はじめに
はてブにimport.ioというスクレイピングツールが紹介されている。
http://b.hatena.ne.jp/entry/nelog.jp/import-io
このツールを使うことができればスクレイピング用のコードを記述しなくともデータの取得ができる。
ウェブサービス版だけでなくアプリケーション版についても少しだけ使ってみたのでノウハウを書き出しておく。
例がひどいかもしれないがそこは気にしてはいけない。
ウェブサービス版とアプリケーション版の違い
ウェブサービス版
- 登録などもなく簡単に使える
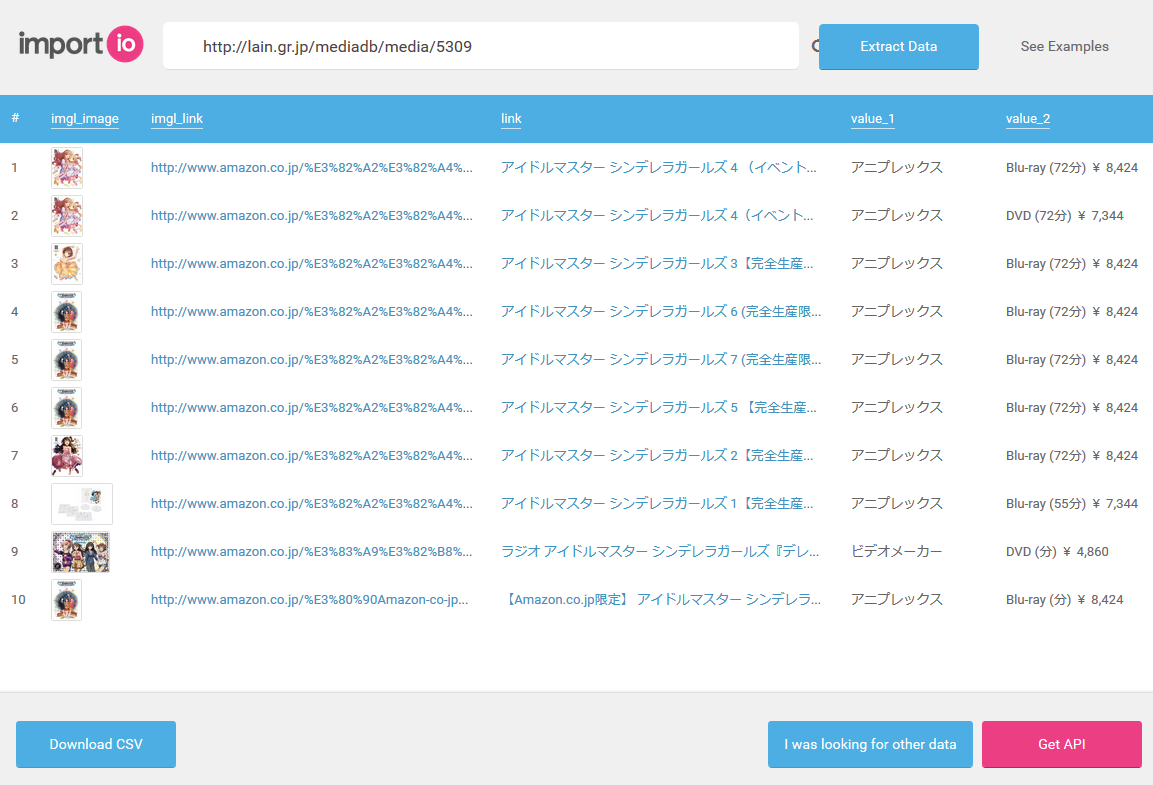
- ページ内に複数のリストがある場合はどこが取得されるか分からない
- このページをウェブサービス版のスクレイピングをかけると以下の様な取得結果となる
アプリケーション版
- アプリケーションのインストールが必要
- アカウントの登録が必要(githubやgoogleのアカウントでOK)
- スクレイピングルールをAPIとして登録できる
