はじめに
Apache Solr を触る機会があったので、そこで調査した/身に着けた基本的な内容を忘れないように記しておく。
そもそも Apache Solr って何?
A: 全文検索エンジンの1つであり、それを実現するウェブサーバーベースのアプリケーション。
全文検索エンジンとは、複数の(大量の)文章を登録し、どこかにキーワード(らしきもの)を含む文章を検索することを主眼としたもの。
全文検索エンジンの活躍どころの例としては、社内で管理している(大量の)ドキュメントファイルの検索、ウェブページのアーカイブ管理と検索、ニュースサイト全体から記事を検索する、などが考えられる。
もちろん、これらのことは要件次第では RDB や KVS を使っても達成できる。 しかし、データ量の増加に従ってパフォーマンスの劣化が顕著になってきたり、あいまい検索(例: 入力「とうきょう」に対して、「東京」が含まれる文字を検索対象にするなどの文字が一致しないが同じ意味を示す単語群の検索など)の実現が非常に難しいため、こういった問題解決を前提に作られた専用の検索エンジンが用いられることが多い。 Apache Solr はその1つである。
全文検索エンジンの有名どころとしては、 ElasticSearch もある。 Apache Solr と ElasticSearch は同じ Apache Lucene (ルシーン) という検索エンジンライブラリを採用しているウェブサーバーアプリケーションである。 しかし、これらのソフトウェアが最終的に実現したいことは全文検索である。
ElasticSearch と Solr とを比較すると、Solr の方が先に作られている。
また、元々分散サーバー前提で構築された ElasticSearch と、後からそれを SolrCloud で実装した Solr というあたりにインフラ的な違いがある。
Solr 環境の構築と使い方の説明
検証環境
Virtual Box 上の Ubuntu Linux 20.04 LTS で Docker を稼働。
Apache Solr のモード
公式にチュートリアルがあるが、一番最初から SolrCloud という用語が出てきて混乱した。
Solr サーバーは単一のウェブサーバーからなる「スタンドアロンモード」と複数のウェブサーバーノードからなる「SolrCloudモード」がある。 この記事では全て「スタンドアロンモード」で話を進める。
また、上記チュートリアルはファイルをダウンロードしてきて、そしてサーバーアプリケーションを動かすという形になっているが、今回は環境依存性を作らず、ローカル環境を汚さないために Docker Hub にある Apache Official の公式イメージを利用する。 今回は記事執筆時点の latest (8.9) を使用。
Solr コンテナの起動
詳しい使い方は Docker hub のページよりも Github の README の方が詳しかったので、こちらを参考にイメージを立てる。
# フォアグラウンドで Solr を起動
$ docker run --name solr --rm -p 8983:8983 solr:latest
これで http://localhost:8983 にアクセスして、Solr の管理コンソールが見えれば起動はOK。
ただし、この起動のさせ方ではデータは永続化されないため、コンテナを停止すると (--rm がついていることもあり) 登録したデータは全て消えてしまう。 各種データは全てコンテナの /var/solr 以下に保存されるため、README に記載のある通り、データ保存ディレクトリを UID:GID=8983:8983 とした後、-v "$(pwd)/solrdata:/var/solr のようにしてマウントすることでデータを永続化できる。
Solr のコア(コレクション)
先のやりかたで Solr を立ち上げた場合、そのままではデータの登録や検索などはできない。 というのも、本当にサービスを立ち上げただけであって、データを登録しておくところ(RDBでいうデータベース)が存在しないためである。
Solr ではこの**「データ登録の単位」のことを「コア」または「コレクション」と呼ぶ**。 この呼び分けはモードによって異なり、スタンドアロンモードの場合はコア、SolrCloudモードの場合は「コレクション」と呼ぶ(以後、この記事はスタンドアロンモードでの説明なのでコアで統一する)。
Solr コンテナは起動時に(空の)コアを生成できるスクリプト solr-precreate を用意してくれている。 コア example を生成して Solr コンテナを立ち上げるコマンドは以下の通りである。
# コア example を作成してフォアグラウンドで Solr を起動
$ docker run --name solr --rm -p 8983:8983 solr:latest solr-precreate example
これでコア example が デフォルトの初期設定を利用して 作成される。
データの登録と全データ検索
Solr へのデータの登録は Solr が提供する postコマンド や API エンドポイント向けの HTTPリクエスト によって実行できる。 今回は、元々 Solr が内部で提供しているサンプルデータをpostコマンドを使って example コアへと登録してみる。
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,7.99,true,George R.R. Martin,"A Song of Ice and Fire",1,fantasy
0553579908,book,A Clash of Kings,7.99,true,George R.R. Martin,"A Song of Ice and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,6.99,false,Glen Cook,The Chronicles of The Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of Prydain,2,fantasy
$ docker exec -it solr post -c example /opt/solr/example/exampledocs/books.csv
/usr/local/openjdk-11/bin/java -classpath /opt/solr/dist/solr-core-8.9.0.jar -Dauto=yes -Dc=example -Ddata=files org.apache.solr.util.SimplePostTool /opt/solr/example/exampledocs/books.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/example/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/example/update...
