※記事について著作権等で問題がありましたら、お手数ですがコメントいただけると幸いです。
早急に修正か、必要に応じて記事を削除いたします。
AWS初心者による、SAA取得に向けた学習の記録⑤ の続きです。
関連記事はこちらからどうぞ。
- AWS初心者による、SAA取得に向けた学習の記録①
- AWS初心者による、SAA取得に向けた学習の記録②
- AWS初心者による、SAA取得に向けた学習の記録③
- AWS初心者による、SAA取得に向けた学習の記録④
- AWS初心者による、SAA取得に向けた学習の記録⑤
- AWS初心者による、SAA取得に向けた学習の記録⑥
※参考書籍
[AWS認定資格試験テキスト AWS認定ソリューションアーキテクト・アソシエイト 改訂版第2段](https://www.amazon.co.jp/dp/B08MVXRFFN?
tag=maftracking339397-22&linkCode=ure&creative=6339)
今回は
- RDS
- Amazon Aurora
- Redshift
- DynamoDB
- ElastiCache
についての内容となります。
RDS(Relational Database Service)
RDS は、AWSが提供するマネージドRDBサービス。
機能概要
- MySQLやPostgreSQL、Microsoft SQL Serverなどの様々なDBエンジンから選択可能
- データ保存のストレージにはEBSを使用し、利用可能なストレージタイプは以下の三種類
- 汎用SSD
- プロビジョンドIOPS SSD
- マグネティック
- DBインスタンス作成時のオプションでマルチAZ構成にすることができるが、以下の注意点がある
- 書き込み速度が若干遅くなる
- フェイルオーバーに時間がかかる
- リードレプリカと呼ばれる、通常のRDSとは別に参照用のDBインスタンスを作成する機能がある
- これによりマスターの負荷を軽減し、読み込みの多いDBリソースのスケールアウトが実現可能
- マスターとリードレプリカの同期は非同期レプリケーション方式のため、
リードレプリカの参照タイミングによっては最新のマスタが反映されていない可能性もある - インスタンスごとにセキュリティグループの指定が可能
- 暗号化オプションを有効にすることで、データストレージやスナップショット、ログといったRDS関連のデータの暗号化が可能
- 既に存在するデータに対しては取得したスナップショットから暗号化コピーを作成し、そこからDBインスタンスを作成することで可能
- RDS作成時に接続用エンドポイント(FQDN)が1つ作成される
バックアップ
- 自動バックアップ:バックアップウィンドウと保持期間を指定して一日に一回DBスナップショットを取得する機能
- 保持期間は最大35日
- 復旧にはスナップショットから新規RDSを作成する(稼働中のRDSにバックアップデータを戻すことは不可)
- 手動スナップショット:任意のタイミングでDBスナップショットの取得が可能
- 上限はリージョンあたり100個
- 手動でスナップショットをとる場合、DBをマスター/スタンバイの状態にしておくとI/O瞬断が発生しない
- リストア:作成したスナップショットを選択し、新規RDSを作成する
Amazon Aurora
Amazon Aurora は、AWSが独自に開発したRDSのDBエンジンで、クラウドサービスを活かしたアーキテクチャとなっている。
構成要素
- DBインスタンス作成時にDBクラスタが作成される
- DBクラスタは以下から構成される
- 一つ以上のDBインスタンス
- 各DBインスタンスから参照するストレージ(クラスタボリューム)
- ストレージはSSDベースのクラスタボリューム
- クラスタボリュームは単一リージョン内の3つのAZに各2つずつ構成され、自動で同期される
- 他のRDSのようなマルチAZ構成オプションはないが、クラスタ内に参照専用のレプリカインスタンスの作成が可能
- プライマリインスタンスの障害発生時に、レプリカインスタンスがプライマリに昇格することでフェイルオーバーを実現
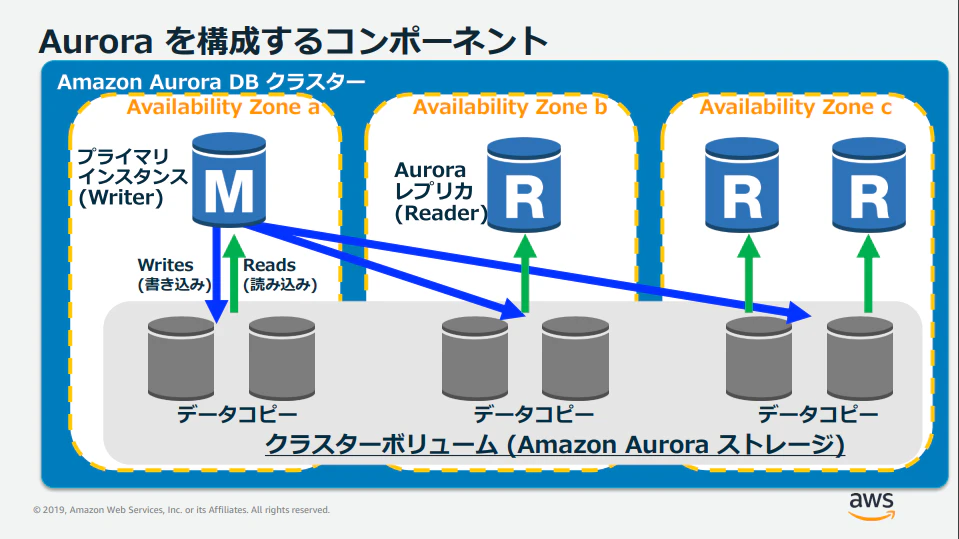
画像引用元:AWS再入門ブログリレー Amazon Aurora 編
Redshift
Redshift は、AWSが提供するデータウェアハウス向けのDBサービス。
構成要素
- 特徴は複数ノードによる分散並列処理
- 1つのRedshiftを構成するノードの集まりをRedshiftクラスタという
