はじめに
「〇〇」を感覚的に理解するシリーズをしばらく書いてみようと思います。
私自身、データサイエンティストにあるまじきほど“感覚派”で、ついつい数式よりも雰囲気で理解しようとしてしまいます。
でも実は、そんな自分でも「なんとなくわかってきた」と思える瞬間があって、同じように統計や時系列でつまずいた人の助けになればうれしいです。
今回は、時系列モデルの中でも最初に出てくる「ARモデル」について、ざっくりとした感覚で紹介していきます。
ARモデルとは?
AR(Autoregressive)モデルは日本語で「自己回帰モデル」と呼ばれます。
名前の通り、「過去の自分の値に影響される」というシンプルなルールを持った時系列モデルです。
たとえば、昨日の体重が今日の体重にちょっと影響する――そんな「昨日の延長線上に今日がある」ようなデータに向いています。
昨日と似た値が出やすいとか、反動で逆方向に動きやすいといった「クセのある連続性」を捉えるのが得意です。
モデルの数式は以下のようになります(「p」は過去何日分を見るかという意味です):
X_t = c + \sum_{i=1}^{p} \phi_i\, X_{t-i} + \varepsilon_t,\qquad \varepsilon_t \sim \mathcal{N}(0,\sigma^2)
もっと簡単に言うと、
「今日の値 = 定数 + 過去の値 × 重み + ちょっとした誤差」
みたいな感じです。
特に、1日前の値だけを見る AR(1) モデルはこんな式になります:
X_t = c + \phi_1\, X_{t-1} + \varepsilon_t
定常性って何やねん
「定常性」とは、データを生み出している確率的な仕組み(=分布)が時間とともに変わらないことを指します。
たとえば、毎日同じ“くじ引き”から値が出てくるような状態が定常です。
一方で、途中から別のくじ引き(=違う分布)になってしまったら、同じモデルで扱うのはしんどいですよね。
これがいわゆる非定常な状態です。
ただし、「昨日の値に引きずられる」といった自己依存があること自体は問題ありません。
むしろARモデルはその**ラグ(何日前まで遡るか)**に依存する構造を前提としています。
つまり、過去との関係(ラグ依存)はあっても、背後の確率モデル自体が時間によって変わっていないなら、定常とみなしてOKです。
誤差項って何やねん
ARモデルの式に出てくる「(\varepsilon_t)」は、誤差項(ごさこう)やノイズと呼ばれる部分です。
これは「人間には予測できないブレ」みたいなもので、たとえば「昨日まで順調にダイエットしてたのに、今日はケーキを食べた」みたいなイレギュラーな出来事がここに入ります。
この誤差は普通、「平均0でランダムにブレる」という前提で扱います。
個人的な感覚
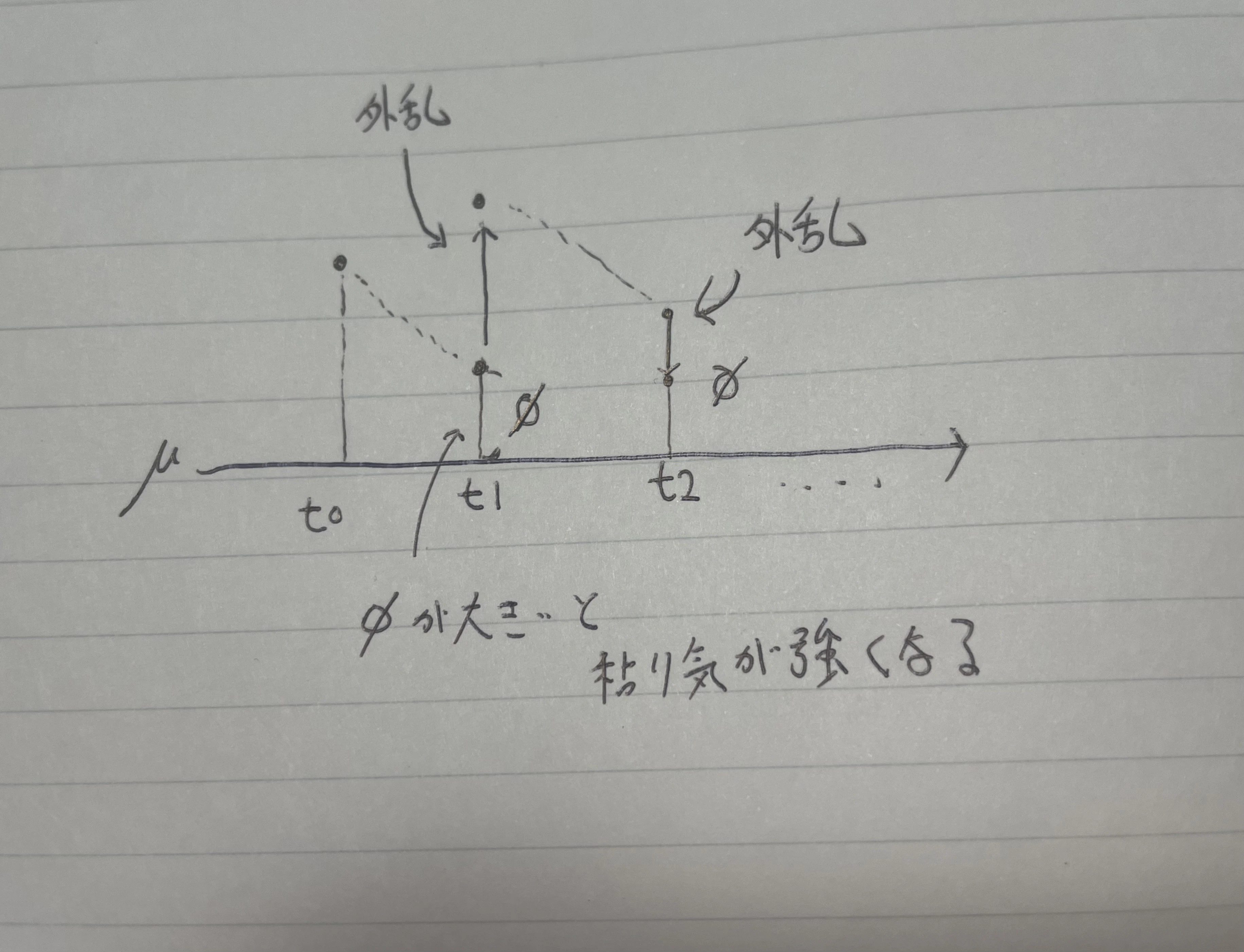
ARモデルは、個人的には「時間の粘り気(=慣性)」を数式で表しているイメージです。
実務でも、「このデータってどれくらい昨日の影響を引きずってるの?」を知りたいときに使います。
(\phi)(ファイ)という係数が1に近いと「ほぼ昨日の値と同じ」、
逆に0に近いと「昨日は関係なく、ほぼノイズ」みたいな解釈ができます。
おわりに
ARモデルを学び始めた頃は、定常性の前提や AR と MA の違いに悩みました。時系列データはビジネス現場にあふれているのに、適切に扱われないことが多いのが現状です。この記事が、少しでも扱いやすさのヒントになれば嬉しいです。
なお、高次数の AR モデルはほとんど経験がありません。もし活用例をご存じでしたら、ぜひ教えてください。