はじめに
参考書で出てきた 「AsyncIterator」 についていまいち有用性が分からず、
個人的にまとめてみたいと思います。
あくまで理解に努める形なので、もっと深い部分まで知りたい方はMDNを見ていただければと思います。
AsyncIterator-MDN
※誤りありましたら、ご指摘いただけますと幸いです。
Iteratorとは
まずそもそも、Iterator とは。
めちゃ簡単に言うとデータを1つずつ順番に取り出せる仕組みって感じです。
例えば、配列に対して for...of でループを回すと順番に値を取得することができます。
これは、配列が Symbol.iterator という特別なメソッドを持っているためです。
内部的にはfor...ofループ内で next() メソッドが呼び出されることで、データを1つずつ取得できます。
詳細は割愛しますが、 Iterator は手動で実装することが可能です。
ではそれを踏まえてAsyncIteratorとは
ここも超ざっくりになりますが、違いとしては同期的か非同期的であるか、という部分になります。
Iteratorは同期的に値を取得できるのに対して、AsyncIteratorでは非同期的にデータを取得する(ただしawait)形になります。
これはコードを見た方が早いと思うので、実際に動かして比較してみます。
実装してみる
まずIteratorの場合。
function fetchDataWithoutAsyncIterator() {
for (let i = 1; i <= 5; i++) {
setTimeout(() => {
console.log(`Received: ${i}`);
}, Math.random() * 3000); // 0〜3秒のランダム遅延を起こす
}
}
fetchDataWithoutAsyncIterator();
上記の実行結果は下記になります。
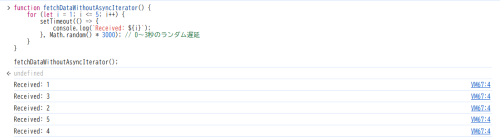
非同期で処理している部分が待機されず、ランダムに値が出力されてしまいました。
では続いてAsyncIteratorの場合。
async function* fetchDataWithAsyncIterator() {
for (let i = 1; i <= 5; i++) {
await new Promise(resolve => setTimeout(resolve, Math.random() * 3000)); // ランダムな待機
yield i; // 取得したデータを1つずつ返す
}
}
(async () => {
for await (const num of fetchDataWithAsyncIterator()) {
console.log(`Received: ${num}`);
}
})();
実行結果は下記になります。
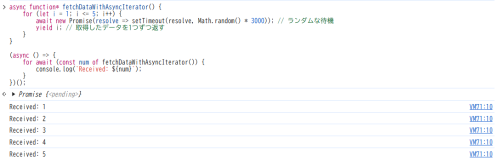
画像なので実際には見えませんが、1~3秒ランダムスリープはあるものの、しっかり待機されてから1~5まで順番に出力されました。
ちなみに **「for await (...of...)」**はAsyncIterator内で使用できるループで、Promiseが戻ってくる場合の処理も問題なく対応することができます。
おまけ:for...of内でasync/awaitでいいのでは?
上記のコードを見た上で、「別にfor...ofループ内でawaitで待機させればいいのでは?」という疑問が浮かんだ方もいらっしゃるかと思います。確かに今回のケースで言えば、その形でも問題なく実装できそうです。
「for...of」 と **「for await (...of...)」**の大きな違いは、データが既に手元にあるか否かです。
既に手元にあるのであれば「for...of」内でawaitを使用して、問題なく非同期処理であっても待機させればOKです。
一方処理を開始した後に、順番に非同期で届く場合、この場合は「for await (...of...)」を使用するが吉ということになります。
例えば、fetch()でAPI を提供するサーバーへのリクエストが発生する場合、ここでの結果が非同期で届く場合なんかは、AsyncIterator での for await (...of...) ループが有用となるでしょう。
下記でも触れてみます。
Web APIにおける有用性
上記を見ただけではだから何?という感じですが、実際にWeb APIを想定してみると有用性が分かりやすいと思います。
実際に見てみましょう。
async function* fetchRamensPaginated() {
let page = 1;
while (true) {
const response = await fetch(`https://ramendatabase/ramens?page=${page}`);
const ramens = await response.json();
if (ramens.length === 0) break; // データがなくなったら終了
for (const ramen of ramens) {
yield ramen; // 1件ずつ返す
}
page++; // 次のページへ
}
}
(async () => {
for await (const ramen of fetchRamensPaginated()) {
console.log(ramen.name); // 1件ずつ取得・処理
}
})();
上記のケースはページネーションAPIを想定しています。
データが大量にあると、一括取得ではメモリ負荷が高くなり、処理が遅くなるケースがあります。
通常の fetch で全データを一括取得を行うと、メモリがクラッシュするケースも考えられますが、
上記のようにyieldでデータを取得できるたびにデータを返してあげることによって負荷分散が可能となります。
ちなみに for await(...of...) 内で break を使えば、適切なタイミングで処理を中断できます。
最後に
非同期処理については、JSがシングルスレッドである以上、絶対に理解しなければいけない分野になると思います。
バックエンドが API を通じてデータを提供し、クライアントとやり取りを行う構成となると、ここでいかに非同期処理をうまいこと使えるかでUXの向上にもつながります。
この分野は特に直感的な理解がしづらい分野だと思うので、特に手を動かしながら理解に努めていきたいと思います。