーの際のプライマリの入替えや負荷分散に関してアプリケーション側に意識させることなく接続可能です。
すばらしいですね。ブラボー ![]()
クラウドサインでは以下のような基本的な構成で利用しています。

Aurora では上記以外にもカスタムエンドポイントと呼ばれるエンドポイントが提供されています。
こちらはクラスター配下の特定のインスタンスを紐付けることができるエンドポイントであり、公式ドキュメントでは以下のような用途が紹介されています。
例えば、社内ユーザーをレポート生成やアドホック (1 回だけの) クエリ実行用の低容量インスタンスに振り向けたり、本番稼働用トラフィックを高容量インスタンスに振り向けたりすることができます。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Overview.Endpoints.Types
なるほど。
特定の用途やサービス用のエンドポイントを提供できそうな雰囲気を感じます。便利そうですね。
カスタムエンドポイントやるぞ
とあるプロジェクトにてデータベースにアクセスするサービスとバッチが増えることになりました。
通常ならば既存の構成通りそれぞれのエンドポイントを利用してもらうのですが、新規サービス/バッチには以下のような要件がありました。
- 新規サービスはクラウドサイン上の書類更新をトリガーにして、参照クエリを発行するのでクエリがかなり増える
- 新規バッチはアドホックに実行されるがほぼ全件のデータを参照するので並列処理でクエリをガンガン投げる予定
バッチはアドホックに実行されるので都度 Aurora のクローンを利用してもよいのですが、手間は発生します。
既存のクラスターをスケールアップすることも考えたのですが先程もでていたこちらが気になります。
例えば、社内ユーザーをレポート生成やアドホック (1 回だけの) クエリ実行用の低容量インスタンスに振り向けたり、本番稼働用トラフィックを高容量インスタンスに振り向けたりすることができます。
これでは?
カスタムエンドポイントを追加することで新規サービス/バッチ用の独立した接続先を提供し、既存サービスのクエリへの影響を避けられるのでは…?
と考えました。
カスタムエンドポイントをイメージで把握し、当初想定した構成はこちらです。

よさそうなのでは…
しかし調べていくうちにカスタムエンドポイントを利用する場合の課題として以下があがってきました。
- クラスターのリーダーエンドポイントの利用は推奨されていない
- フェイルオーバー発生時の構成
課題1. クラスターのリーダーエンドポイントの利用は推奨されていない
ドキュメントをきちんと読むと書いてある通りなのですが…。
カスタムエンドポイントを使用する場合は、通常、そのクラスターのリーダーエンドポイントは使用しません。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Overview.Endpoints.Types