Time spent: 0:00:00.678
今回は post コマンドで csv ファイルを選んだが、XMLファイルなどにもデフォルトで対応している。 post コマンドでは PDFやWordなども登録できるが、これに対応させるには別途設定が必要(なので、この例ではPDFやWordは読み込みできない)。
これで、管理コンソールから "example" コアを選び、デフォルトの状態でクエリを実行することで、登録されたデータを確認できる。
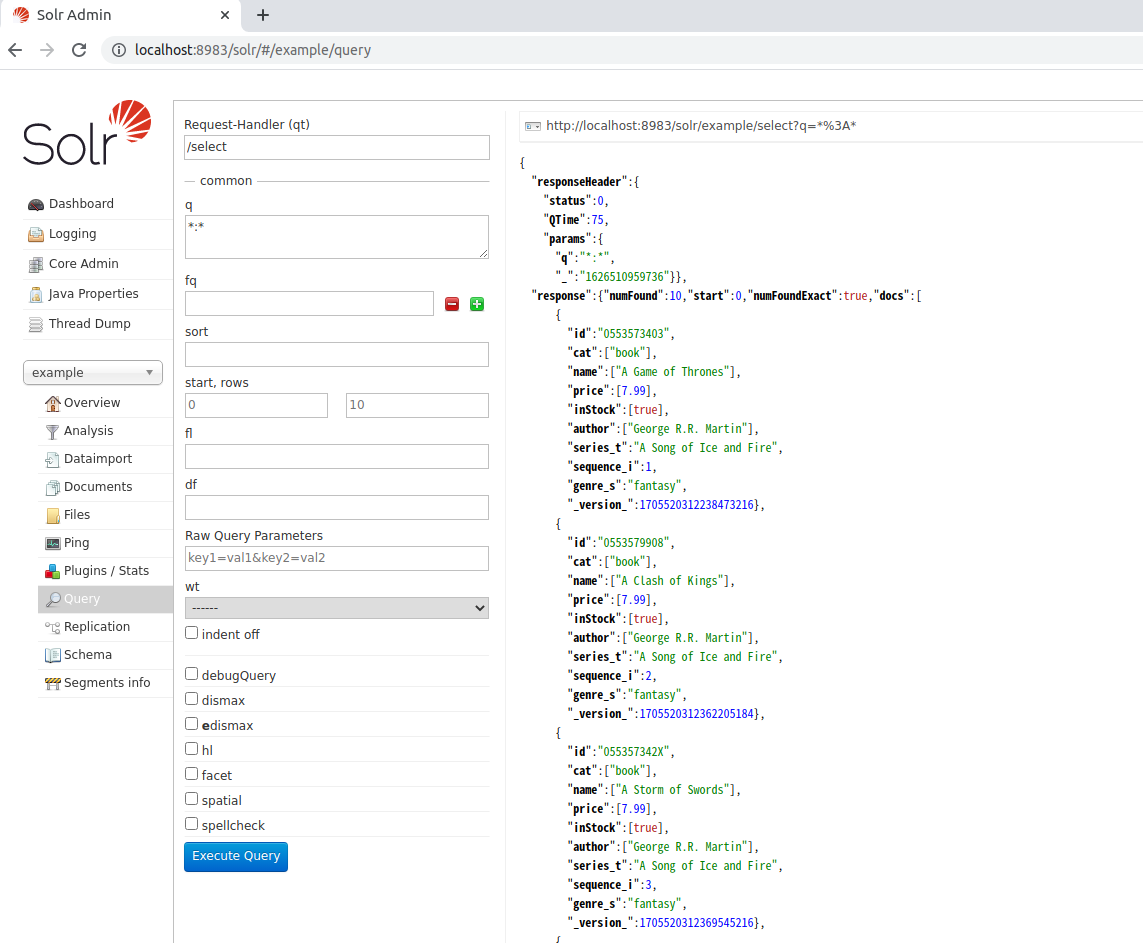
管理コンソールの右上にクエリ取得時に URI が表示されているため、これを curl などで呼び出しても、同様の結果が得られる。 この例の場合は以下の様になる。
$ curl -s "http://localhost:8983/solr/example/select?q=*%3A*" | jq .
