本記事はDatabricks アドベントカレンダー2024 22日目の記事です。
こんにちは、てぃーおみです。
好きなDatabricksのサービスはDatabricks Assistantです(最高だよね)
この記事ではDatabricksのSecurity Analysis Tool (以降SAT)について紹介したいと思います。SATについては日本語での解説記事があまり見当たらなかったので、ツールの概要から丁寧に解説していきたいと思います。
はじめに
SATはDatabricksアカウントおよびワークスペースのセキュリティ構成を分析し、セキュリティのベストプラクティスに対する遵守状況をチェックしてくれるツールで、Databricks社が公開しているセキュリティ&トラストセンターでも紹介されています。
REST APIを介して収集される様々な情報は、最終的に以下のような単一のDatabridcks AI/BIダッシュボードで表現され、セキュリティベストプラクティスに対しての逸脱状況を重大度別(高・中・低)に報告してくれます。
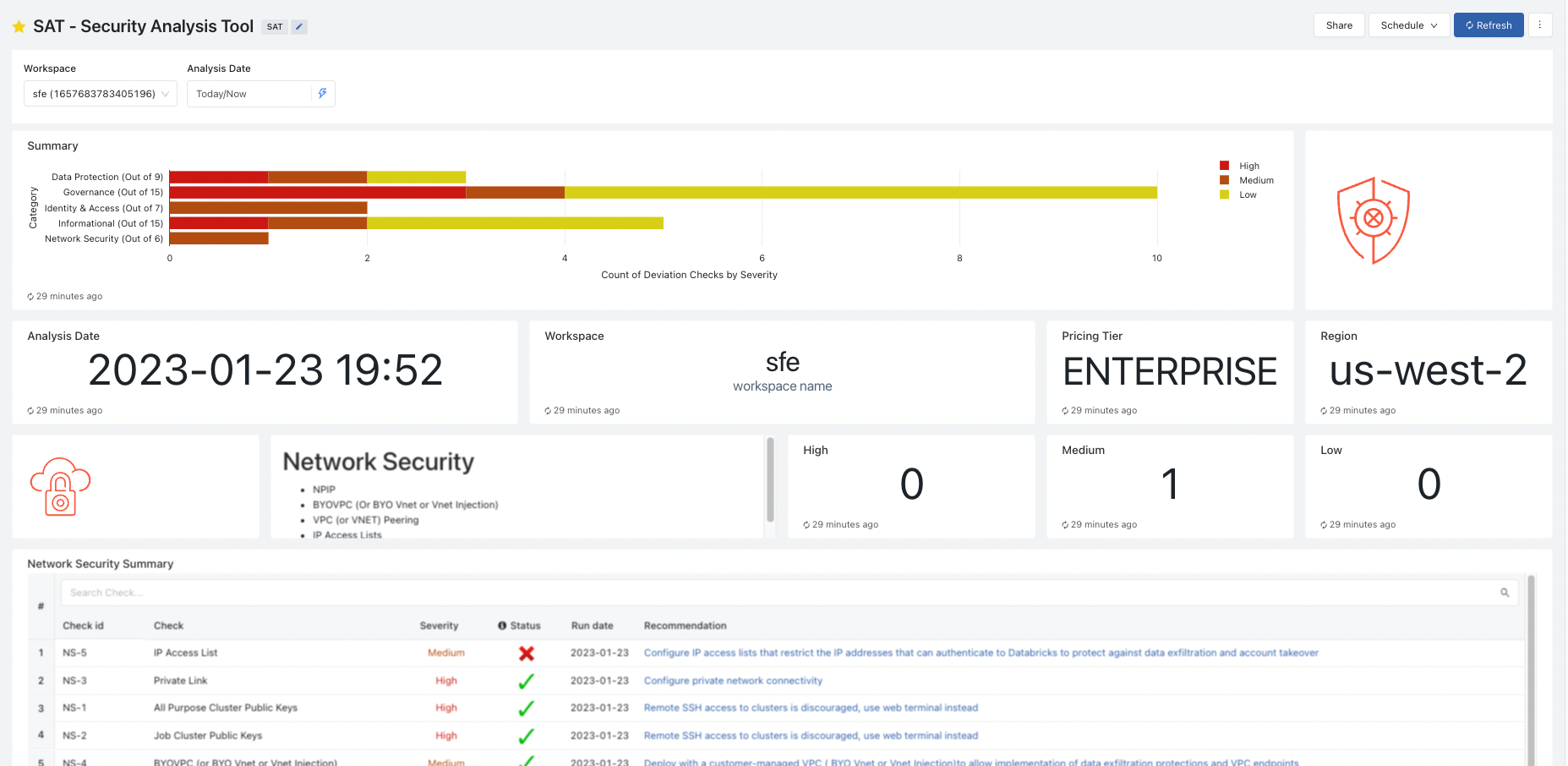
出典:https://github.com/databricks-industry-solutions/security-analysis-tool
AWSのSecurity Hubや、AzureのSecurity Centerを利用されたことがある方なら、まさにこれらのDatabridcks版、といったイメージを持っていただければと思います。
本ツールはこちらのGitHubリポジトリで公開されています。
ということでこちらのGitHubを見ながら早速触っていきます。
セットアップ
SATはDatabricksがホスト可能な全てのクラウドプロバイダー(AWS,Azure,GCP)で利用可能です。今回は筆者の実行環境がDatabricks on AWSなので、AWSのセットアップガイドをもとに設定を進めていきます。
