概要
- この内容は、私が独自に調査して動作確認を取ったものをまとめたものです。
- OpenDroneMap/ClusterODM/NodeODMの仕組み。
- オプション関連の調査。
OpenDroneMap/ClusterODM/NodeODMの仕組み
[前提知識]OpenDroneMapのパイプライン処理
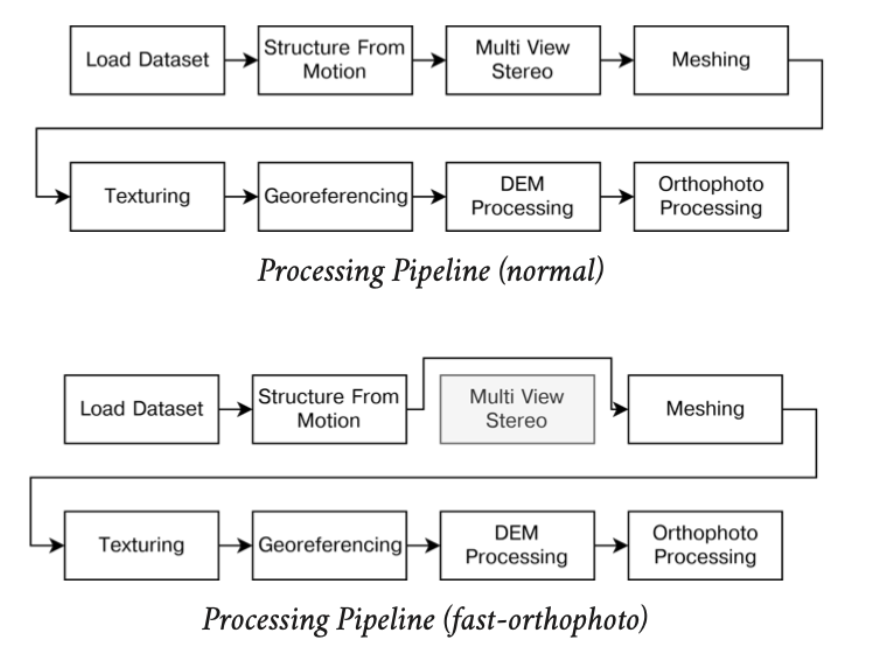
OpenDroneMapのパイプライン処理の流れ
[注意]多少不正確な説明があることをお許しください。
- dataset
前処理。写真のリサイズやEXIFを抽出してGPSの解析をしたりする。 - split
前処理を元に、写真をいくつかのsubmodel(塊)にグルーピングして分割する。 - merge
動きを見ていると全体をsplit-mergeしているわけではないようだ。詳細は後述。 - opensfm
Structure from Motion。sparse point cloudを生成する。デフォルトではここまで分割しないで処理する。
split-multitracksオプションでこのSfMも分割できるらしいけど、現状エラーで動作しない。 - mve
Multi View Environment。MVSのこと。dense point cloudを生成する。ここからは分割処理する。 - odm_filterpoints
不明。 - odm_meshing
点群をいくつかまとめてポリゴンを生成する。ここは分割処理できない(ODM 0.9.10時点)。 - mvs_texturing
ポリゴンにテクスチャを貼る。ここは分割処理できない(ODM 0.9.10時点)。 - odm_georeferencing
ローカル座標系で処理してきた点群/ポリゴン/テクスチャにワールド座標系に変換する。具体的にはGPS座標をブレンドする。 - odm_dem
Digital Elevation Model生成。具体的にはDTM(Digital Terrain Model)とDSM(Digital Surface Model)を生成する。 - odm_orthophoto
オルソ画像を生成する。 - odm_report
最近追加された処理。レポートを生成するらしい。
ClusterODM/NodeODMの処理を見ている限り、2回split-mergeしている。
おそらく「3D textured meshes はsplit-mergeできない」制限が原因。
[単体Node] dataset
==> splitで複数EC2インスタンスで非同期分散処理。
[複数Node] opensfm(split-multitracksオンの場合) -> mve
