SRE Advent Calendar 2018 6日目の記事を担当させていただきます@bayashi_okです。
1日目の記事にもありましたがまさしく監視は網だと感じています。
網目を大きくすれば引っかかるものは限られるし、網目を小さくすればかかり過ぎて仕訳が難しくなる。
今でこそ色んなツールが出てきて機能も増え柔軟な監視ができるようになりましたが、以前は古くからある網で職人が上手く魚を取っていても、新米が同じ網で同じ量の魚を取ることはできにくい状態でした。
同じ網でも人によって獲れる魚が違う場合があったのです。
そのため監視は常にだれが見てもアクションの可否がわかる状態であることが理想です。
(もちろん時と場合によって職人の勘が必要になってくることもあります。)
そしてそれを実現させようとしているのがSREのモニタリングの考え方だと思っています。
前提
SREのモニタリングの記載としては以下のように書かれております。
これまで一般的だったモニタリングのアプローチは、特定の値や条件を監視し、閾値を超えたり条件が満たされた場合に、メールのアラートを発するというようなものでした。人間がメールを読み、何らかの対応アクションの必要性を判断しなければならないようなシステムは、根本的に欠点を抱えています。モニタリングにおいては、アラートの領域のどの部分をとっても人間の解釈が必要であってはならないのです。その代わりに、ソフトウェアが解釈を行い、人間はアクションを行わなければならない時のみ通知を受けるようになっているべきです。
そしてその中で効果的なモニタリング出力が3つ紹介されています。
- アラート
- 人間が即座にアクションを起こして対応し状況を改善しなければならない状態
- チケット
- (即座ではないが)人間がアクションを起こして対応しなければいけない状態
- ロギング
- 人間が見る必要はないものの調査の際に記録されるもの
ただこの情報だけだと今後どのように監視を行って行けばいいのか、従来の監視から何を変えればいいのかが不確定です。
まずこれらの3種類は部分集合でなければならないと考えています。
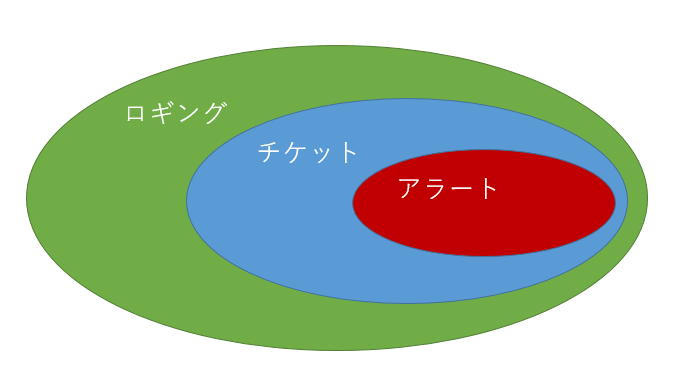
つまりこのような状態です。
チケットとして切り分けられるものはロギングも含まれ、
アラートとして切り分けられるものはチケットとロギングも含まれます。
そしてモニタリングの発生量も
ロギング>チケット>アラート
であることが理想です。
ではこれらの切り分けをソフトウェアが行った後、私たちはどのように動けばよいでしょうか。
監視の理想
下記にSREの考え方を元にした理想の監視像をフロー化してみました。※あくまで個人的な見解です。
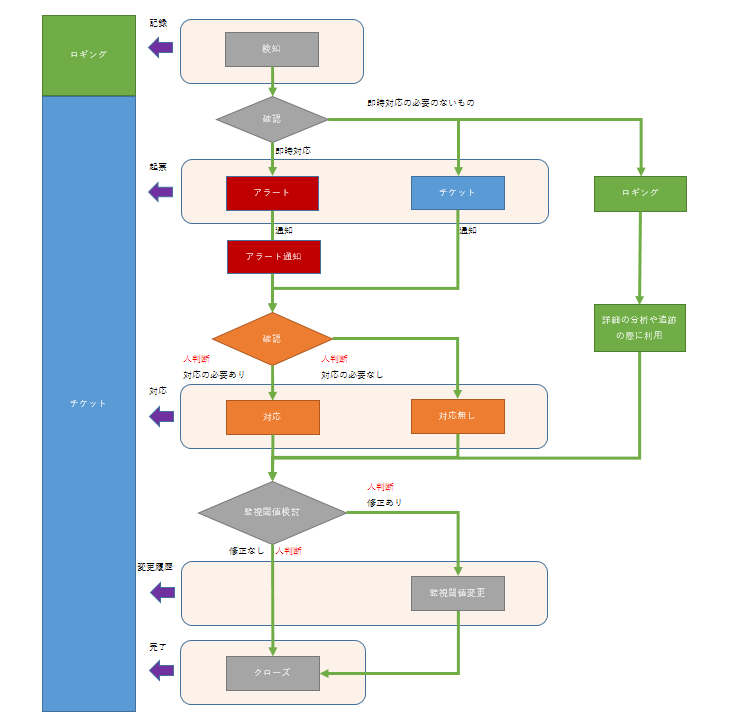
- 各色の意味合いは以下になります。
- 灰色:共有の対応が必要な箇所
- 緑:ロギングとしての対応が必要な個所
- 青:チケットとしての対応が必要な個所
- 赤:アラートとしての対応が必要な個所
- オレンジ:チケットとアラートの対応が必要な個所
まず一定の条件に乗っ取り基準を決めた後それらをソフトウェアに判断をさせます。
これらは従来の「特定の値や条件を監視し、閾値を超えたり条件が満たされた場合」となると思っています。
それらの条件が満たされたものはロギングとして監視システムやメール、Slackなどに記録されます。
次にその中で人の判断が必要になってくるチケットやアラートは何らかの方法でチケット化され管理されなければなりません。
