Neo4jのオンラインコミュニティで質問したら良い回答を、日本語でも記録しておこうと思います。
以前書いたNeo4j ETL CLIのexportコマンドについてですので、そちらを先に読むとわかりやすいかもしれません。
Neo4j ETL CLIを試してみた
経緯
Neo4j ETLのexportコマンドを試していた時に、ノードだけなら非常に高速にimportまで完了するのですが、リレーションを条件に加えた途端に遅くなりました。
70万ノードであれば20秒ほどなのが、250万リレーションで3時間と明らかに遅くなっています。
CSV生成の動き(SFTPのブラウザで確認)はリレーションの両端のノードをチェックしているような挙動だったためCSV生成のロジックを知る必要がありました。
これまではシンプルな質問が多かったためTwitterで聞くことが多かったのですが、JSONとか色々情報の共有が必要かと思い思い切ってコミュニティに登録しました。
使用した環境
- Neo4j 3.5.11
- Neo4j ETL Tool V1.3.1
- PostgreSQL
- Server Memory 8g
発生した事象と状況
PostgreSQLで関連テーブルを使用した結合を行なっていました。
ERは次のような形で同じような構成が3セット、実際はもっとたくさんのカラムがある状況です。
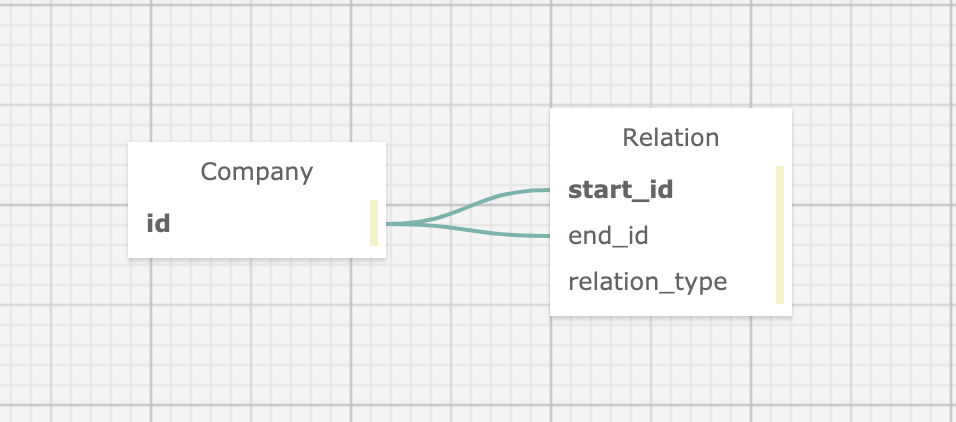
今回は例として会社間の関連を示すようなテーブル構造を想定します。
以前の記事で紹介したneo4j-etl generate-metadata-mappingコマンドで生成されたmapping.jsonを以下のような形に書き換えます。
デフォルトではrelationテーブルも一つのノードとして表現されてしまうため、今回はJOINを用いて結合結果からマッピングを行うようにしています。
[ {
"name" : "NODE1_db1",
"schema" : "db1",
"graph-object-type" : "Node",
"sql" : "SELECT id FROM db1.company AS company",
"mappings" : [ {
"column" : {
"type" : "CompositeColumn",
"table" : "company",
"schema" : "db1",
"role" : "PrimaryKey",
"columns" : [ {
"type" : "SimpleColumn",
"role" : "Data",
"table" : "company",
"schema" : "db1",
"name" : "id",
"alias" : "id",
"sql-data-type" : "INTEGER",
"column-value-selection-strategy" : "SelectColumnValue"
} ]
},
"field" : {
"type" : "Id",
"name" : "",
"id-space" : "db1.company"
}
}]}, {
"name" : "Relation_db1",
"schema" : "db1",
"graph-object-type" : "Relation",
"sql" : "SELECT start_id, end_id, relation_type FROM (SELECT start_id, end_id, relation_type FROM db1.company AS start_company JOIN db1.relation AS relation ON start_company.id = relation.start_id JOIN db1.company AS end_company ON end_company.id = relation.end_id) AS company_relation",
"mappings" : [ {
"column" : {
"type" : "SimpleColumn",
"role" : "Data",
"table" : "company",
"schema" : "db1",
"name" : "start_id",
"alias" : "start_id",
"sql-data-type" : "INTEGER",
"column-value-selection-strategy" : "SelectColumnValue"
},
"field" : {
"type" : "startId",
"name" : "start_id",
"id-space" : "db1.company_relation"
}},{
"column" : {
"type" : "SimpleColumn",
"role" : "Data",
"table" : "company",
"schema" : "db1",
"name" : "end_id",
"alias" : "end_id",
"sql-data-type" : "INTEGER",
"column-value-selection-strategy" : "SelectColumnValue"
},
"field" : {
"type" : "endId",
"name" : "end_id",
"id-space" : "db1.company_relation"
}}, {
"column" : {
"type" : "SimpleColumn",
"role" : "Data",
"table" : "company",
"schema" : "db1",
"name" : "relation_type",
"alias" : "relation_type",
"sql-data-type" : "INTEGER",
"column-value-selection-strategy" : "SelectColumnValue"
},
"field" : {
"type" : "RELATION_TYPE",
"name" : "relation_type",
"id-space" : "db1.company_relation"
}
}]
}
]
SQLの実行結果として、70万ノード、250万リレーションが返却される想定です。
結果
10300s...
約3時間と非常に遅いです。
JSONのリレーション部分を削除すると20秒ほどで完了することと、CSVから直接neo4j-adminの
importコマンドを用いると250万件でも10秒ほどでNeo4jへデータがインポートされることから、リレーションのCSV生成ロジックに何か問題があると考えました。
しかしNeo4j-ETLはエンタープライズ版の機能であるため、ソースが公開されていません。
英語の勉強もかねてコミュニティへ聞いてみることにしました。
コミュニティの回答
こうやって日本語で同じことを書いていると、いかに自分に英語力がないかを痛感します。
少し時間がかかりましたが、うまいことまとまったつもりになったので投下しました。
I want to understand the logic for neo4j-etl cli export
質問した瞬間にすでに入力中の表示がありました。
もっと情報くれとか、そんなことない系の回答かなと思ったのですが、かなり適切な回答を頂きました。
Importing relationships is very very slow. When creating a relationship between two nodes, the database locks both nodes. So it is not even possible to speed it up with parallel processing unless it can be guaranteed that no two processes run at the same time, is making a relationship with an overlapping node.
- Thomas_Silkjaer
今回のデータでいうと、customer_relationのCSV生成中にcustomerテーブルはロックされ対象ノード自体のCSV生成にも影響を及ぼしているようです。やはりチェックがされているのでしょう。
並列処理も複数テーブルが関連する状況では難しいとのこと。
回避策
PostgreSQLのEXPORTでCSVを直接出力し、admin-importのみでインポートが速いと教えて頂きました。この手法、実は以前に試したことがあり速さも実感しているため課題はこれでクローズにしました。
※PostgreSQLの実行計画によっては遅くなることもあるのでチューニング等必要になる場合もありますが、、
まとめ
- ETL Toolで大量データは扱いにくい
- 少量データおよび対象DBの種類が多い場合は使えるかもしれない
- 内部のロジックがわかったことで「なぜ使わないのか」の議論がスムーズになる
- 大量データのインポートにはRDBから直接admin-import用のCSVを生成する方法が一番高速
- Neo4j オンラインコミュニティは有益
これからガンガン英語使えるようになっていかなければ。