これはリーダーエンドポイントの仕様が関係していると理解しました。
リーダーエンドポイントは以下のような挙動だと記載されています。
クラスターに 1 つ以上の Aurora レプリカが含まれている場合、リーダーエンドポイントは Aurora レプリカ間で各接続リクエストを負荷分散します。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Overview.Endpoints.Types
つまりリーダーエンドポイントを利用するとカスタムエンドポイント用に追加したレプリカインスタンスも負荷分散の対象になるようです。
赤線のようにリーダーエンドポイントへのクエリがカスタムエンドポイントでも処理されるイメージですね。

カスタムエンドポイントで重いクエリが処理されている場合に、既存サービスのクエリが影響を受けてしまいそうです。
当初考えていた新サービス用のエンドポイントのクエリと既存サービスのクエリを分離したい場合は以下のような構成が考えられます。

なおカスタムエンドポイントではマルチマスターのクラスターではない限り、ANY か READER というタイプが指定でき、タイプ次第で紐付けられるインスタンスの種類(プライマリを含められるかどうか)が変わってきます。
デフォルトのリーダーエンドポイントは参照させず、リーダー用にタイプ READER なカスタムエンドポイントをつくる。
これで解決しそうな気もしますが、運用において気になる点が出てきました。
課題2. フェイルオーバー発生時の構成
リーダー用のカスタムエンドポイントでリーダーエンドポイントを代替できそうですが、フェイルオーバーが発生したときの挙動が気になります。
カスタムエンドポイントは紐付けるインスタンスを静的に指定したり、除外リストを指定することでクラスター内のインスタンスを自動で紐付けることが可能です。
ただフェイルオーバーが発生したときの動作はドキュメントに以下のように記載されています。
フェイルオーバーや昇格に伴って DB インスタンスのロールがプライマリインスタンスと Aurora レプリカの間で変わった場合、 Aurora は静的リストまたは除外リストに指定されている DB インスタンスを変更しません。
例えば、タイプが READER であるカスタムエンドポイントには、Aurora レプリカからプライマリインスタンスに昇格された DB インスタンスが含まれている場合があります。
カスタムエンドポイントのタイプ (READER、WRITER、または ANY) によって、そのエンドポイントを介して実行できるオペレーションの種類が決まります。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Endpoints.Custom
フェイルオーバーが起こって インスタンス-blue がプライマリに昇格、インスタンス-red がレプリカとして復旧した場合は以下のようになります。
