はじめに
Redshift における Sort Key の1つである Interleaved Srot Key について解説をします。公式ドキュメントにはさらっとしか記述がないのですが、私が確認した公開された情報のなかでは AWS Blog が一番詳しく解説されていました。本稿はこちらの Blog を理解することを目的とします。
Sort Style
大きく分けて 3 つあります。
-
Single-column Sort Key
column 単位で設定された Key。 -
Compound Sort Key
table 単位で設定されたもので、2つ以上の column に対してセットされた Key。いわゆる複合 Key で Primary, Secondary と Key 間に優先順位があります。 -
Interleaved Sort Key
table 単位で設定されたもので、1つ以上の column に対してセットされた Key。
本稿では、Interleaved Sort Key について Deep Dive してみます。
Interleaved Sort Key
定式化
繰り返しになりますが Interleaved Sort Key についてはこちらの AWS Blog が私が知る限り、一番詳しく解説されています。この Blog を読んで疑問点がないのであれば、本稿に間違いがないかご協力くださいw
それでは、特に重要だと思う一文をまず紹介します。
A table with interleaved keys arranges your data so each sort key column has equal importance.
Interleaved Sort Key を指定した際に Redshift がどのように Table のデータを各 Block に格納するかを最もよく表現しています。つまり、各 Key には Primary, Secondary といった順序付けはなく、すべてが均等に重要なのです。均等に重要とは、各 Key を軸とした多次元空間に同じ重みで Block を配置するということです。ますますわかりませんね。簡単にいうと、Key が 2 つなら 2次元平面に正方形となるように、Key が 3 つなら 3次元空間に立方体となるように Block を配置するイメージです。
Interleaved Sort Key を持つ Table において、scan する必要のある Block 数は以下のように定式化できます。
scan する必要のある Block 数 = (Block 総数)^{((n-k)/n)}
n : Interleaved Sort Key として指定した Column 数
k : Interleaved Sort Key のうち where 句で指定した Column 数
ここで、n, k の値域は以下になります。(Interleaved Sort Key は最大 8 つまで指定可能です。)
1 \leq n \leq 8, 0 \leq k \leq 8
具体例
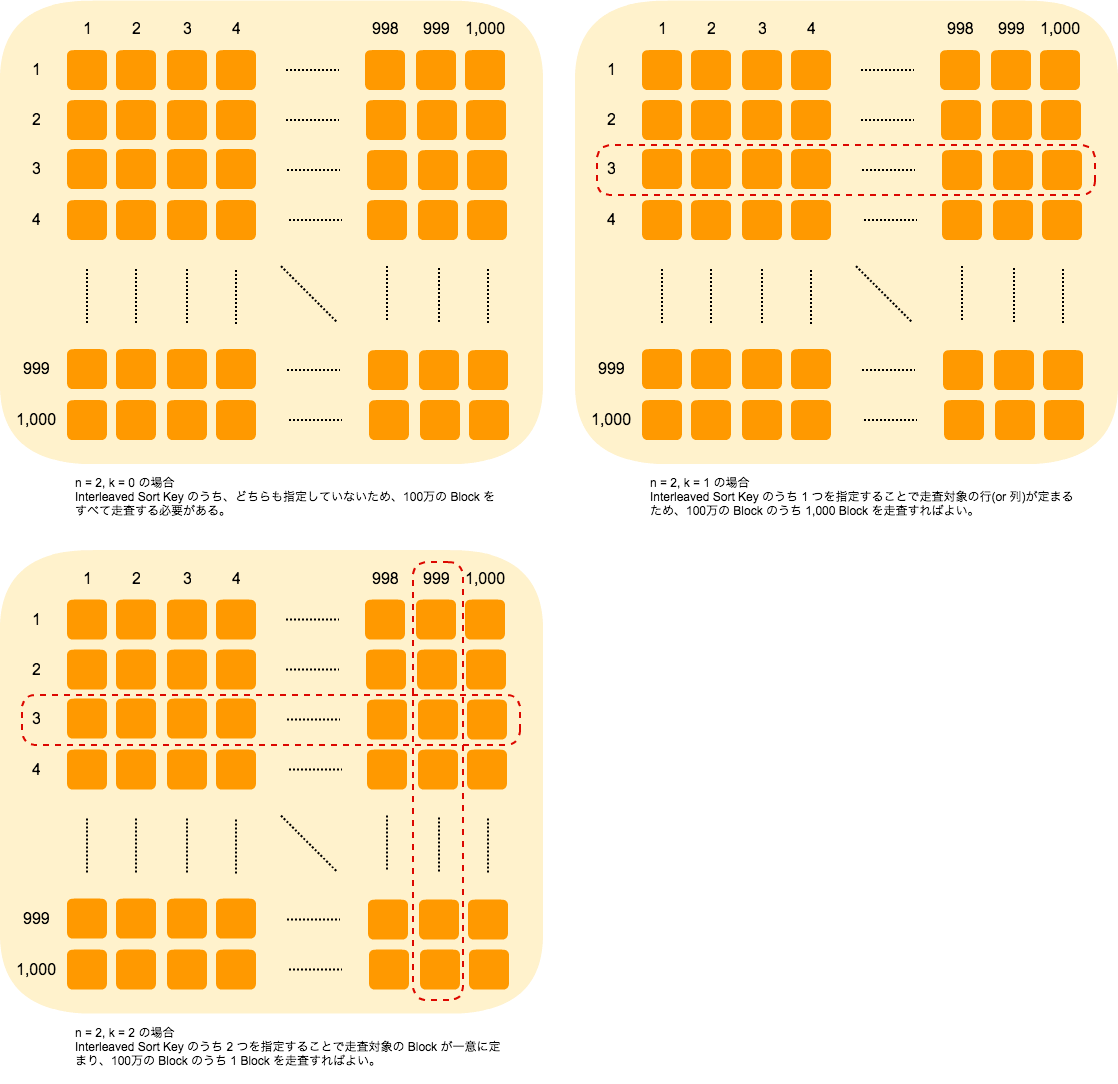
抽象的な話はこれくらいに留めて、具体例をあげて説明します。例えば、1,000,000 Block のデータを持つ Table に対して、Interleaved Sort Key として 2 Column を指定したとします。このとき、n, k と scan する必要のある Block 数をまとめると以下のようになります。
| n | k | blocks to be scanned |
|---|---|---|
| 2 | 0 | 1,000,000^((2-0)/2)=1,000,000 |
| 2 | 1 | 1,000,000^((2-1)/2)=1000 |
| 2 | 2 | 1,000,000^((2-2)/2)=1 |
