この記事は NTTコミュニケーションズ Advent Calendar 2020 の15日目の記事です。
TabNetという機械学習モデルについて紹介します!
概要
- TabNetは昨年公開されたNNのアーキテクチャで、テーブルデータを学習するためのモデルである
- 最近開催されたKaggleのコンペで(アンサンブルではありつつも)上位ソリューションで使われた
- この記事では、タイタニックを使ってテーブルコンペでよく利用されるモデルであるLightGBMと比較した
TabNet
TabNetは昨年公開されたNNのアーキテクチャで、テーブルデータを高性能かつ解釈可能に学習できます。
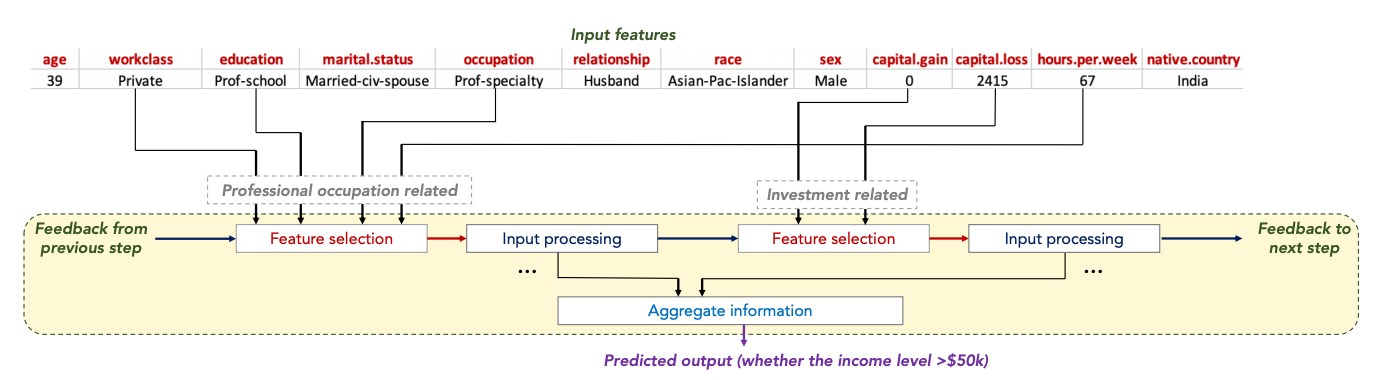
下記の画像がネットワークの構造です。Attentive Transformerという機構を用いて特徴量の選択をしながら学習します。そのため、学習後にこのマスクを参照することで、どのような特徴量が重要であったかを解釈することができます。
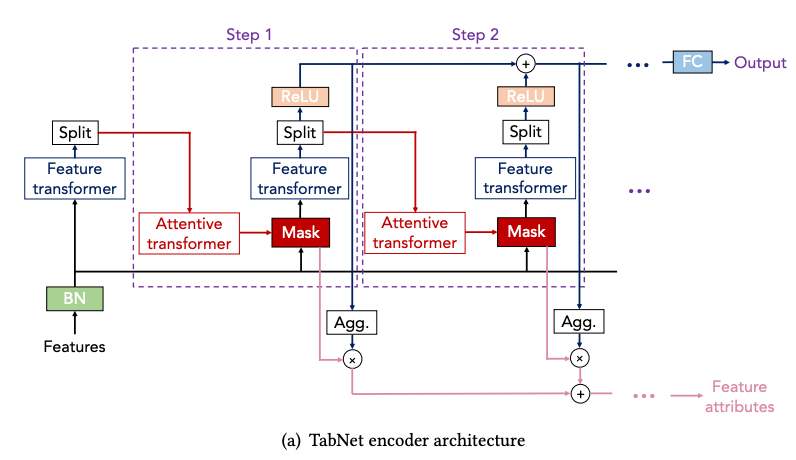
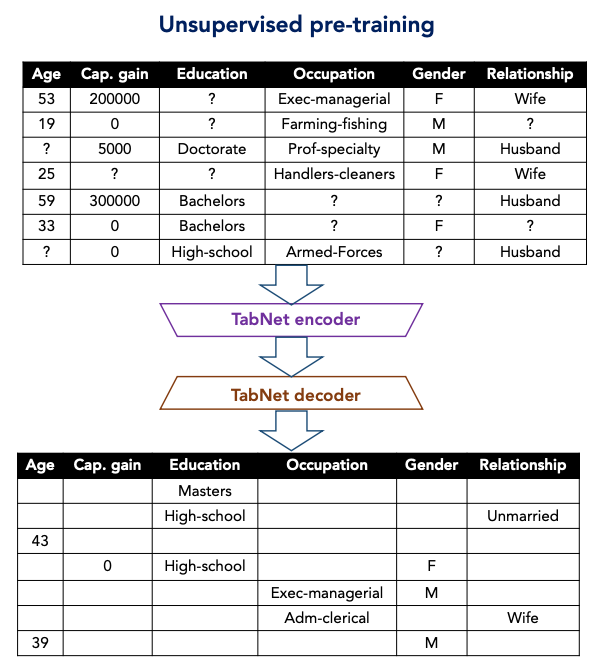
現実世界のテーブルデータには相互依存する特徴量(例えば学歴と職業)が含まれるため、教師なし事前学習が有効であると考え、下記のような事前学習を導入しました。(Denoising AutoEncoderのようなイメージでしょうか)
GCP AI Platformの組み込みアルゴリズムとしても採用されています。
https://cloud.google.com/ai-platform/training/docs/algorithms
論文
ソースコード
公式の実装
https://github.com/google-research/google-research/tree/master/tabnet
論文の著者の公式GitHubではありませんが、Kaggleではこちらのソースコードが使われていました。scikit-learnライクなインターフェイスで学習や推論できる実装です。