※なお今回は標準セットアップガイドをもとに進めていきますが、Terraformベースのセットアップも選択可能です。Terraformに慣れている方はこちらの方がよろしいかと。
セットアップ前に、お手元の実行環境で次の条件が満たされていることを確認してください。
- Python3.9以上がインストール済みであること
- Databricks CLIがインストール済みであること
※未インストールの方はこちらを参考にインストールを完了させてください。 - 対象のワークスペースからPyPiへアクセス可能なこと(閉域環境下は注意)
1. サービスプリンシパルの用意
まずはサービスプリンシパルを作成していきます。
1-1.各管理者ロールの付与
アカウントコンソールからサービスプリンシパルを作成し、サービスプリンシパルに対してアカウント管理者ロールを付与します。
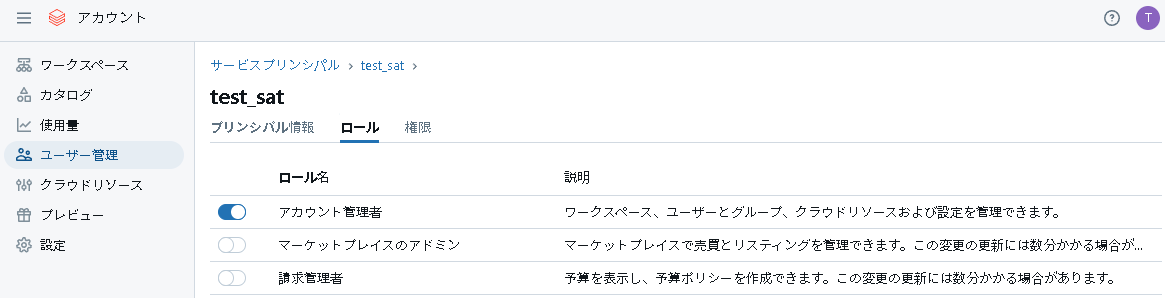
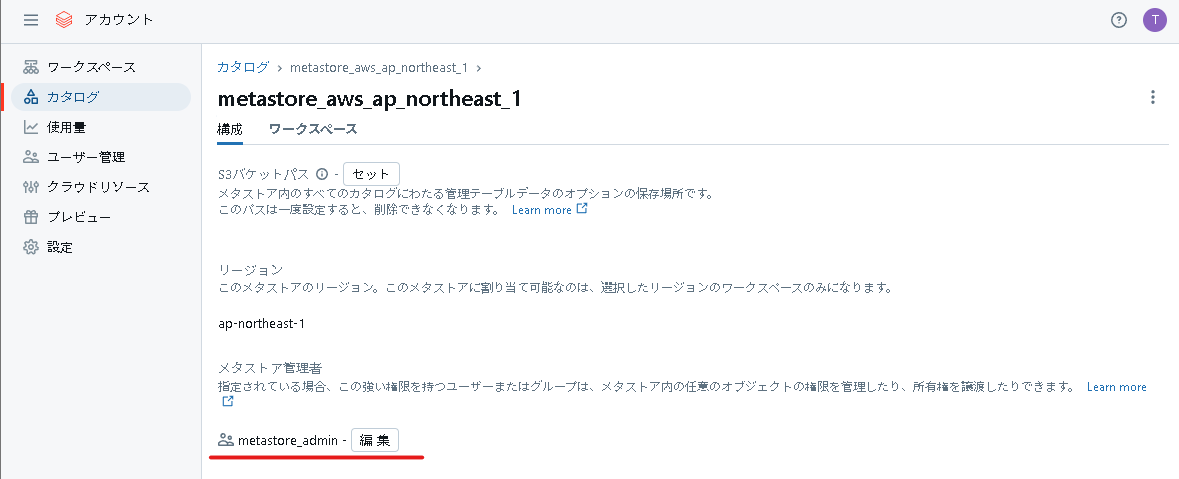
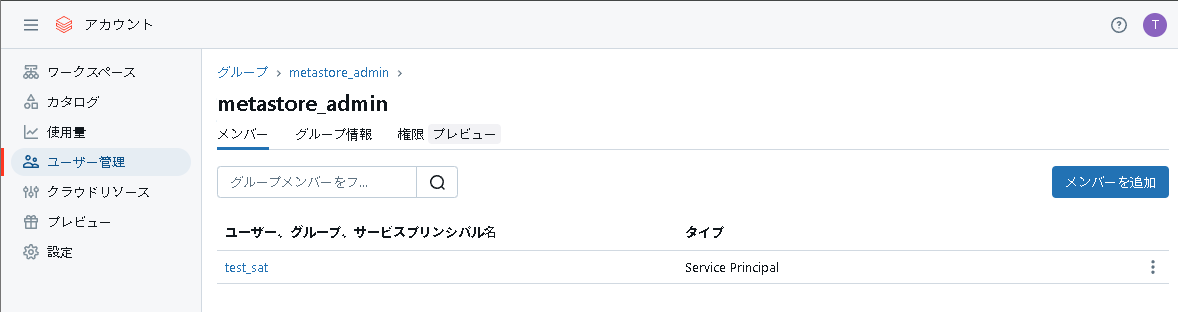
次にメタストア管理者ロールを付与します。ちなみにメタストア管理者はグループ単位で指定するのが望ましいです。今回はmetastore_adminというメタストア管理者グループに加入させます。
最後にワークスペース管理者ロールも付与します。
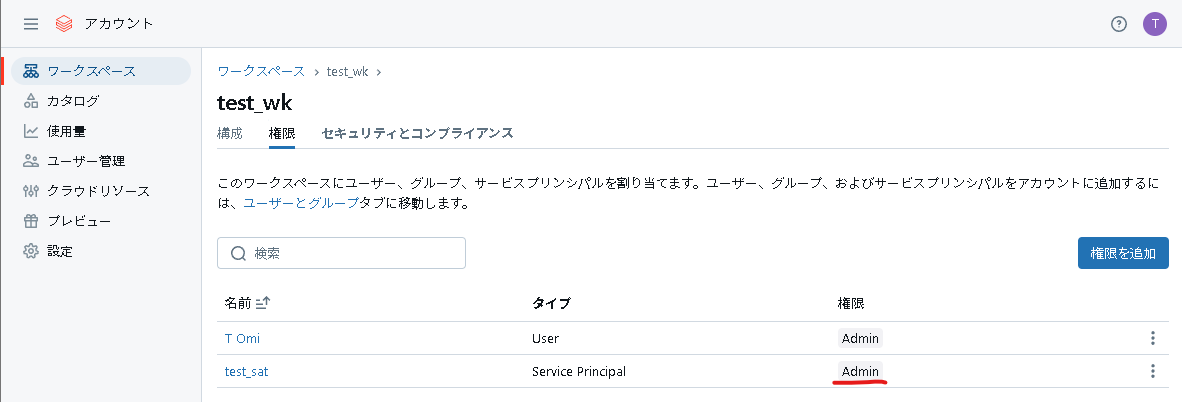
1-2. OAuthシークレットの作成
OAUthシークレットを作成します。
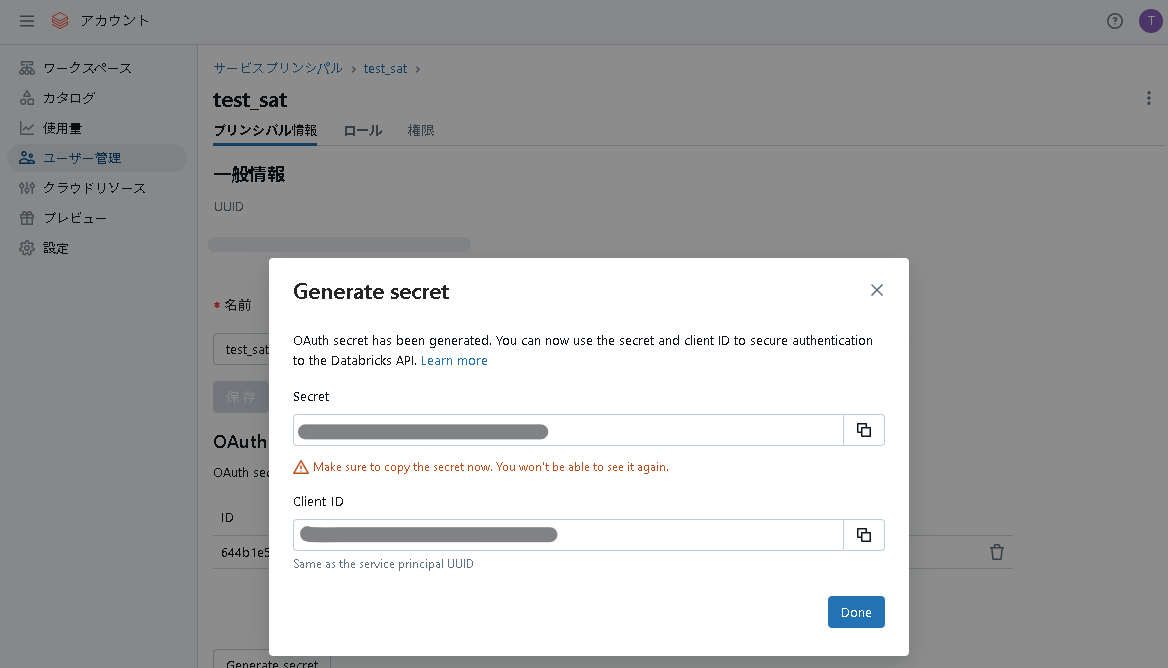
画面に表示されたクライアントIDとシークレットを保存します。
2. DatabricksCLI経由でのSATインストール
2-1. Databridcks CLIのプロファイル設定
Databricks CLIで使用するプロファイル(ファイル名:.databrickscfg)を作成します。
こちらのドキュメントを参考に、以下のように記述します。