Interleaved Sort Key を使うと、1,000,000 Block ある Table でも 2 つの Key を指定すれば 1 Block を走査するだけで済むのです! 1,000,000 [Block] x 1 [MB/Block] = 1 [TB] とすると驚異的な I/O の少なさではないでしょうか。
これを図を使って説明してみましょう。Interleaved Sort Key として指定した Column をそれぞれ x, y としたとき、1,000,000個の Block は 1,000 x 1,000 の Grid 状に2次元平面に分布します。よって、where 句で x, y をどちらも指定しない場合は、1,000 x 1,000 の Grid をすべて走査する必要があり、x, y のうちどちらかを指定した場合は、あとは x (もしくは y) 方向に走査するだけで済むため、1,000 Blockが走査対象となります。x, y の2つを指定した場合は、2 次元平面上の 1 点が定まるため 1 Block を走査するだけで済むのです。
AWS Blog の例について
いかかでしょうか。以上が理解できれば, AWS Blog の内容も理解できるはずです。
For fast filter queries without the need for indices or projections, Amazon Redshift now supports Interleaved Sort Keys, which will be deployed in every region over the next seven days. A table with interleaved keys arranges your data so each sort key column has equal importance. Interleaved sorts are most effective with highly selective queries that filter on multiple columns. Let’s say you have a table with 100,000 1 MB blocks per column, and you often filter on one or more of four columns (date, customer, product, geography). You can create a compound sort key, sorting first by date, then customer, product, and finally geography. This will work well if your query filters on date, but can require a table scan of all 100,000 blocks if you only filter by geographic region. Interleaved sorting provides fast filtering, no matter which sort key columns you specify in your WHERE clause. If you filter by any one of the four sort key columns, you scan 5,600 blocks, or 100,000(3/4). If you filter by two columns, you reduce the scan to 316 blocks or 100,000(2/4). Finally, if you filter on all four sort keys, you scan a single block.