==> mergeで一旦データを併合。
[単体Node] meshing -> texturing
==> splitで複数EC2インスタンスで非同期分散処理。
[複数Node] georeferencing -> dem -> orthophoto
==> mergeで複数データを併合。
[単体Node] report
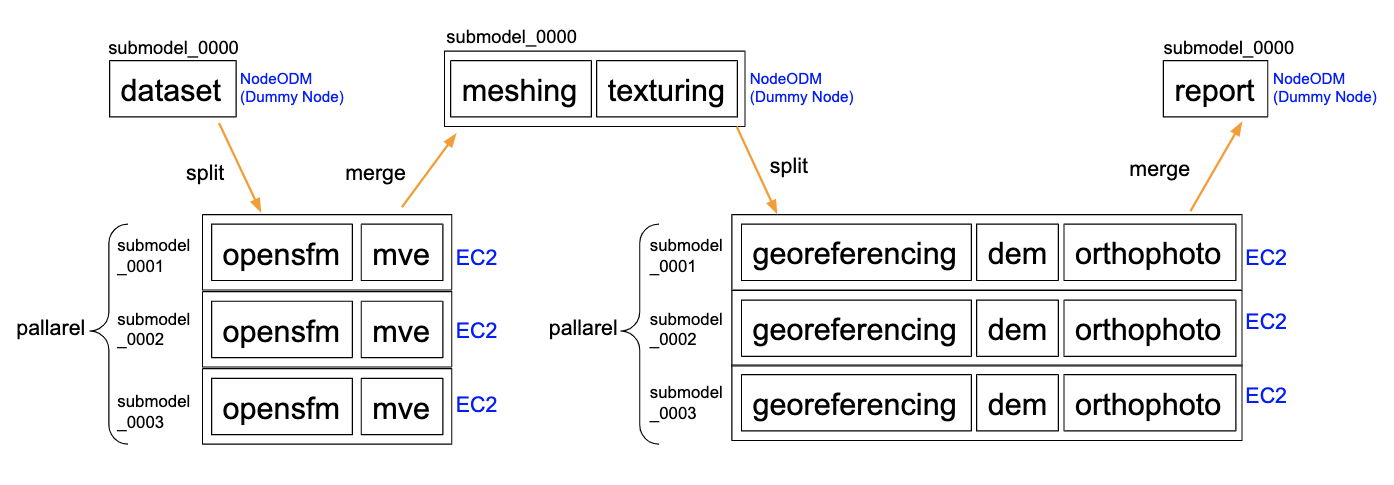
※split-multitracks オプションが現在動作しないので、opensfmは分散処理されません。
ClusterODMのキューイングの仕組み
- WebODMから2つ同時にタスクを実行してみる。
- DummyのNodeODMのDockerコンテナで複数をdocker runしている。
/code/run.shがOpenDroneMapの実行コマンドで、2つ同時にrunしていた。 - アクセスが集中する場合、同時に数十個くらいのタスク要求があるので、同時に数十個キューイング状態になる。
- しかし内部では
docker runしているのでパラレルに処理している。順次処理ではなかった。 - kubernetesクラスタの仮想ノードもしくはECS+FargateなどででCPU/メモリAutoScalingすれば解決する。
結局これらはVerticalAutoScalingできないので、別の対処方法を考えました。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
59362edd3b90 opendronemap/clusterodm "/usr/local/bin/node…" 2 minutes ago Up 2 minutes 0.0.0.0:4000->4000/tcp, 0.0.0.0:8080->8080/tcp, 3000/tcp, 0.0.0.0:10000->10000/tcp clusterodm
b034779a31cd opendronemap/nodeodm "/usr/bin/nodejs /va…" 4 minutes ago Up 2 minutes 0.0.0.0:3000->3000/tcp nodeodm-1
# docker logs b034779a31cd
info: Authentication using NoTokenRequired
info: Listening on 0.0.0.0:6367 UDP for progress updates
info: Initialized 1 tasks
info: Checking for orphaned directories to be removed...