(カスタムエンドポイントの設定によっては インスタンス-red はリーダー用のカスタムエンドポイントに組み込まれます)

フェイルオーバー発生後にカスタムエンドポイントにプライマリインスタンスが含まれることもあるとのことです。
カスタムエンドポイントにはタイプを指定できるのは記載したとおりですが、フェイルオーバー発生時にはタイプの制限を無視した状態になってしまうことがありそうです。
そうなると上図の赤破線部分が気になります。
参照用のクエリがプライマリインスタンスにも流れてしまうのでは…?
とあるプロジェクトではこの時点でフェイルオーバー発生時の挙動に確証が持てず、カスタムエンドポイントの利用を断念しました ![]()
ただその後検証した結果、これは カスタムエンドポイントのタイプで制御することができそうだったので紹介しておきます。
カスタムエンドポイントの検証
図に書いたような構成のクラスターを作成します。
red がプライマリインスタンス(=ライター)、 blue,yellow, orange がレプリカインスタンス(=リーダー)です。

カスタムエンドポイントはコンソールからでは ANY タイプしか指定できません。
今回はリーダー用のカスタムエンドポイントの検証をしたいので CLI から READER タイプを指定して作成します。
# 新サービス用のカスタムエンドポイント
$ aws rds create-db-cluster-endpoint --db-cluster-endpoint-identifier custom-endpoint \
--endpoint-type reader \
--db-cluster-identifier endpoint-test
$ aws rds modify-db-cluster-endpoint --db-cluster-endpoint-identifier custom-endpoint \
--static-members endpoint-test-instance-orange
# リーダー用のカスタムエンドポイント
$ aws rds create-db-cluster-endpoint --db-cluster-endpoint-identifier custom-reader-endpoint \
--endpoint-type reader \
--db-cluster-identifier endpoint-test
$ aws rds modify-db-cluster-endpoint --db-cluster-endpoint-identifier custom-reader-endpoint \
--static-members endpoint-test-instance-blue endpoint-test-instance-yellow
このような形で作成されました。
-
新サービス用のカスタムエンドポイント
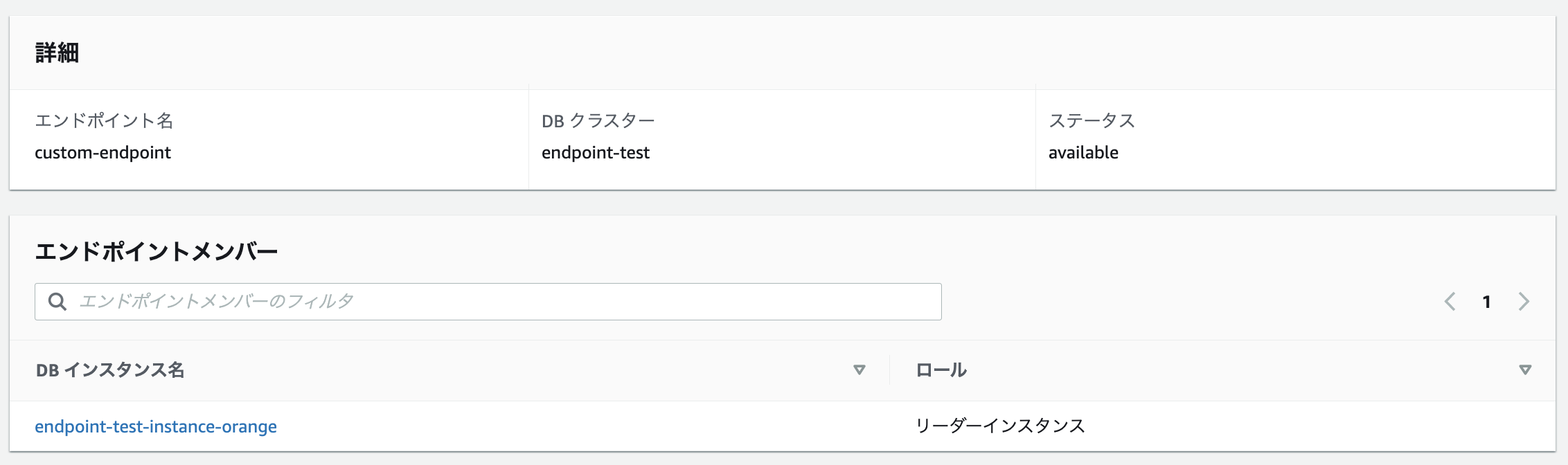
-