この部分ですが、理解できましたでしょうか。100,000 blocks を持つテーブルがあって、1-4 column(date, customer, product, geography)で filter するケースを想定しています。date, customer, product, geography の順で compound key を設定した場合、date で filter した場合は効果的ですが、 geography だけで filter した場合は 100,000 blocks すべて scan する必要があります。filter というのはいわゆるクエリの where 句で指定することだと思ってもらって結構です。
一方で、Interleaved Sort Key を同じく 4 columns に対して設定した場合、どの column で filter しても高速になります(つまり、100,000 blocks フルスキャンは不要。)。たとえば、4つのうち1つで filter した場合は最大で5,600 blocks (100,000(3/4))、2つで filter した場合は最大で 316 blocks (100,000(2/4))、4つすべてで filter した場合はなんと 1 block をスキャンするだけでいいのです。
この部分については、先に定式化済みで、以下のようにまとめられます。
| n | k | blocks to be scanned |
|---|---|---|
| 4 | 0 | 100,000^((4-0)/4)=100,000 |
| 4 | 1 | 100,000^((4-1)/4)=5,623 |
| 4 | 2 | 100,000^((4-2)/4)=316 |
| 4 | 3 | 100,000^((4-3)/4)=32 |
| 4 | 4 | 100,000^((4-4)/4)=1 |
4次元空間に block が均等に配置されていて、指定する Key が増えるにつれて走査対象がドンドン絞りこまれていく様子を想像してください。"Sound like magic? No, it’s just math." といっておきながら、数学的な話がないため、本稿では定式化を試みました。
それぞれの特徴
それでは compopund と interleaved はどのように使わけたらよいのでしょうか。Blog ではそれぞれの特徴についても触れています。
There are tradeoffs between using compound and interleaved sort keys. If the columns you query are always the same, you may be better off using compound sort keys. In the example above, a query filtering on the leading sort column, pageURL, runs 0.4 seconds faster using compound sort keys vs. interleaved sorting. This is not surprising, since compound keys favor leading columns. Depending on the nature of the dataset, vacuum time overheads can increase by 10-50% for interleaved sort keys vs. compound keys. If you have data that increases monotonically, such as dates, your interleaved sort order will skew over time, requiring you to run a vacuum operation to re-analyze the distribution and re-sort the data.
ざっとまとめると以下になります。
- 常に同じカラムでクエリを実行するならば、compound のほうがいい
- Primary Key で filter する場合は、compound のほうが interleaved より 0.4秒速かった
- データの格納方式の都合上、interleaved のほうが compound よりも vacuum にかかる時間が 10 - 50 %増
- 時系列データのように単調増加するデータに対しては、interleaved の場合データの順序が徐々に劣化していくので、vacuum して再ソートが必要
上をみると compound のほうがいいように見えますが、私の方で付け加えると compound が優れているのは Primary Key のみで filter するケースに限られていて、定期的に vacuum する前提でいれば、interleaved でテーブル定義しておいたほうがクエリの融通がきくので無難だと思います。
おわりに
Interleaved Sort Key の凄さが理解いただけましたでしょうか。実感するために AWS 公式ドキュメントにある Comparing Sort Styles に従って、手を動かしてみることをオススメします。