- APIを複数のウェブページに適応し、それをまとめて実行し、1つのCSVとしてDLできる
アプリケーション版のインストール
import.ioのpricingからダウンロード後、インストールするだけである。
アカウントも必要になるが登録、利用は無料である。
アプリケーション版について
概要
アプリケーション版で行うことはスクレイピングルールであるAPIを作成し、
それを対象となるウェブページに適応することである。
目的
.lainの作品別のページ(こことかこことか)にAPIを実行し、以下の様なデータの取得を目指す。
| title | media | start_date | chara | cv |
|---|---|---|---|---|
| アイドルマスター シンデレラガールズ | TVアニメ | 2015年1月9日 | 島村卯月 | 大橋彩香 |
| アイドルマスター シンデレラガールズ | TVアニメ | 2015年1月9日 | 渋谷 凛 | 福原綾香 |
| … | … | … | … | … |
| 聖剣使いの禁呪詠唱 | TVアニメ | 2015年1月11日 | 灰村諸葉 | 石川界人 |
| 聖剣使いの禁呪詠唱 | TVアニメ | 2015年1月11日 | 嵐城サツキ | 竹達彩奈 |
| … | … | … | … | … |
APIの新規作成
MyData画面からNewと書いてあるセレクトボックスを選択することで新しいAPIを作成できる。
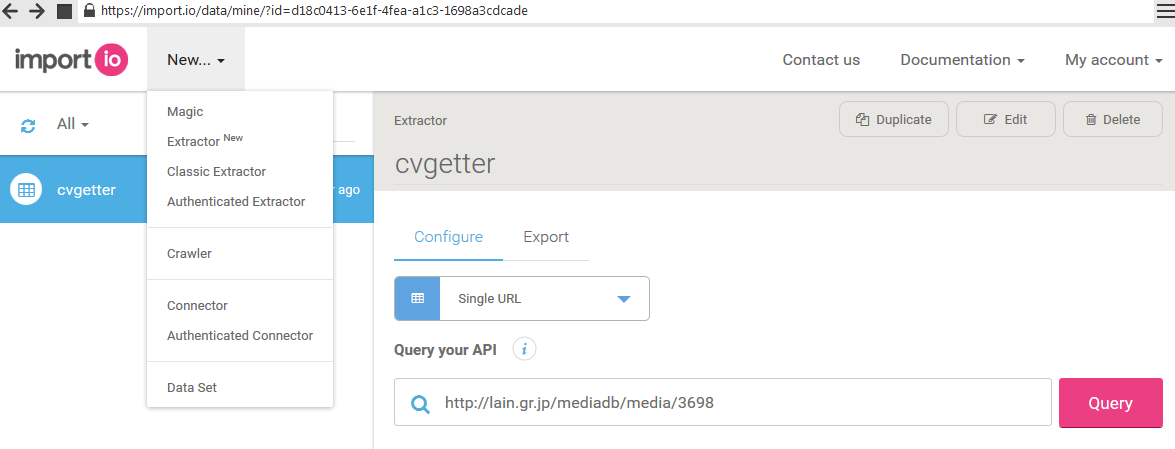
Magicはウェブサービス版で使われている機能と同じで細かい設定をすることができない。
そこで今回はExtractorを選択してより詳しいルールのAPIを作成する。
ちなみにClassic ExtractorとAuthenticated Extractorについてはまだよく分かっていない。
APIの実装については動画やヘルプを参考にしながら行うと良い。
丸投げしているようであるが筆者もまだ分かっていないところが非常に多いため、そちらのほうが確実である。
ここで自動取得モードが適応できれば非常にラッキーである。