info: Server has started on port 3000
info: Closing server
info: Exiting...
info: Authentication using NoTokenRequired
info: Listening on 0.0.0.0:6367 UDP for progress updates
info: Initialized 1 tasks
info: Checking for orphaned directories to be removed...
info: Server has started on port 3000
info: About to run: /code/run.sh --sm-cluster http://ec2-44-234-186-36.us-west-2.compute.amazonaws.com:4000 --split-overlap 0 --split 30 --dsm --max-concurrency 30 --project-path /var/www/data aa0aa0fd-84e4-4b31-bc98-cc229ddd204c
info: About to run: /code/run.sh --sm-cluster http://ec2-44-234-186-36.us-west-2.compute.amazonaws.com:4000 --split-overlap 0 --split 30 --dsm --max-concurrency 30 --project-path /var/www/data 0077b885-aaa3-4b52-9c93-93170c2a030d
# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
59362edd3b90 clusterodm 0.01% 42.39MiB / 15.46GiB 0.27% 167MB / 167MB 9.78MB / 77.8kB 35
b034779a31cd nodeodm-1 2.00% 493MiB / 15.46GiB 3.11% 246MB / 174MB 19.7MB / 242MB 29
# docker stats --no-stream --no-trunc
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
59362edd3b9093090ad6e5c96c668c4467150ff307f148a8041c9a5d0f4c58ee clusterodm 0.24% 78.18MiB / 15.46GiB 0.49% 247MB / 168MB 9.78MB / 119kB 108
b034779a31cd988ced1444655a4530e693efbf08387a59d992bc0fd2a8f20ea2 nodeodm-1 0.04% 548.2MiB / 15.46GiB 3.46% 249MB / 255MB 20.7MB / 531MB 33
ClusterODMで2つのタスクをキューングしている様子。
順次処理しているわけではなく、同時並行処理をカウントしているだけでした。
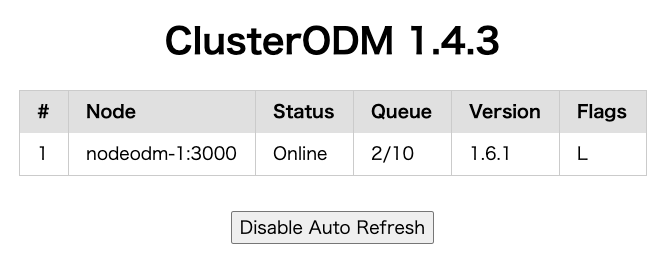
NodeODMで2つ同時にパラレルに実行している様子。
イメージ図。
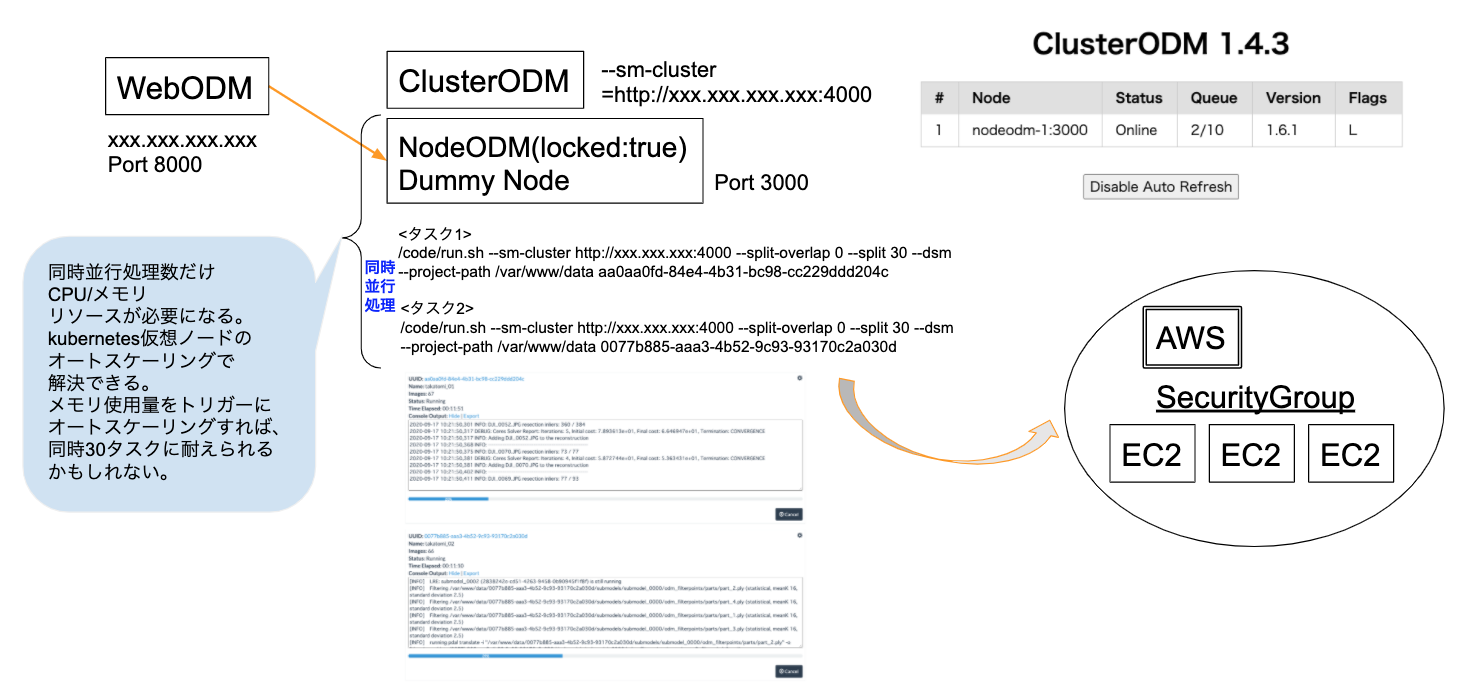
ClusterODMの実際の動作
オプション関連の調査
- 関係がある可能性が高いもののみ調査します。
- オプションの文字列から意味を読み取りにくいのと、実際の動作が想像しにくいので、確認の意味です。
ClusterODMのオプション
-c, --cloud-provider
-c, --cloud-provider Cloud provider to use (default: local)
デフォルトの local でいいみたい。
--downloads-from-s3 <URL>
--downloads-from-s3 <URL>
Manually set the S3 URL prefix where to redirect /task/<uuid>/download requests.