[<任意のプロファイル名>]
host = <Databricks ワークスペースのURL>
client_id = <Databricks サービス プリンシパル クライアントID>
client_secret = <Databricks サービス プリンシパル シークレット>
サービスプリンシパルのIDとシークレットは先ほど取得したものを指定してください。
2-2. SATインストール
一通り事前準備が終わりましたので、ついにSATをインストールします。まずはリポジトリをローカルにクローンします。
git clone https://github.com/databricks-industry-solutions/security-analysis-tool.git
ターミナル上でinstall.shを実行します。
$ cd security-analysis-tool
$ ./install.sh
必要情報を入力していきます。
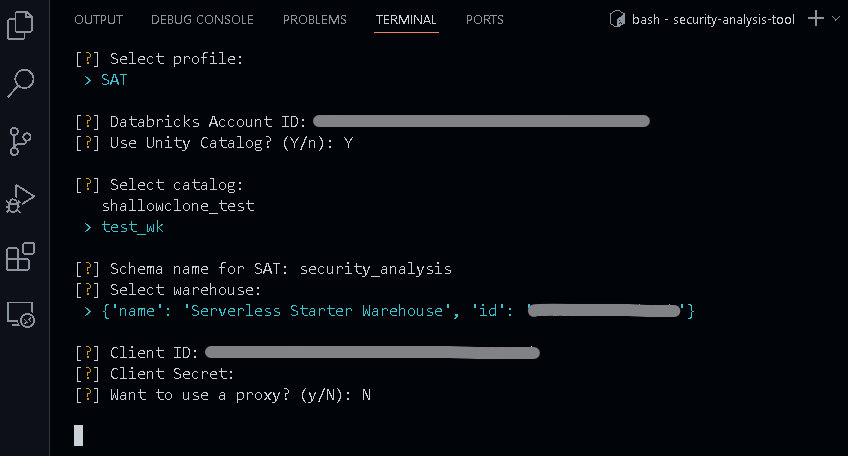
簡単に説明していきたいと思います。
-
一番初めはプロファイル名を選択します(
.databrickscfg内に複数のプロファイルが記述されている場合は、適切なプロファイル名を選択してください) -
DatabricksのアカウントIDを入力します。アカウントコンソールの右上のアイコンからアカウントIDを取得可能です
-
SATはUnity Catalog内のカタログにスキーマを作成するので、その際に使用するカタログを決定します
-
上で選択したカタログ内に作成されるスキーマ名の選択になります
-
ユーザーのワークスペース内のSQLウェアハウスを利用しますのでその確認です
-
クライアントIDとクライアントシークレットは上述のサービスプリンシパルの情報を入力してください
-
プロキシを使用している場合は「y」を選択してプロキシサーバーを指定することが出来ます
こんな画面が出ましたら、セットアップ完了です。
3. ジョブの実行