- クラスタは1つのリーダーノードと複数のコンピュートノードから構成される
- 複数のコンピュートノードを跨がずに処理を行う構成が望ましい
- リーダーノード
- SQLクライアントやBIツールの実行クエリによって、クエリの解析や実行プランの作成を行う
- また、各コンピュートノードの処理結果を返却するレスポンス処理も行う
- リーダーノードはクラスタに1台のみ
- コンピュートノード
- リーダーノードからの実行クエリを処理する
- ストレージとセットで構成されており、コンピュートノードの追加によってCPUやメモリなどのリソースの増加が可能
- ノードスライス
- Redshiftが分散並列処理を行う最小単位
- コンピュートノードのリソースをさらに分割したスライスという単位で構成される
- スライス数はコンピュートノードのインスタンスタイプによって異なる
- 列指向型(カラムナ)データベースで、集計処理に使用されるデータを列単位でまとめて管理することでデータ取得を効率化する
ゾーンマップ
Redshiftではブロック単位でデータが格納されており、そのブロックに格納されているデータの最小値と最大値をメモリに保存する仕組みのことを ゾーンマップと呼ぶ。
これを活用することでデータ検索処理の高速化を実現する。
1ブロックの容量は1MB。
MPPとシェアードナッシング
MPP(Massively Parallel Processing) は一回の集計処理を複数のノードに分散して実行する仕組み。
これによりノードの追加をするだけで処理のパフォーマンスを向上させることが可能。
シェアードナッシング は、複数のノードがディスクを共有せずにノードとディスクがセットで拡張される仕組み。
複数ノードが同一のディスクを共有することで発生するI/O性能の低下を防ぐことが可能。
これらの仕組みによって柔軟な拡張性が実現されている。
Redshift Spectrum
Redshift Spectrum は、S3のデータを外部テーブルとして定義できるようにし、Redshiftにデータを取り込まずにクエリの実行を可能にするサービス。
RedshiftのデータとS3のデータを組み合わせたSQLの実行が可能なため、データの使用目的に応じてストレージを使い分けることができる。
DynamoDB
DynamoDB は、AWSが提供するKey-Value型のマネージドNoSQLデータベースサービス。
テーブルやインデックスの作成時に、読み取り・書き込みに必要なスループットを指定してリソースを確保することにより、安定した性能を提供する仕組みとなっている。
機能概要
- 単一障害点を持たない構成のため、障害対応やメンテナンス時の運用を考える必要がない
- データが自動で3つのAZに保存される
- テーブルやインデックスの作成時に指定するスループットキャパシティはいつでもダウンタイムなく変更可能
- Read Capacity Unit(RCU):読み取りのスループットキャパシティを指定する指標
- Write Capacity Unit(WCU):書き込みのスループットキャパシティを指定する指標
- それぞれ増加回数に制限はないが、減少回数は1日9回まで
- また、負荷の状況に応じて自動でスケーリングすることも可能
- Key-Value型のDBのため、データ項目はキーとなる属性とその他の情報で構成される
- プライマリキー:データを一意に特定するための属性で、「パーティションキー」単独と「パーティションキー+ソートキー」で構成される二種類がある。
パーティションキーだけで特定できない場合はソートキーと組み合わせてプライマリキーを構成する。
プライマリキーはインデックスとしても利用され、プライマリキーのみでは高速化が難しい場合に「セカンダリインデックス」を作成する。 - セカンダリインデックス
- ローカルセカンダリインデックス:プライマリキーはテーブルで指定したパーティションキーと同一で、別の属性をソートキーとして作成するインデックスのこと。
元テーブルと同一のパーティション内で検索が完結する。 - グローバルセカンダリインデックス:プライマリキーとは異なる属性を使用して作成するインデックスのこと。テーブルとは別のキャパシティユニットでスループットを指定。
- 有効期限を設定したデータを自動で削除することが可能
- DynamoDB Streamsという機能で、直近24時間の変更履歴を保存することが可能
- DynamoDB Accelerator(DAX)で、DynamoDBの前段にキャッシュクラスタを構成することが可能
