ハイパフォーマンスコンピューティング(HPC)は創薬や金融サービス、気象予測など、様々な分野で利用されています。HPCと聞くと利用や構築するための敷居が高いというイメージを持つ方もおられるかもしれませんが、GCPを使ってHPCクラスタ環境を簡単に構築できるということをご紹介したいと思います。
今回は以下の図に示すシステムをGCP上で構築します。
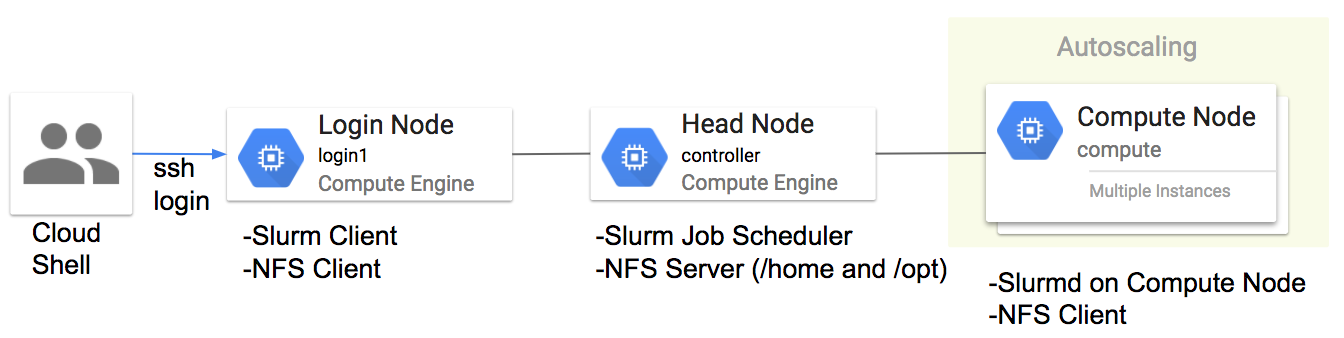
ジョブスケジューラにはSlurmを利用します。SlurmはTop500でも多く採用されていて実績のあるジョブスケジューラです。ShcedMDと協力し、GCP上でSlrumのクラスタ環境を簡単に構築するためのツールが提供されていますので、今回はそのツールを利用して環境構築します。
手順1. 準備
CloudShellで作業を行います。まずはじめに以下のGitHub Repositoryをクローンします。
git clone https://github.com/SchedMD/slurm.git
cd slurm/contribs/gcp/
Slurmでは認証機構としてMUNGEを利用しています。作成するクラスタにMUNGEの鍵を設定するため、以下のコマンドでMUNGEの鍵を生成します。(今回はデモ用なので簡易に作成しています。)
date +%s | sha512sum | cut -d' ' -f1
Deployment Managerに渡すslurm-cluster.yamlファイルの下記項目を修正します。それ以外の項目は今回は修正せず、デフォルトのまま使用します。
・・・
default_users : tyotsu <- アカウント名
munge_key : 先ほど作成したmunge keyを記載
・・・
手順2. Deployment Managerで環境構築
以下のコマンドを実行し、SLURMのクラスタ環境を構築します。
gcloud deployment-manager deployments create slurm --config
slurm-cluster.yaml
GCP ConsoleのDeployment Managerでデプロイメントの状況を確認できます。”slurm has been deployed”と表示されていればデプロイメントは正常に行われています。
ここまでで環境構築は完了です。以下のインスタンスが作成されていることをGCPコンソールのCompue Engineの画面から確認することができます。
- ログインノード:1台
- コントローラノード:1台
- 計算ノード:2台
手順3. 動作確認
構築したクラスタの環境が正常に動作しているか確認するため、CloudShellからログインノードにログインします。
gcloud compute ssh login1
まずは/homeと/optが正常にマウントされているか確認します。マウントされてない場合は、ノードを再起動するかmountコマンドでappsとhomeをマウントしてください。
[tyotsu@login1 ~]$ df -h -t nfs4
Filesystem Size Used Avail Use% Mounted on
controller:/apps 100G 2.9G 98G 3% /apps
controller:/home 100G 2.9G 98G 3% /home
以下のようなジョブファイルを作成します。(今回はシンプルに計算ノードのホスト名を返すジョブを使用します)。
[tyotsu@login1 ~]$ cat test.sh
# !/bin/bash
#
# SBATCH --job-name=test <- ジョブ名
# SBATCH --output=res.txt <- 出力ファイル
srun hostname <- 計算ノードで実行したいコマンド
srun sleep 10 <- hostnameだけだとすぐにジョブが終了するため
このジョブをSlurmジョブスケジューラに投入します。-Nで実行するノード数を指定します。ここでは既に起動している2台の計算ノードを使うように2を指定しています。
[tyotsu@login1 ~]$ sbatch -N 2 test.sh
Submitted batch job 8
ジョブの実行状態を確認します。STがRなので実行中であることが確認できます。
[tyotsu@login1 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
8 debug test tyotsu R 0:02 2 compute[1-2]
結果ファイル(res.txt)が出力されているので、内容を確認します。2つの計算ノード上でジョブが割り当てられ、実行されていることが確認できます。
[tyotsu@login1 ~]$ cat res.txt
compute2
compute1
それではこの結果ファイルを削除し、次に4台の計算ノードでジョブを実行してみます。
[tyotsu@login1 ~]$ sbatch -N 4 test.sh
Submitted batch job 9
[tyotsu@login1 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
9 debug test tyotsu CF 0:33 4 compute[1-4]
[tyotsu@login1 ~]$ cat res.txt
compute2
compute3
compute1
compute4
新しく2台のインスタンスがプロビジョニングされ、全体で4つの計算ノードを使用し、ジョブが実行されたことを確認できます。Slrumの詳細な使い方はここでは省略します。詳細はhttps://slurm.schedmd.com/などを参照してください。
まとめ
スケールアウトするクラスタ環境が構築できることを確認できました。
ただこのままだとMPIジョブは使えないですし、並列ファイルシステムもないので、HPCクラスタと呼ぶには少し早いと思います。