ワークスペースにアクセスし、ワークフロー画面でSAT Initializer Notebook (one-time)とSAT Driver Notebookの2つのジョブが作成されていることを確認してください。
その名の通り、SAT Initializer Notebook (one-time)は初回のみ実行するジョブで、SAT Driver Notebookはスケジュール設定がされているジョブになります。
ワークスペース内の情報を収集してダッシュボードを作成するには、まずSAT Initializer Notebook (one-time)を実行し、そのあと続けてSAT Driver Notebookを実行してください
(SAT Initializer Notebook (one-time)を実行しただけだと、ダッシュボード自体は作成されますが、データ収集がされていない状態で真っ白なダッシュボードになるかと思います、2つとも実行するようにしてください)
ダッシュボードの確認
ジョブを実行した後、サイドバーからダッシュボードを選択し、SAT - Security Analysis Tool (Lakeview - Experimental)という名前でこんな感じのダッシュボードが作成されているはずです。
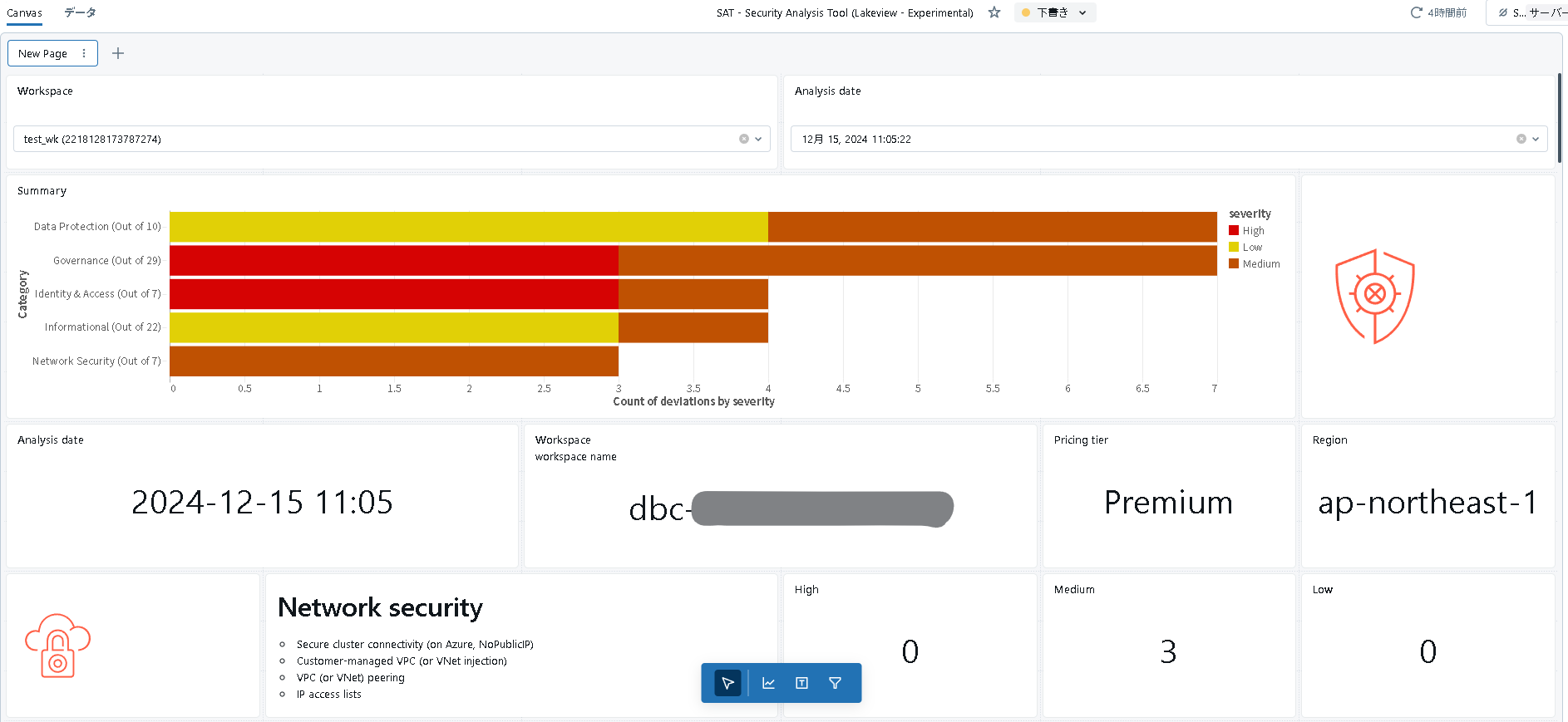
色々と情報提供してくれていますね。
具体的には、SATは以下の5つのカテゴリごとにセキュリティベストプラクティスに対しての逸脱状況を整理してくれています。
- Network Security
- Identity & Access
- Data Protection
- Governance
- Informational
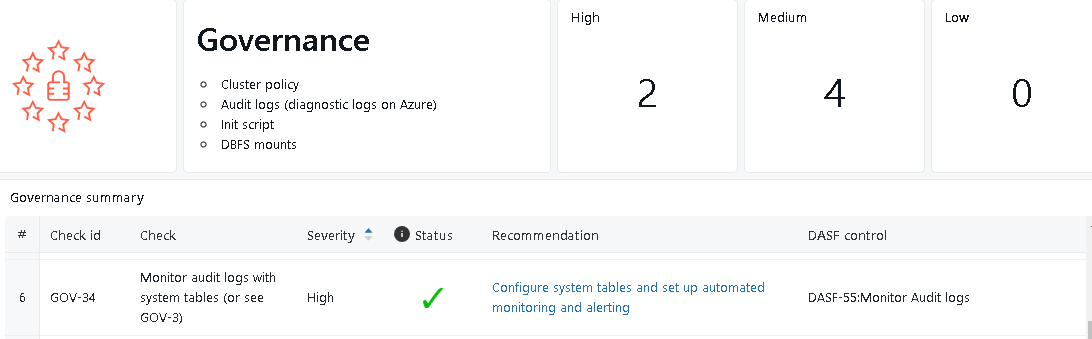
例えばGovernanceを見てみます。
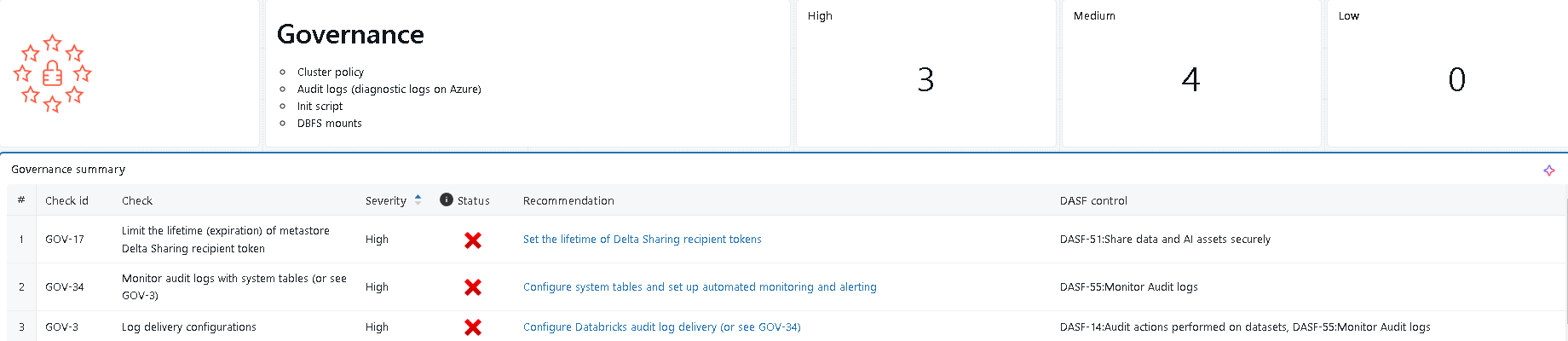
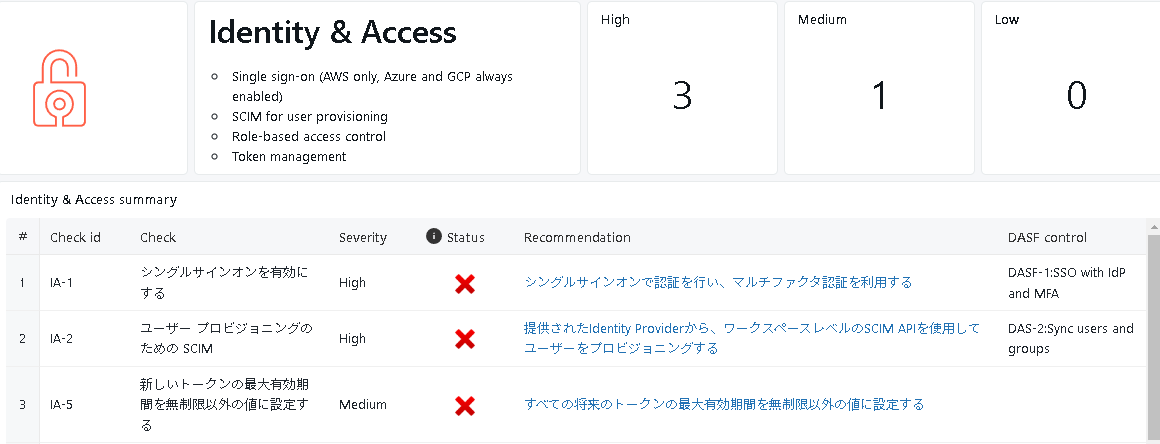