ちなみに筆者は確実に行うために、CSSやJSを切って、取得したい部分を2行以上ドラッグで選択というまどろっこしい手段を用いたりした。
なおスパナボタンであるadvanced setting内でxpathやregexを用いて指定することができるため、奥の手としてこれを用いることも出来る。
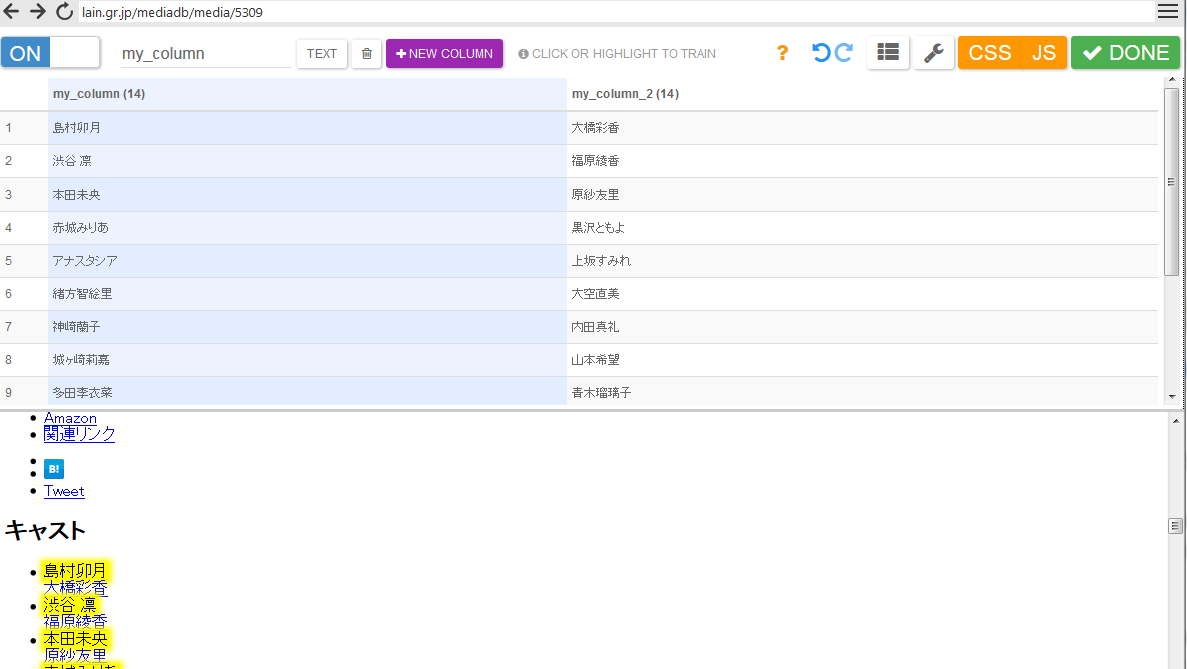
固定値の入力
特定のカラムに同一ページから取得した同じ値を入力したい場合はxpathで直接指定してやるとスムーズである。
xpathはchromeのデベロッパーツールから取得するのが手っ取り早い。
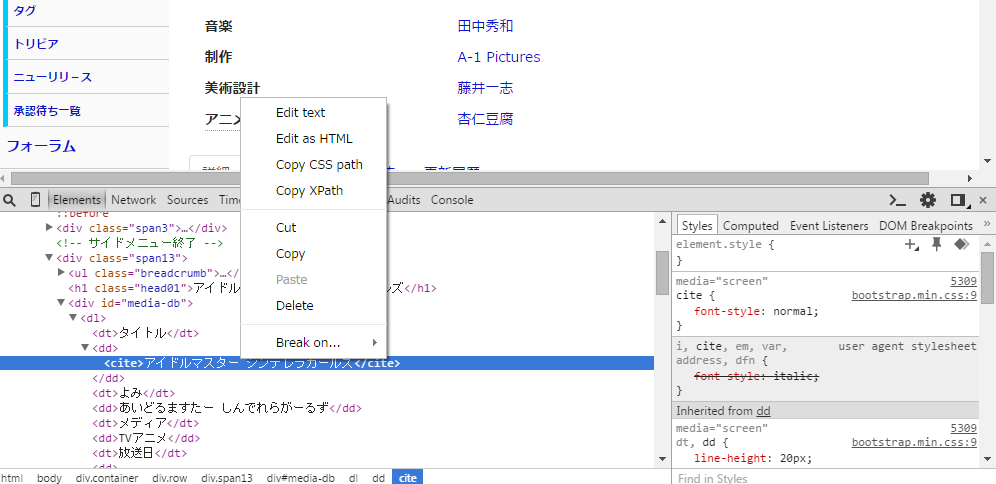
スパナボタンであるadvanced settingからxpathを用いて指定することができる。
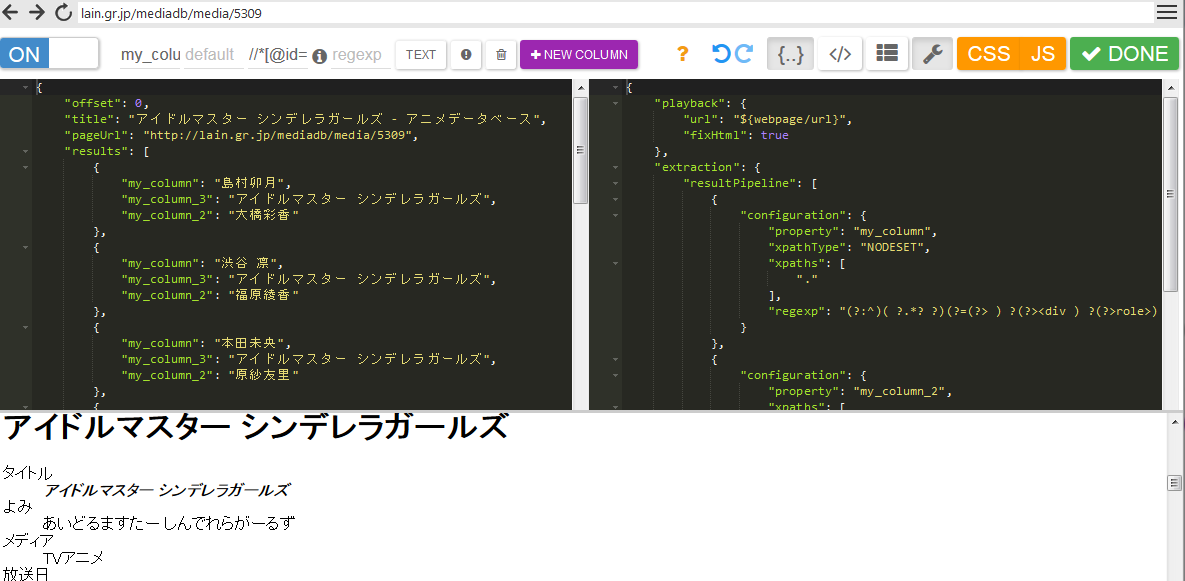
以下のように一括で入力することができる。
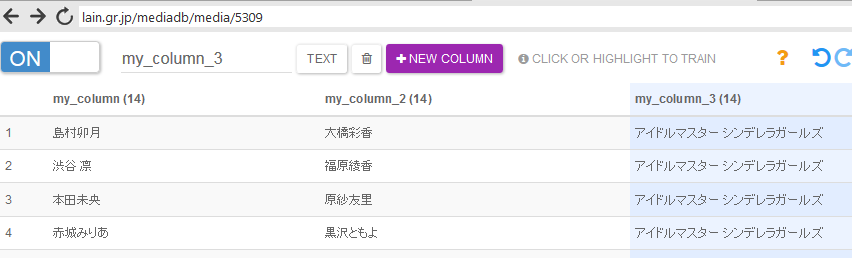
APIの完成