そしてそれらに対しては対応の可否、また監視閾値の見直しなど行い日々運用の中で整備されていく事が大事になってきます。
種類ごとの通知方法について
次にこれらの通知方法について話したいと思います。
ロギング
ロギングに関しては「人間が見る必要はないものの調査の際に記録されるもの」と定義されているため場所としては従来のメールではなく(メールは人間が見る場所となってしまう可能性が高い)監視システム内やロギング専用のチャットツールチャンネルなどが適切でしょう。また詳細の分析や追跡の際に利用できるものである必要が有るのでこれらを可視化しておくと何かと役に立います。
チケット
チケットは「人間がアクションを起こして対応しなければいけない状態」として定義されるため「人間が見る場所に置いておく」と言うのが重要です。
これら各システム管理者の中の取り決めが重要になり、一般的にはメールやタスク管理ツール、チャットツール内の専用のチャンネルなどが適切になります。
アラート
アラートは「人間が即座にアクションを起こして対応し状況を改善しなければならない状態」とあるので「アクションを起こさせる必要のあるものとして発火できるツール」という定義が重要です。
つまりは、電話や通知システム(もちろんメールや専用のチャットツールチャンネル)などに知らせる必要が有ります。
通知方法についてまとめ
以上のように従来のメールによるアラートから、
時代の進化と共に生まれた様々なコミュニケーションツールを駆使し、「人間が見るもの、見ないもの」、「即座にアクションできるもの、できないもの」のツールからルールから選ぶ必要が有るのです。
上記の話を図に簡単にまとめてみました。
※今回はチャットツールをSlackとして例に出させていただきました。
| 通知量 | メール | Slack(チャンネル毎) | 電話 | |
|---|---|---|---|---|
| アラート | 小 | ○ | ○ | ◎ |
| チケット | 中 | ○ | ○ | ✕ |
| ロギング | 大 | × | ○ | ✕ |
メンテナンスについて
次にメンテナンスについて話したいと思います。
先ほど話した、アラート・チケット・ロギングはそれぞれ両間の間に変化する可能性をもっています。

- アラート⇔チケット間で起こりうる例
- アラートとして頻繁に出ているもので影響度の薄いものはチケットでもよいのではないか
- チケットとして出ていても影響度の高いものはアラートに上げるべきではないか
- チケット⇔ロギング間で起こりうる例
- チケットと出ていても頻度が高く影響度のないものはロギングでもよいのではないか
- ロギングとして出ていてもサービスのアクセス量や負荷など時代の流れで影響度が増してきたものはチケットに上げるべきではないか
などです。
これらを日々メンテナンスしていかないといずれ監視は崩壊し前述で上げたような「同じ網でも人によって獲れる魚が違う」現象が発生してしまいます。
※ロギングがいきなりアラートになる事、アラートがいきなりロギングになる事は基本的にはあまりないと考えています。
そのため監視として切り出された通知は監視閾値の見直しと共にモニタリングの種類の見直しも行う必要が有ります。
誰がメンテナンスを行うべきか
ではこれらのメンテナンスは誰が行うべきか。
監視にもいろんな種類があります。
- サービス監視
- リソース監視
- プロセス監視
- ログ監視
etc...