なんか色々と怒られていますが、特に重要度の高い(High)項目が3つあるみたいですね。
そのうちの1つを確認してみます。

チェック項目には「Monitor audit logs with system tables」と記載されていますので、システムテーブルを有効化してちゃんと監査ログテーブルをモニタリング出来るようにしなさい、と怒られているようです。
ちなみに各チェック項目のRecommendation列には、チェック項目に関連する公式ドキュメントのURLがマッピングされているので、具体的に何をしたら良いのか?と迷った時もこちらを見れば対策出来そうですね。
ということでRecommendation列に記載の以下のURLを参考に、監査ログシステムテーブルを有効化します。
system.access.auditテーブルを有効化したところで、もう一度SAT Driver Notebookジョブを実行してダッシュボードを更新してみます。
無事にStatusが更新されました!
こんな感じで他の項目についても対応していけば、セキュリティベスプラに準拠したDatabricks環境が出来上がっていくという訳ですね。
カスタマイズしてみる
一通り触ってみましたが、折角なのでちょっとだけいじってみます。
ダッシュボードの日本語化
デフォルトのダッシュボードでも十分分かりやすいですが、チェック項目等が英語になっているので、これを日本語にしてみたいと思います。
ダッシュボードの裏側で使用されている各テーブルは、セットアップ時に指定したカタログ配下のsecurity_analysisというスキーマ内に格納されています。これらの中でチェック項目やRecommendation列については、以下のsecurity_best_practicesで管理されています。
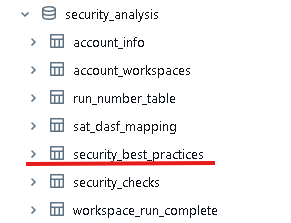