https://github.com/dreamquark-ai/tabnet
こんな感じで簡単に使えます。(後述のKaggleノートブックより抜粋)
from pytorch_tabnet.tab_model import TabNetClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
tabnet_params = dict(verbose=40)
clf = TabNetClassifier(**tabnet_params)
kf = KFold(n_splits=5, shuffle=False)
scores = []
for train_index, val_index in kf.split(x_train, y_train):
x_tr = x_train[train_index]
x_val = x_train[val_index]
y_tr = y_train[train_index]
y_val = y_train[val_index]
clf.fit(
x_tr, y_tr,
eval_set=[(x_val, y_val)],
patience=100,
max_epochs=300,
)
scores.append(accuracy_score(y_val, clf.predict(x_val)))
print(scores)
print(np.mean(scores))
解説動画
ネットを調べてみても論文以外の情報があまり見つかりません。この動画を観ると少しイメージがつかめます。
https://www.youtube.com/watch?v=ysBaZO8YmX8
MoA
非常に簡単に言うと、あるレコード(遺伝子発現データと細胞生存能データ)がどのような薬の作用によるものかを予測するテーブルコンペです。(正確には、作用機序を予測するマルチラベル分類)
2020年9月3日〜12月3日まで開催されていたコンペで、4373チームが参加しました。
ちなみに私もTabNet片手に参加しましたが、残念ながらメダル獲得には至りませんでした。
優勝者のソリューション