(default: do not use S3, forward download requests to nodes, unless the autoscaler is setup, in which case the autoscaler's S3 configuration is used)
AWS/S3を利用するので、将来カスタマイズするのに必要になる可能性がある。
--no-splitmerge
--no-splitmerge
By default the program will set itself as being a cluster node for all split/merge tasks. Setting this option disables it. (default: false)
cluster node = ClusterODM実行のコンテナ?有効にするとエラーで止まる。なんのために存在するか謎。
ソースコード上の実際の処理部分
// When --no-splitmerge is set, do not allow seed.zip
if (!config.splitmerge){
if (fileNames.indexOf("seed.zip") !== -1) throw new Error("Cannot use this node as a split-merge cluster.");
}
seed.zip ??? 初めて見る言葉。
seed.zipはClusterODMにはなく、本家OpenDroneMapに存在する。
https://github.com/OpenDroneMap/ODM/blob/0145f4c60ed2a7b151d5ff2fae90b5be0be1ecab/opendm/remote.py#L296
def create_seed_payload(self, paths, touch_files=[]):
paths = filter(os.path.exists, map(lambda p: self.path(p), paths))
outfile = self.path("seed.zip")
with zipfile.ZipFile(outfile, "w", compression=zipfile.ZIP_DEFLATED, allowZip64=True) as zf:
for p in paths:
if os.path.isdir(p):
for root, _, filenames in os.walk(p):
for filename in filenames:
filename = os.path.join(root, filename)
filename = os.path.normpath(filename)
zf.write(filename, os.path.relpath(filename, self.project_path))
else:
zf.write(p, os.path.relpath(p, self.project_path))
for tf in touch_files:
zf.writestr(tf, "")
return outfile
さらにソースコードを追っていくと。
https://github.com/OpenDroneMap/ODM/blob/0145f4c60ed2a7b151d5ff2fae90b5be0be1ecab/opendm/remote.py#L330
def execute_remote_task(self, done, seed_files = [], seed_touch_files = [], outputs = [], ):
"""
Run a task by creating a seed file with all files in seed_files, optionally
creating empty files (for flag checks) specified in seed_touch_files
and returning the results specified in outputs. Yeah it's pretty cool!