このテーブルの英語の文章を、Databricks上でホストされているdatabricks-meta-llama-3-3-70b-instructで日本語に変換してみたいと思います。コーディングはちょっとだけDatabricks Assistant君に協力してもらいました。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import StringType
import pandas as pd
w = WorkspaceClient()
def translate_to_japanese(text: pd.Series) -> pd.Series:
responses = []
for t in text:
response = w.serving_endpoints.query(
name="databricks-meta-llama-3-3-70b-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="あなたは優秀な翻訳家です。与えられた英語を適切な日本語に翻訳してください。"
),
ChatMessage(
role=ChatMessageRole.USER, content=t
),
],
max_tokens=500,
)
responses.append(response.choices[0].message.content)
return pd.Series(responses)
# Register the Pandas UDF
translate_to_japanese_udf = pandas_udf(translate_to_japanese, StringType())
# Read the data
data = spark.sql("SELECT * FROM <カタログ名>.security_analysis.security_best_practices")
# Collect the data to the driver
data_pd = data.toPandas()
# Overwrite 'check' column with translations
data_pd['check'] = translate_to_japanese(data_pd['check'])
# Overwrite 'recommendation' column with translations
data_pd['recommendation'] = translate_to_japanese(data_pd['recommendation'])
# Convert back to Spark DataFrame
data_translated = spark.createDataFrame(data_pd)
# Write the translated data back in Delta format
data_translated.write.mode("overwrite").saveAsTable("<カタログ名>.security_analysis.security_best_practices")
こんな感じで日本語に出来ました。これで再度ダッシュボードを更新してみたいと思います。
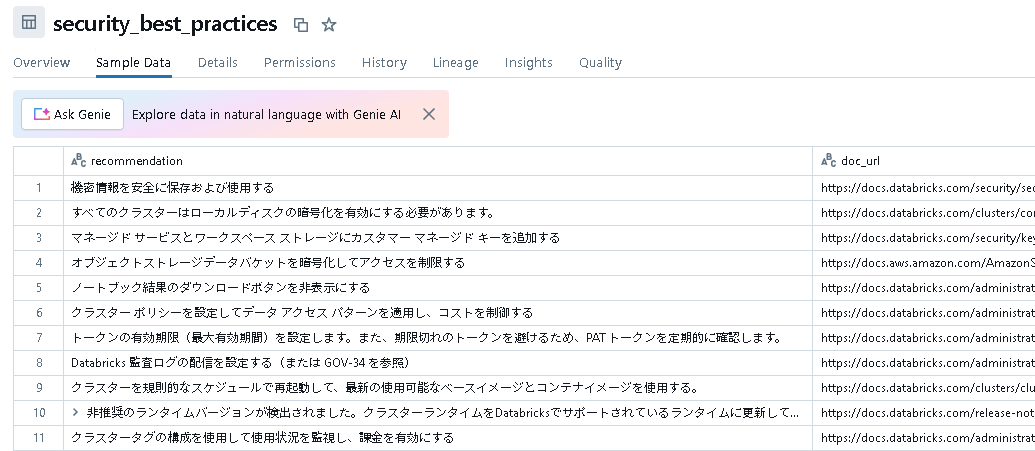
ダッシュボードの情報を日本語で確認出来るようになりました!
ジョブのスケジュール設定を変更する
今回の標準セットアップではシェルスクリプトを実行しただけでしたが、実は裏側ではDatabricks Asset Bundlesが使用されています。
ジョブの設定画面を見ると以下のようなポップアップが確認出来ると思います。
SAT Driver Notebookのジョブ設定を変更するために、YAMLファイルを確認してみます。dabs/dabs_template/template/tmp/resources/sat_driver_job.yml.tmplを覗いてみてください。
resources:
jobs:
sat_driver:
name: "SAT Driver Notebook"
schedule:
quartz_cron_expression: "0 0 8 ? * Mon,Wed,Fri"
