こちらはHameeアドベントカレンダー2日目の記事です。
今回は、普段何気なく使っているGoogle検索のキーワード履歴を可視化して、過去に自分が何に興味を持っていたかを分析してみようと思います。
全体の流れ
ディレクトリ構成
最終的なディレクトリ構成です
.
├── data
│ ├── bulk_insert.json
│ ├── bulk_insert.rb
│ ├── index.html
│ ├── parse.rb
│ ├── search_keywords.json
│ └── 検索
│ ├── 2017-01-01 2017年1月〜2017年3月.json
│ ├── 2017-04-01 2017年4月〜2017年6月.json
│ ├── 2017-07-01 2017年7月〜2017年9月.json
│ └── 2017-10-01 2017年10月〜2017年12月.json
├── docker-compose.yml
└── elasticsearch
└── Dockerfile
検索履歴のダウンロード
兎にも角にもデータが無いと何も始まらないので、googleの検索履歴をダウンロードします。
次のgoogleのダウンロードページにて、searchesを選択することで検索履歴のzipファイルをダウンロードできます。
https://takeout.google.com/settings/takeout
ダウンロードしたzipファイルを解凍すると次のようなディレクトリ構成になっています。
(JSONファイルは2017年以前も存在しますが、今回は2017年のみを対象とするため都合により削除してあります。)
Takeout
├── index.html
└── 検索
├── 2017-01-01 2017年1月〜2017年3月.json
├── 2017-04-01 2017年4月〜2017年6月.json
├── 2017-07-01 2017年7月〜2017年9月.json
└── 2017-10-01 2017年10月〜2017年12月.json
jsonファイルの中身を確認
ここで、一旦ダウンロードした検索履歴のデータ構造を確認してみます。
timestamp_usecが検索した時の時間を表しており、UNIXタイムスタンプのナノ秒で表現されています。
query_textが実際に検索した時の検索文字列になっており、この文字列を分解して検索キーワードの一覧を取得していきます。
{
"event": [
{
"query": {
"id": [
{
"timestamp_usec": "1490981273760997"
}
],
"query_text": "秋葉原ダイビル"
}
},
{
"query": {
"id": [
{
"timestamp_usec": "1490932140812972"
}
],
"query_text": "php conference"
}
},
...
検索キーワードの抽出
データ構造
それでは、ダウンロードしたJSONファイルから必要なデータを抽出します。
検索文字列を分解して、検索時間と検索キーワードの組み合わせをリストとして取得します。
検索時間については、UNIXタイムスタンプで表現されているので、日付表記にミリ秒に変換しておきます。
[
{
"timestamp": "2017-03-31 12:49:00",
"keyword": "php"
},
{
"timestamp": "2017-03-31 12:49:00",
"keyword": "conference”
},
....
]
また、timestamp_usecが複数存在する場合がありますが、この場合は短時間に何回も検索を実行しているだけなので、今回は最初の検索を1回としてまとめています。
{"id"=>[{"timestamp_usec"=>"1508764388232195"}, {"timestamp_usec"=>"1508764390541359"}, {"timestamp_usec"=>"1508764411274548"}], "query_text"=>"docker ディレクトリ マウント build"}
検索履歴のキーワード一覧を取得
キーワード一覧の取得については、次のrubyのスクリプトを実行して、search_keywords.jsonを生成します。
$ ruby parse.rb
require 'json'
# Google検索履歴のJSONファイルを読み込んで、クエリ情報を配列で返す
def readQueries(json_file)
File.open(json_file) do |file|
return JSON.load(file)['event'].map{|item| item['query']}
end
end
# 複数のJSONデータを読み込んで結合する
queries = Dir.glob('検索/*.json')
.reduce([]){|array, file|
array.concat(readQueries(file))
}
search_keywords = queries.map{|query|
# 検索履歴のクエリをキーワード毎に分解
keywords = query['query_text'].split(/\s| /)
# Googleでの検索時間を取得
timestamp = query['id'][0]['timestamp_usec']
keywords.map{|keyword|
# UNIタイムスタンプを日付表記に変換する(単位はナノ秒になっているので注意)
{'timestamp'=> Time.at(timestamp.to_i / 1000000).strftime('%Y-%m-%d %H:%M:%S'), 'keyword'=> keyword}
}
}.flatten
File.write('search_keywords.json', JSON.pretty_generate(search_keywords))
Kibana+Elasticsearchの導入
続いて検索履歴のキーワードを可視化する為のツールとして、Kibana+Elasticsearchを導入していきます。
Kibana, Elasticsearchについての説明は長くなってしまうので、割愛させて頂きます。
今回はDockerを利用して、サクッと導入していきます。
.