"""
seed_file = self.create_seed_payload(seed_files, touch_files=seed_touch_files)
seed.zip=seed_filesを作るということ = remote_taskを作るということ。
要するに、remote taskを作ることを禁止する = ローカルでのみsplit-mergeすること、らしい。
意味としては --no-splitmerge ではなくて --only-local-splitmerge にすべきだと思う。紛らわしい。混乱する。
今回は、remote=EC2でsplit-mergeしたものを処理してほしいので、このオプションを指定してはいけない。
--public-address <http(s)://host:port>
--public-address <http(s)://host:port>
Should be set to a public URL that nodes can use to reach ClusterODM. (default: match the "host" header from client's HTTP request)
通常運用環境ではURLが固定になるので指定した方がいいかもしれない。
--token <token>
--token <token>
Sets a token that needs to be passed for every request. This can be used to limit access to the node only to token holders. (default: none)
動作検証済。WebODM Lightningもtokenを使用しているので、通常運用環境でも使用する方がいいかもしれない。
--asr <file>
--asr <file>
Path to configuration for enabling the autoscaler. This is combined with the provider's default configuration (default: none)
このオプションを指定するとCluster AutoScaler構成になる。
NodeODMのオプション
-d, --deamonize
Set process to run as a deamon
コンテナ運用ではフォアフラウンドにする必要があるので、通常運用環境では必要ないかもしれない。おそらくネイティブインストール用のオプション。
-q, --parallel_queue_processing <number>
Number of simultaneous processing tasks (default: 2)
ClusterODMに登録するNodeODMはDummyノードなので、キューイングする数を指定する。
--token <token>
Sets a token that needs to be passed for every request.
This can be used to limit access to the node only to token holders. (default: none)
使用予定。ClusterODMにもtoken設定があるので、その関係性を要調査。
--webhook <url>
Specify a POST URL endpoint to be invoked when a task completes processing (default: none)
指定すべきかどうか要調査。