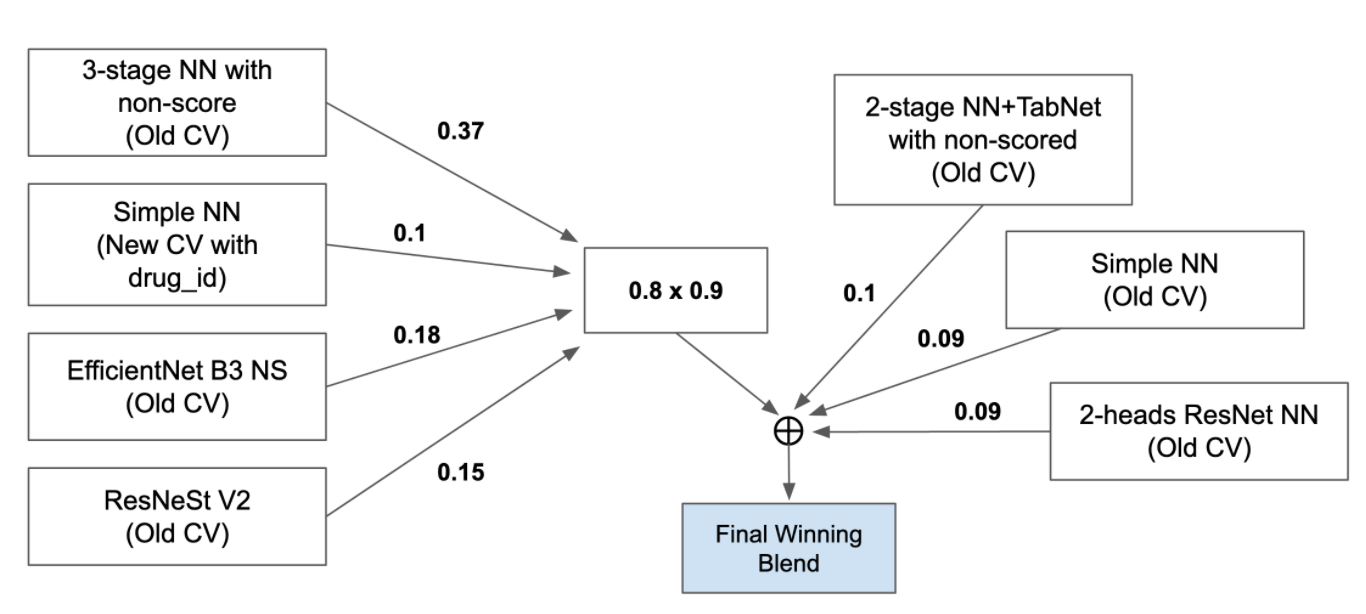
NNを中心としたアンサンブルを用いており、その中にTabNetも用いています。テーブルコンペなのになぜEfficientNetやResNetを用いているのかについては、話の本筋からそれるのでこの記事では扱いませんが興味がある方はこちらを読むと良いでしょう。
優勝者に限らず、上位ソリューションのほとんどがTabNetを使っていました。TabNetを含めた浅めのNNが有効なコンペだったように感じました。
LightGBMとの比較
2020年現在、テーブルコンペではGBDT(勾配ブースティング決定木)と呼ばれるアルゴリズムを採用する競技者が多いです(もちろん、アンサンブル等でDeep Learningが利用されることもよくあります)。GBDTの中でも最もよく利用されるのがMicrosoft社のLightGBMと呼ばれるライブラリです。
今回はTabNetとLightGBMを比較してみたいと思います。比較用のデータとして、おなじみのTitanicデータを用います。5fold CrossValidationを行いAccuracyの平均値を比較しました。ソースコードはKaggleノートブックとして公開しています。
実行すると下記のような結果が得られます。
| 5fold CV | |
|---|---|
| LightGBM | 80.9 |
| TabNet | 80.5 |
まだ私の実力不足でTabNetのハイパーパラメータの勘所がわからないため、ハイパーパラメータのチューニングはしていません。また、条件を合わせるためにLightGBMについてもチューニングはしませんでした。
そのため、どちらの精度ももう少し上がるかとは思います。あくまで参考値です。それでもチューニング無しでTitanicでのCVが80%であればかなり使えるレベルといって良いと思います。
まとめ
TabNetやその応用は、今後のテーブルデータの機械学習における主要な武器の一つになっていくことが予想されます。機械学習エンジニアな方は、動向をキャッチアップされると良いのではないでしょうか!