リーダー用のカスタムエンドポイント
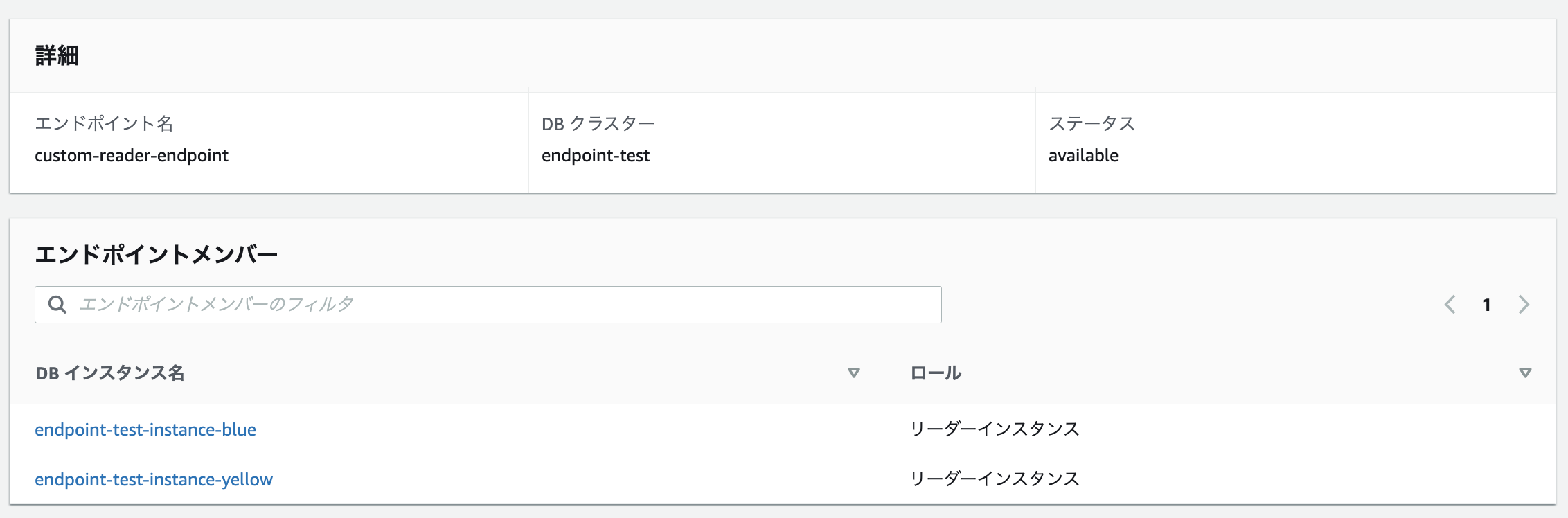
それぞれレプリカインスタンスだけが紐付いたカスタムエンドポイントとなります。
検証1: リーダーエンドポイントの利用
この状態でリーダーエンドポイントへの接続を試すと、課題でも確認したとおりクラスター内のすべてのインスタンス(カスタムエンドポイントのメンバーにも)クエリが流れることを確認します。
(blue, yellow, orange に接続される)
$ READER_ENDPOINT=endpoint-test.cluster-ro-ctatiinz6jv1.ap-northeast-1.rds.amazonaws.com
$
$ for i in $(seq 10) ; do mysql -h$READER_ENDPOINT -uadmin -e 'select now(), @@aurora_server_id srvid\G'; sleep 1 ; done
*************************** 1. row ***************************
now(): 2022-12-18 17:25:09
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:25:10
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:25:12
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:25:13
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:25:14
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:25:15
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:25:16
srvid: endpoint-test-instance-orange
*************************** 1. row ***************************
now(): 2022-12-18 17:25:17
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:25:18
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:25:19
srvid: endpoint-test-instance-yellow
ドキュメントの通りリーダー用にカスタムエンドポイントを作成したほうが良さそうです。
ではリーダー用のカスタムエンドポイントを作成した際にフェイルオーバーが発生したらどうなるかを確認します。
ドキュメント上ではいまいちどのような動作になるのか確証が持てませんでしたが…。