├── data
│ ├── index.html
│ ├── parse.rb
│ ├── search_keywords.json
│ └── 検索
│ ├── 2017-01-01 2017年1月〜2017年3月.json
│ ├── 2017-04-01 2017年4月〜2017年6月.json
│ ├── 2017-07-01 2017年7月〜2017年9月.json
│ └── 2017-10-01 2017年10月〜2017年12月.json
├── docker-compose.yml
└── elasticsearch
└── Dockerfile
docker-compose.yml
version: '2'
services:
elasticsearch:
build: ./elasticsearch
volumes:
- es-data:/usr/share/elasticsearch/data
ports:
- 9200:9200
expose:
- 9300
ulimits:
nofile:
soft: 65536
hard: 65536
# https://github.com/docker-library/elasticsearch/issues/111
# uliimit
kibana:
image: kibana:5.3
links:
- elasticsearch:elasticsearch
ports:
- 5601:5601
volumes:
es-data:
driver: local
elasticsearch/Dockerfile
FROM elasticsearch:5.3
# kuromojiをインストール
RUN elasticsearch-plugin install analysis-kuromoji
コンテナの生成
http://127.0.0.1:5601にアクセスして、Kibanaの画面が表示されれば導入完了です。
$ docker-compose up -d
Elasticsearchにデータを投入
抽出したキーワード一覧をKibanaで可視化する為に、Elasticsearchに投入していきます。
mappingの作成