セカンダリインデックスは本来のKey-Value型のDBの使い方ではないため、RDBへの変更を検討する必要もある。
ElastiCache
ElastiCache は、AWSが提供するインメモリ型データベースサービスで、MemcachedとRedisの二種類がある。
Memcached
Key-Valueストア型インメモリデータベースのデファクトスタンダードとして広く使用されるエンジン。
以下の用途で使用。
- シンプルなキャッシュシステム
- データが消失してもシステムの動作に大きな影響を与えない
- 必要なキャッシュリソースの増減が頻繁にあり、スケールアウト/スケールインをする必要がある
Memcachedクラスタは、最大20のElastiCacheインスタンスで構成され、保存されるデータは複数のインスタンスに分散される。
エンドポイント
クラスタの作成時、二種類のアクセス用エンドポイントが作成される。
- ノードエンドポイント:各ノードに個別にアクセスするためのエンドポイント。
- 設定エンドポイント:クラスタ全体に割り当てられるエンドポイント。クラスタ内のノード増減を管理し、クラスタの構成情報を自動で更新する
スケーリング
スケールアウト、スケールイン、スケールアップ、スケールダウンの4つからリソースの調整が可能であるが、以下の2点に注意する必要がある。
- スケールアウトとスケールイン
- ノード数の増減時に、正しいノードにデータが再度マッピングされるまでの間にキャッシュミスが増加することがある
- スケールアップとスケールダウン
- これらを行う際には新規のクラスタを作成する必要がある。
Redis
Memcachedと同様にKVS型インメモリデータベースで、Memcachedより多くのデータが扱えるのと、キャッシュ用途だけではなくメッセージブローカーやキューを構成する要素としても利用可能。
以下の用途で使用。
- 様々なデータ型を扱いたい
- キーストアに永続性を持たせる
- 障害発生時、自動でフェイルオーバーしたりバックアップ/リストアなどの可用性が必要
クラスタモードの有効/無効に応じて冗長化の構成が変わるが、どちらの場合もマルチAZ構成にすることが可能なため、マスターインスタンスの障害発生時にはスタンバイインスタンスがマスターに昇格する。
- クラスタモード無効
- キャッシュデータは1つのElastiCacheインスタンスに保存される。
- 同じデータを持つリードレプリカを5つまで作成可能
- これらのまとまりをシャードと呼ぶ
- クラスタモード有効
- 最大500のシャードにデータを分割して保存可能
- リードレプリカは1つのシャードに対して最大5つ
- データ分散によりデータの読み書きの負荷分散構成の実現が可能
エンドポイント
クラスタの作成時、三種類のアクセス用エンドポイントが作成される。
- ノードエンドポイント:各ノードに個別にアクセスするためのエンドポイント。クラスタ構成がどちらの場合でも使用可能
- プライマリエンドポイント:書き込み処理用のElastiCacheインスタンスにアクセスするためのエンドポイント。クラスタ構成が無効の場合に使用
- 設定エンドポイント:クラスタモード有効時、ElastiCacheクラスタに対する全ての操作が可能
CPU使用率
Redisはシングルスレッドのため、4コアのインスタンスタイプを使用してもCPU使用率はそれぞれに分散された25%が最大値となる。
データ暗号化
RedisクライアントとElastiCache間の通信、ElastiCache内に保存するデータの暗号化をサポート。
データの暗号化はRedis版のElastiCacheにのみ対応。
終わりに
最後まで読んでいただきありがとうございました。
関連記事はこちらからどうぞ。
- AWS初心者による、SAA取得に向けた学習の記録①
- AWS初心者による、SAA取得に向けた学習の記録②
- AWS初心者による、SAA取得に向けた学習の記録③
- AWS初心者による、SAA取得に向けた学習の記録④
- AWS初心者による、SAA取得に向けた学習の記録⑤
- AWS初心者による、SAA取得に向けた学習の記録⑥
※参考書籍
[AWS認定資格試験テキスト AWS認定ソリューションアーキテクト・アソシエイト 改訂版第2段](https://www.amazon.co.jp/dp/B08MVXRFFN?
tag=maftracking339397-22&linkCode=ure&creative=6339)