開発や運用が一丸となって改善を行う文化がある組織やサービスの場合はこれが容易ですが、開発チームや運用チーム、インフラチームなどが分かれている場合これは容易ではなくなります。
各チームによる監視の考え方の違い
- インフラチームからみるアプリログ監視
- エラーログの切り分けが難しく判断しづらい
- 開発チームから見るアラート監視
- 日々の開発業務の中メンテナンスを行う余裕がない
- 監視ツールの運用主観が自分達にないとわざわざ依頼を投げ直してもらう必要があり手間がかかり面倒
- その他の懸念点
- システムログ上に出るログやミドルウェアのログなどはどちらが見るのか明確になっていないと対応主幹がわからなくなる
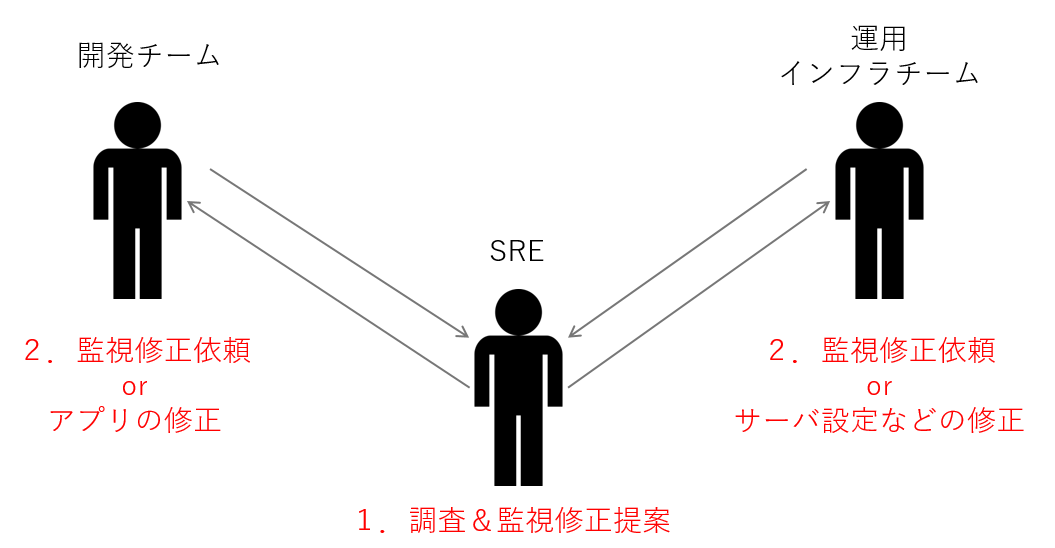
そのためこれらのメンテナンス業務もSREが必要になりうる仕事なのではないかと考えております。
もちろん監視体制が軌道に乗ってきた場合は各チームへの委任も必要になってきます。
最後に
今回は監視の通知とメンテナンスについて重点を置きお話しさせていただきました。
監視の基準と言うのは人によって違う部分があるためこれが正解と言うことはないと思っています。
ただみんなが望む理想の監視としては、いかに早い時間でアラートに気付き、どれだけサービス影響が少ない状態で対応が完了できるかだと私は思っています。
これからも理想の監視に近づくためにSREチームとして信頼性の向上を目指していきたいと考えております。
ということで最後まで読んで頂きありがとうございました!