EC2のASRではタスクが終了するとEC2側からこのwebhookに終了通知を送って(イベントドリブン)EC2をCleanup(terminate)している。
--max_concurrency <number>
Place a cap on the max-concurrency option to use for each task. (default: no limit)
同時実行数。検証の結果、NodeODM内でOpenDroneMapを同時に複数runしている動作。
OpenDroneMapのオプション
- OpenDroneMap’s official documentation
https://docs.opendronemap.org/ - Splitting Large Datasets
https://docs.opendronemap.org/large.html
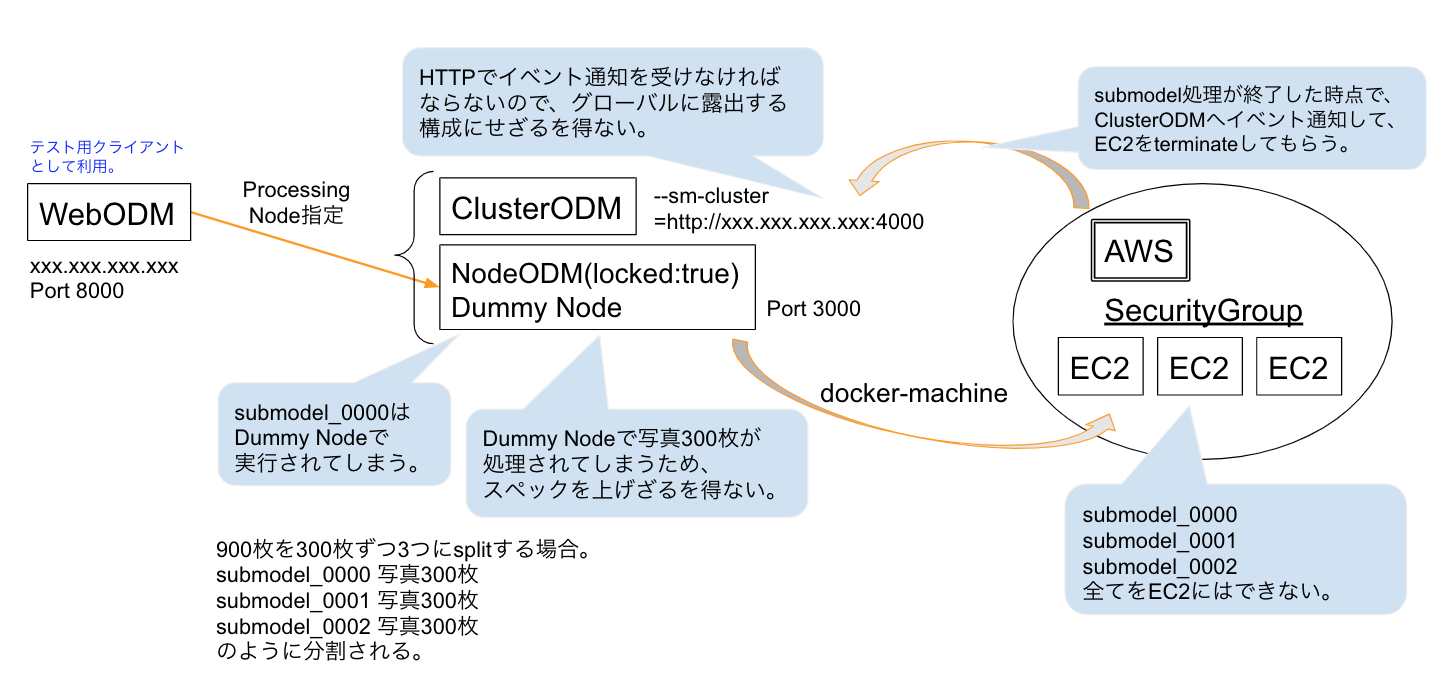
--sm-cluster
- ClusterODMでASR構成している必要がある。今回はAWS/EC2。
asr = autoscaler?説明がないけど多分この略称。 - ClusterODMに登録してあるダミーNodeODMは
locked:trueに設定して、全ての処理をバックエンド(EC2)に任せている必要がある。 - 指定は
http://<cluster-odm-ip>:4000の形式。通常運用環境ではHTTPSの方がいい? - 検証したところ、この指定はwebhookにもなっているようで、submodel終了時にイベントをwebhookしてEC2をterminateしている。
--split --split-overlap
- データセット=写真の分割設定。submodel_0000からはじまってsubmodel_0001と続いていく。
-
--splitはいくつに分割するか?ではなく、何枚の写真をひとまとまりにするか、の設定。
--split 300に設定すると300枚の写真をひとまとめにする。 -
--split-overlapはデフォルトで150m(単位はメートル)。submodel間の重なる距離を指定している。
デフォルトの150mだとかなり重なりが多いので0にしている。
150mオーバーラップすると、900枚を3分割しようとしても300/300/300にはならなくて、1つのsubmodelは300枚よりも多くなる。
オーバーラップを0にするとうまくデータ分割できないのではないか?と思うけど、検証が十分ではない。
-–split-multitracks
- 現時点でマニュアルに載っていない。NodeODMのオプションには存在する。
- OpenDroneMap Communityでは
Split multi-track reconstructions.の意味らしい。
https://community.opendronemap.org/t/split-multitracks/4727 - これを指定すると IOError/OSErrorになる。原因はまだ分からない。
- reconstructions=MVS処理(一番時間かかる処理)であれば是非複数VM分散処理しなければならない。
このオプションの処理部分はOpenDroneMapのソースコードに存在する
parser.add_argument('--split-multitracks',
action=StoreTrue,
nargs=0,
default=False,
help='Split multi-track reconstructions.')