APIが完成したらDONEボタンを押してAPIに名前をつけ、保存する。
これで対象以外のページでもこのAPIを利用してスクレイピングすることが可能になる。
複数のウェブページに対して一括実行
MyDataページから作成したAPIとBulk Exportモードを選択し、取得対象となるページを複数入力する。
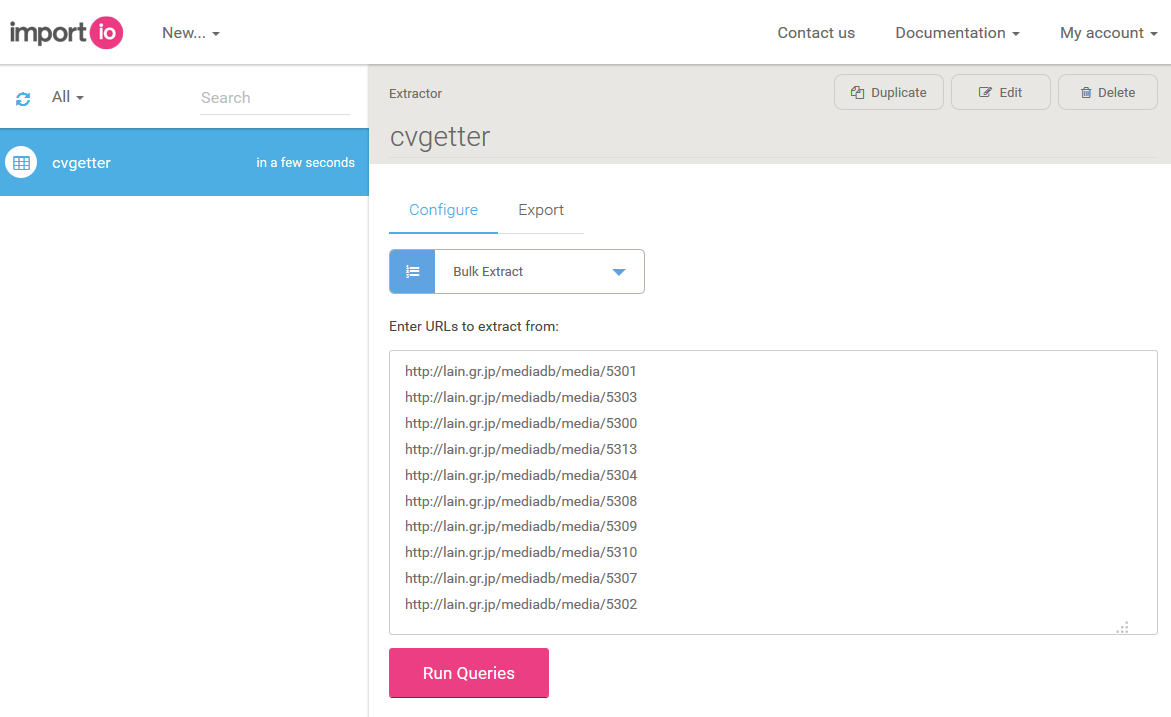
少々時間はかかるが以下のように一括で取得することが出来る。
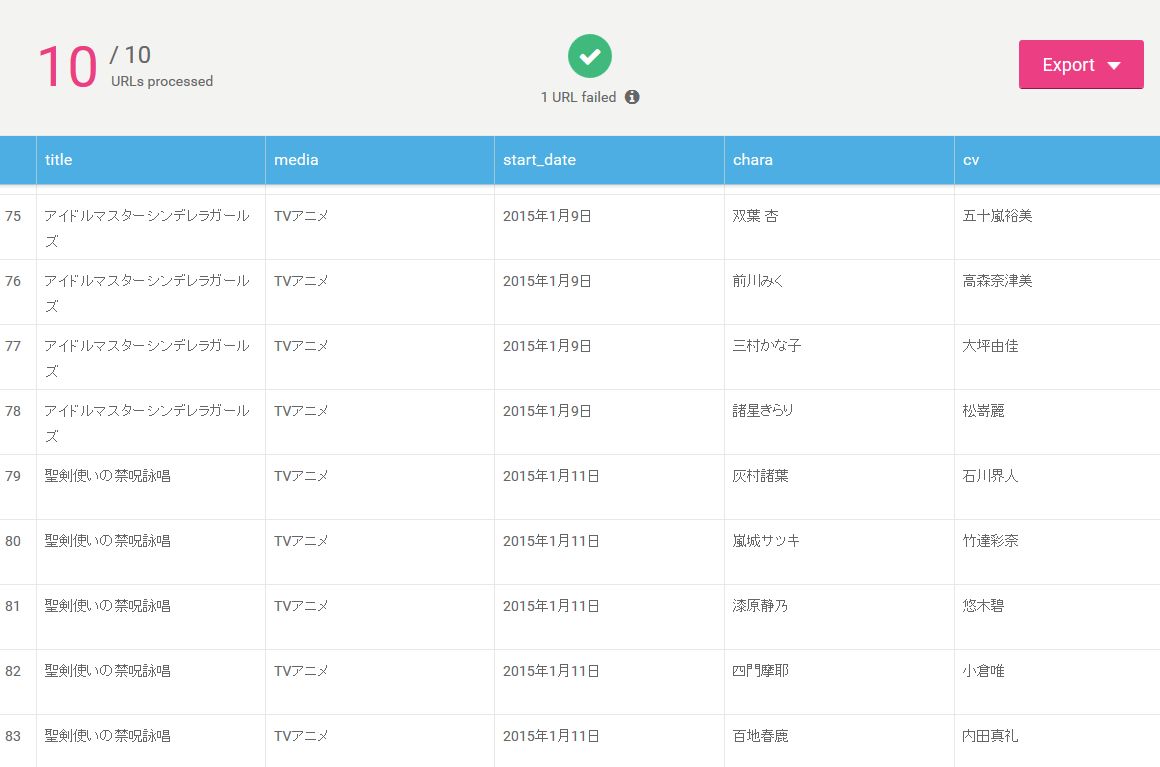
なおCSVで出力した場合、表示されているカラムの順番と出力されているカラムの順番に差があるようである。
スクレイピング先のURLについては自動的に挿入されるようである。

利用雑感
非常に有用なツールであると思われるが、APIのスクレイピングルールの指定が直接できず、それをやりたいと何度も思った。
また.lainはデータの構造が2011年ごろを境に変わっているので、古いデータを取得する場合はそれに合わせたAPIを作る必要がありそうである。