最初にElasticsearchにmappingを作成します。
$ curl -XPUT 'http://localhost:9200/google_search_history' -d '{
"mappings": {
"keywords": {
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"keyword": {
"type": "keyword"
}
}
}
}
}'
登録データの作成
Elasticsearchにデータを一括登録する為に、先ほど生成したsearch_keywords.jsonから、一括登録用のbulk_insert.jsonを生成します。
$ ruby bulk_insert.rb
require 'json'
INDEX = 'google_search_history'
TYPE = 'keywords'
# データをインサートするJSONを生成
def insert(index, type, data)
hash = {'index' => {'_index'=>index, '_type'=>type}}
[hash, data].map{|item|
JSON.generate(item)
}.join("\n")
end
queries = File.open('search_keywords.json') do |file|
JSON.load(file)
end
# 各データを変換して、バルクインサートするためのJSONを生成
bulk_insert_json = queries.map{|query| insert(INDEX, TYPE, query)}.join("\n")
File.write('bulk_insert.json', bulk_insert_json)
データの投入
curlコマンドにて、bulk_insert.jsonの内容をElasticsearchに投入していきます。
$ curl -XPOST localhost:9200/google_search_history/keywords/_bulk --data-binary @bulk_insert.json > /dev/null
可視化
ようやく下準備が完了したので、Kibanaでキーワードを見ていきましょう。
index_patternの選択
最初にManagementからインデックスパターンを設定しておく必要があります。
今回は、作成済みのインデックスであるgoogle_search_historyを設定しておきます。
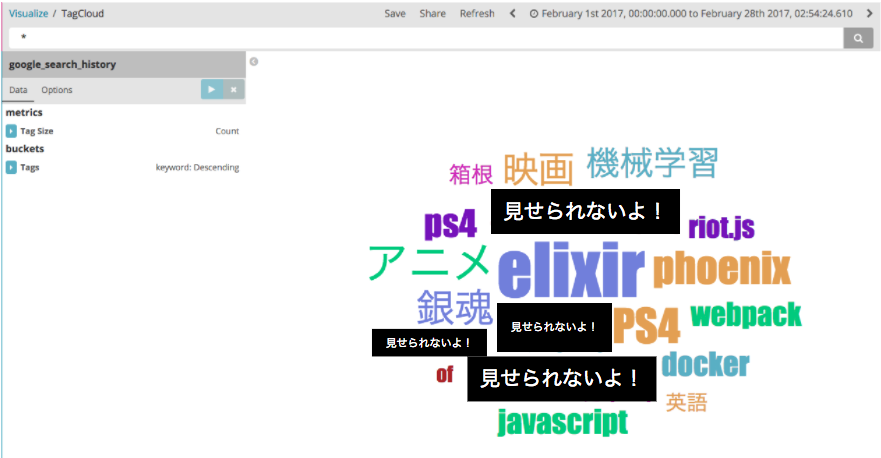
タグクラウドで表示
2月の検索キーワードを検索回数に応じて、タグクラウドで表示してみます。
elixirの検索回数がかなり多いことが分かりますね。
PS4の検索回数が多いのは、恐らく購入を検討していたんだと思います。
( 一部は察してください。)
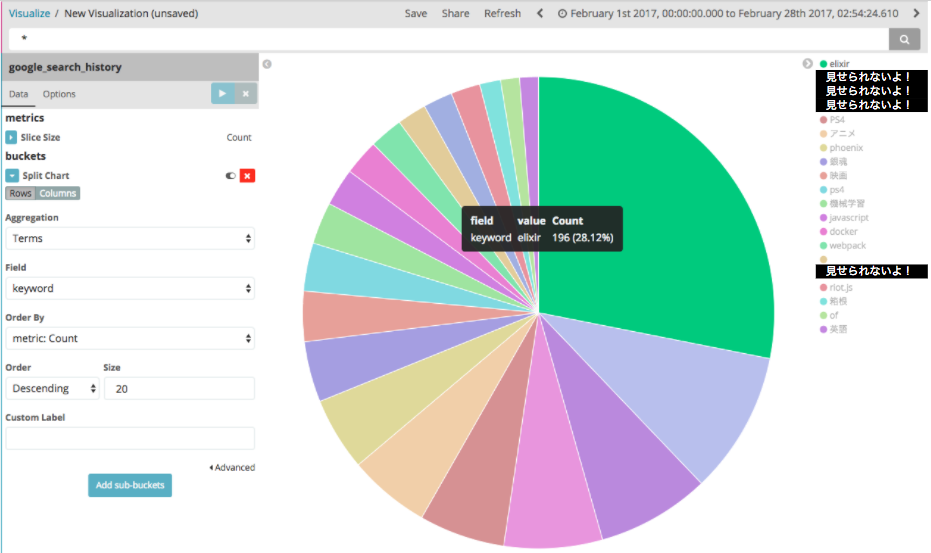
円グラフで表示
円グラフで全体の割合を見てみます。
円グラフで見ると、elixirの検索回数が突出して多いことが分かります。
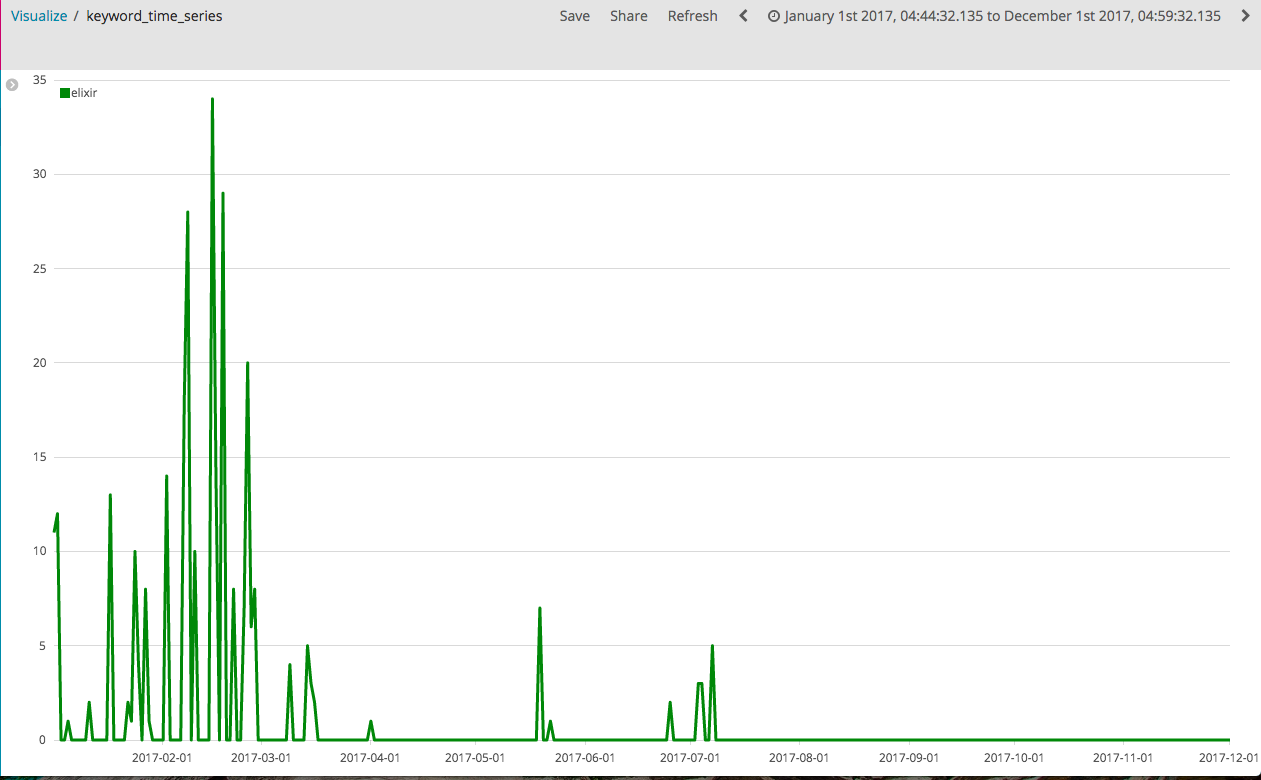
時系列で検索推移を表示
elixirについて1年間の検索推移を見てみます。
推移で見ると前半の2,3月に検索が集中しています。
グラフが示している通り、この時期はelixirにがっつりハマっていました。
ただ、それ以降は満足したのか全く検索しなくなっています。
.es(index='google_search_history', q='keyword:"elixir"', metric="count", timefield='timestamp').color(green).label(elixir)
時期ごとの個人トレンドを表示
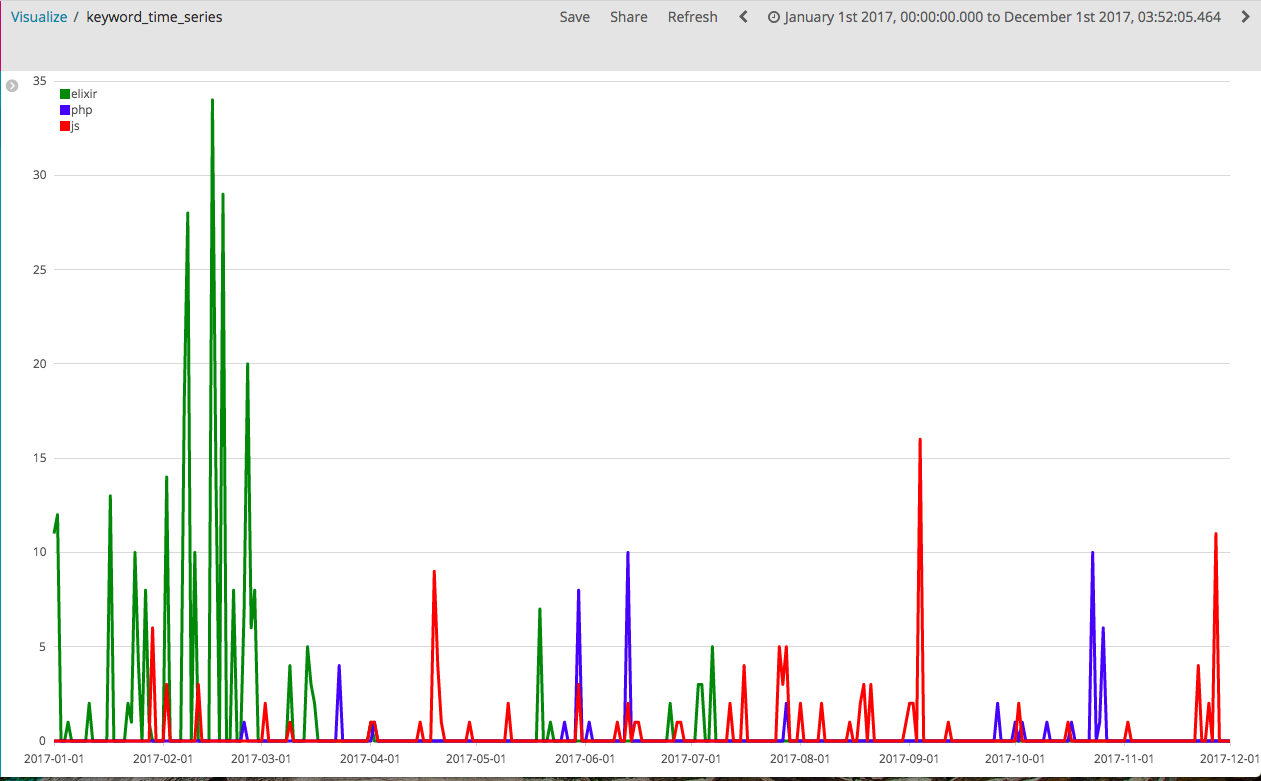
さいごにelixir, php, jsの検索推移をまとめて表示してみます。
言語ごとに検索されている時期がそれぞれ異なり、個人googleトレンド検索っぽいことが出来ています!
さいごに
googleの検索キーワードを可視化すれば、過去に何に興味を持っているかや興味の推移なども見れたので、思っていたよりも満足のいく結果が得られました。
データの可視化は見えない物が見えてくるので、非常に面白いですね。