検証2. フェイルオーバー発生時の挙動
まずリーダー用のカスタムエンドポイントに接続すると紐付けられているリーダーインスタンス(blue, yellow のどちらか)に接続されることを確認します。
for i in $(seq 10) ; do mysql -h$CUSTOM_READER_ENDPOINT -uadmin -e 'select now(), @@aurora_server_id srvid\G'; sleep 1 ; done
*************************** 1. row ***************************
now(): 2022-12-18 17:26:04
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:26:05
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:26:06
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:26:07
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:26:08
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:26:09
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:26:10
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:26:11
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:26:12
srvid: endpoint-test-instance-blue
*************************** 1. row ***************************
now(): 2022-12-18 17:26:13
srvid: endpoint-test-instance-yellow
この状態でフェイルオーバーが起きた際にプライマリなインスタンスに参照クエリが流れてしまうことを懸念していました。
フェイルオーバーを起こして blue をプライマリに昇格させします。
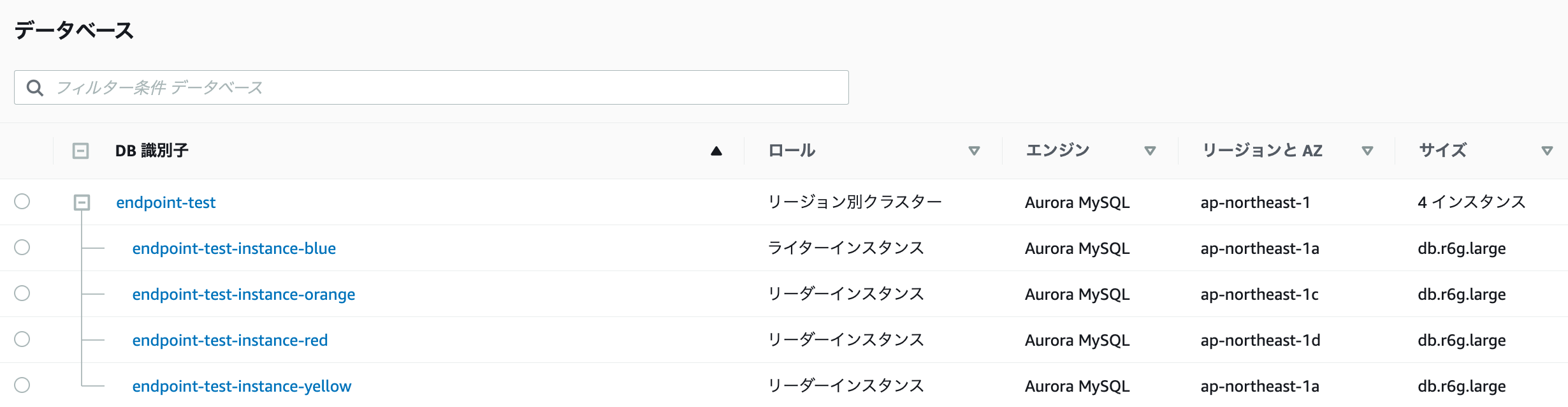
この状態でリーダー用のカスタムエンドポイントをコンソール上で確認すると blue が存在しなくなりました。
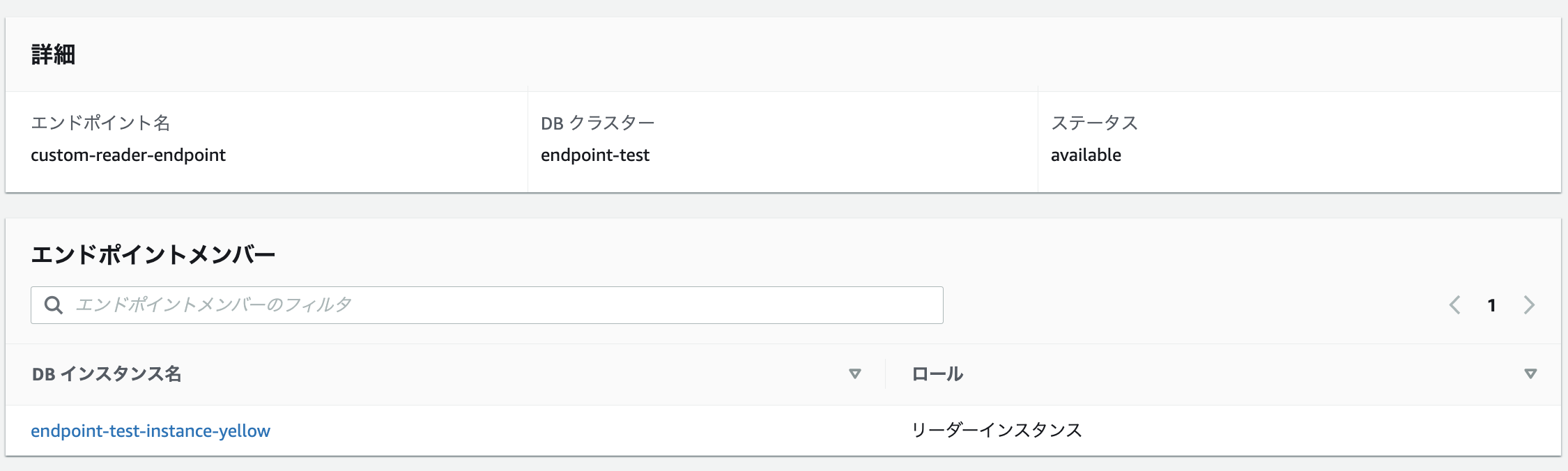
CLI で確認するとメンバーとしては残っているように見えます。
$ aws rds describe-db-cluster-endpoints
{
"DBClusterEndpoints": [
.....