resplit_done_file = octx.path('resplit_done.txt')
if not io.file_exists(resplit_done_file) and bool(args.split_multitracks):
省略
#We need the original tracks file for the visualsfm export, since
#there may still be point matches between the tracks
shutil.copy(s+"/tracks.csv", path+"/opensfm/tracks.csv")
#Create our new reconstruction file with only the relevant track
with open(path+"/opensfm/reconstruction.json", "w") as o:
json.dump([v], o)
#Create image lists
with open(path+"/opensfm/image_list.txt", "w") as o:
o.writelines(map(lambda x: "../images/"+x+'\n', v["shots"].keys()))
with open(path+"/img_list.txt", "w") as o:
o.writelines(map(lambda x: x+'\n', v["shots"].keys()))
省略
# Aligned reconstruction is in reconstruction.aligned.json
# We need to rename it to reconstruction.json
remove_paths = []
for sp in submodel_paths:
sp_octx = OSFMContext(sp)
split-multitracks オプションを有効化すると、opensfm/reconstruction.json もsplit-mergeするようになるみたい。
reconstruction.json はOpenSfMによって作成される「疎な(sparse)点群データ」。
https://www.slideshare.net/takayukimizutani9/open-dronemap
現時点ではエラーで止まるので、OpenSfMの処理はsplit-mergeしなくてもいいと判断(できれば分割したい)。その次の処理MVSが一番時間かかってsplit-mergeしてくれればいいので、今はこのオプションは有効化できなくても構わないと判断。
オプションの名前が分かりにくい。意味で言うと --split-opensfm にすべき。そうすればすぐに意味が分かる。
OpenDroneMapのsplit-mergeとは
- OpenDroneMap’s official documentation
https://docs.opendronemap.org/ - Splitting Large Datasets
https://docs.opendronemap.org/large.html#splitting-large-datasets - Distributed Split-Merge
https://docs.opendronemap.org/large.html#distributed-split-merge - 制限事項(OpenDroneMap 0.9.10時点)
3D textured meshesはsplit-mergeできない。
split-mergeできるのは、point cloudDEMorthophotos。 - 具体的にどの処理をsplit-mergeしているかはマニュアルに記載されていないので、ソースコードを調査する。
split-merge処理のソースコード
- split merge instructions
https://github.com/OpenDroneMap/ODM/wiki/split-merge-instructions
- setup.py
前処理。具体的には以下。
--resize-to--min-num-features--num-cores--matcher-neighbors - run_matching.py
pre-matching処理。写真のEXIFを抽出してGPS座標の位置関係を解析する。 - split.py
matchingの結果からどこでsplit(分割)してsubmodel化できるか判定してデータをいくつかの塊に分ける。 - run_reconstructions.py
ここのreconstructionはOpenSfMのStructure from Motionの意味。 - align.py
なんらかのalign(揃える)処理を行ってから次の処理に渡すらしい。ソースコードに説明なし。 - run_dense.py
dense point cloudを生成する処理。MVS(Multi View Stereo)のこと。
[参考]OpenDroneMap内の用語
- sparse reconstruction => OpenSfM(Structure from Motion) = 疎な点群のこと。
- dense reconstruction => MVS(Multi View Stereo) = 密な点群のこと。
- したがって、
reconstructionだけではどちらの処理か判定できない。
https://github.com/OpenDroneMap/ODM/blob/8489cf06b63f18b6fedeee78bc804dc1f7e6b752/stages/run_opensfm.py#L111