timezone_id: "America/New_York"
tasks:
- task_key: "sat_initializer"
job_cluster_key: job_cluster
libraries:
- pypi:
package: dbl-sat-sdk
notebook_task:
notebook_path: "../notebooks/security_analysis_driver.py"
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
data_security_mode: SINGLE_USER
num_workers: 5
spark_version: {{.latest_lts}}
runtime_engine: "PHOTON"
node_type_id: {{.node_type}}
{{- if eq .cloud "gcp" }}
gcp_attributes:
google_service_account: {{.google_service_account}}
{{- end }}
スケジュール設定を見ると、毎週月曜日、水曜日、金曜日の朝8時に実行されるよう設定されていますが、タイムゾーンが"America/New_York"になっているのがちょっと気になります。ということで以下のように変更してみます。
schedule:
quartz_cron_expression: "0 0 8 ? * Mon"
timezone_id: "Asia/Tokyo"
こちらの内容でdatabricks bundle deployコマンドを実行してみると。。
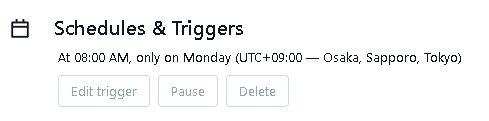
変更できました!
おわりに
SATの基本的な機能について触ってみましたが、紹介出来なかった部分がまだまだありますので(特にAsset Bundlesの部分はかなり端折ってしまいました)、気になった方は是非実際に触っていただければと思います。