{
"Status": "available",
"Endpoint": "custom-reader-endpoint.cluster-custom-ctatiinz6jv1.ap-northeast-1.rds.amazonaws.com",
"DBClusterIdentifier": "endpoint-test",
"CustomEndpointType": "READER",
"StaticMembers": [
"endpoint-test-instance-yellow",
"endpoint-test-instance-blue"
],
"EndpointType": "CUSTOM",
"DBClusterEndpointResourceIdentifier": "cluster-endpoint-HCVFZAFITQZFTEZCSLYQTOLPBY",
"ExcludedMembers": [],
"DBClusterEndpointIdentifier": "custom-reader-endpoint",
"DBClusterEndpointArn": "arn:aws:rds:ap-northeast-1:1234567890:cluster-endpoint:custom-reader-endpoint"
}
]
}
以下のドキュメントのとおりに見えます。
フェイルオーバーや昇格に伴って DB インスタンスのロールがプライマリインスタンスと Aurora レプリカの間で変わった場合、 Aurora は静的リストまたは除外リストに指定されている DB インスタンスを変更しません。
例えば、タイプが READER であるカスタムエンドポイントには、Aurora レプリカからプライマリインスタンスに昇格された DB インスタンスが含まれている場合があります。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Endpoints.Custom
接続確認をしてみます。
$ for i in $(seq 20) ; do mysql -h$CUSTOM_READER_ENDPOINT -uadmin -e 'select now(), @@aurora_server_id srvid\G'; sleep 1 ; done
*************************** 1. row ***************************
now(): 2022-12-18 17:44:47
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:48
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:49
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:50
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:51
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:52
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:53
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:54
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:55
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:56
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:57
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:58
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:44:59
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:00
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:01
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:02
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:03
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:04
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:05
srvid: endpoint-test-instance-yellow
*************************** 1. row ***************************
now(): 2022-12-18 17:45:06
srvid: endpoint-test-instance-yellow
念の為何度か繰り返してみましたが、 リーダー用のカスタムエンドポイントに表示されている yellow にしか接続されず、紐付けられている blue には接続されませんでした。
つまりカスタムエンドポイントは以下のような挙動をしているといえそうです。
- タイプに応じて紐付けられるインスタンスが決まる(タイプ
READERの場合、レプリカのみ紐付く) - フェイルオーバー等で1と異なる状態になることがある(タイプ
READERだが、レプリカとレプリカから昇格したプライマリ(ライター)が紐付く) -
2の状態で実行されるオペレーションは1の対象で処理される(タイプ
READERなので、レプリカとレプリカから昇格したプライマリ(ライター)が紐付いていてもレプリカのみで処理を行う)
この3の部分はドキュメントから読み取れなかったのですが、以下になるのかな…?
カスタムエンドポイントのタイプ (READER、WRITER、または ANY) によって、そのエンドポイントを介して実行できるオペレーションの種類が決まります。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Endpoints.Custom
検証した挙動を見る限りだとカスタムエンドポイントのタイプを適切に設定しておくことでプライマリインスタンスへの接続を制御できそうです。
まとめ
- Aurora ではカスタムエンドポイントを利用することができる
- カスタムエンドポイントを利用する場合、リーダーエンドポイントの利用は推奨されない
- カスタムエンドポイントを利用する場合、フェイルオーバーでプライマリインスタンスがカスタムエンドポイントのメンバーに含まれることがある
- ただカスタムエンドポイントのタイプ次第でプライマリインスタンスへの接続は制御できる
おわりに
ドキュメントから判断してカスタムエンドポイントの利用を断念していたのですが、検証を踏まえた挙動を見る限り Aurora がよしなにやってくれていそうです。
ただ直感的ではない状態が発生しそうなのも確かです。
今回は結局カスタムエンドポイントではなく、クラスターのスケールアップや、バッチ用にクローンした DB を用意することで対応しました。
マネージドサービスの仕様を把握することの難しさを感じるとともに、構成の工夫やカスタマイズをしすぎずデフォルトに近い設定を利用することで見通しを良くしておくことも、マネージドサービスを利用していく上で大事なことだなと改めて感じさせられたのでした。
明日は @t0daaay さんです。お楽しみに