{
"responseHeader": {
"status": 0,
"QTime": 0,
"params": {
"q": "*:*"
}
},
"response": {
"numFound": 10,
"start": 0,
"numFoundExact": true,
"docs": [
... (略) ...
]
}
クエリによるデータ検索
先に全データを検索するクエリを投げたが、実際には「検索キーワード」を指定してデータを検索するだろう。 そこで、name に Game が入っているクエリで検索してみる。APIのパラメータに q=name:Game とキーワードを指定してクエリを投げると、name に Game が含まれている結果のみが得られる。
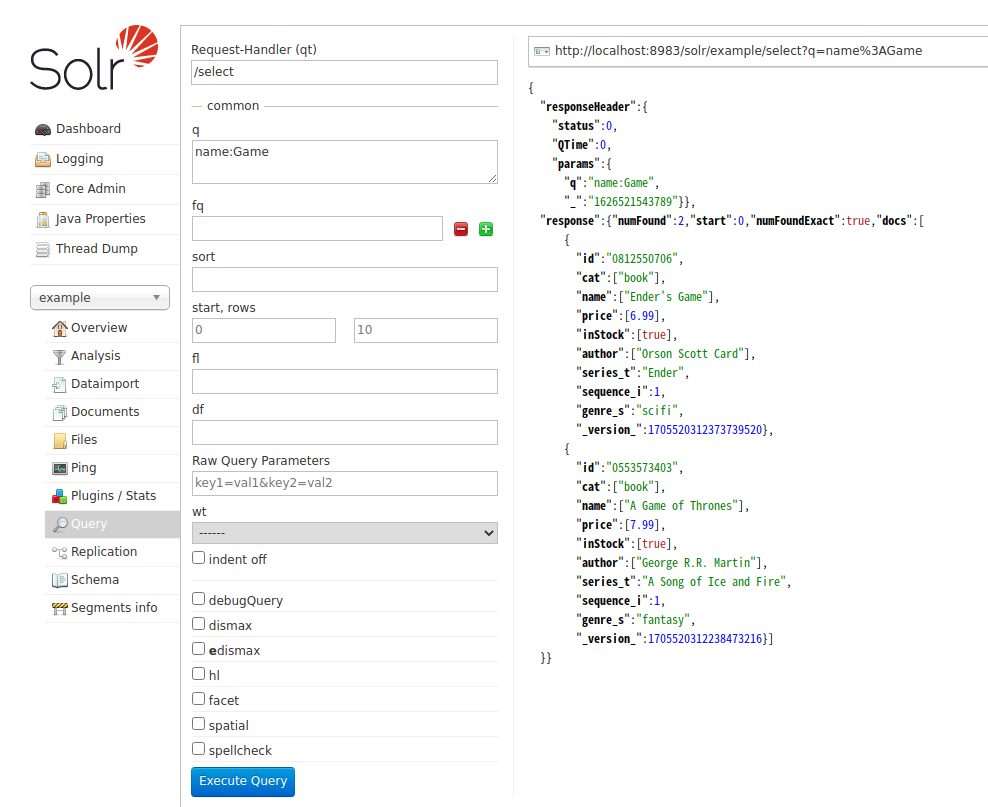
他にも検索クエリの時に指定できるフィールドがあるが、これらはこちらを参照。
これらのパラメータによって、クエリの詳細条件の指定、取得するレスポンスフォーマットの指定などを行うことができる。
フィールド名指定のない q パラメータ
最初にクエリ検索をするとき、私はここで単に "Game" とだけ入力したが検索結果は0件となってしまった。 そのため、クエリ名にはフィールド名指定は必須なのかと考えたのだが、Solr の Getting Started の記事 を見ると curl "http://localhost:8983/solr/techproducts/select?q=foundation" と、フィールド名を指定しないクエリで foundation が含まれる結果を取得できている。
これには仕掛けがあるので、仕組みの説明と共に後述する。
スキーマの定義とフィールド
ある1つのコアの中に格納するデータを表現するために、複数の属性を持つことができる。 先の例で言えば書籍情報の1つのデータに対して、ID(id) や本のカテゴリー(cat), 名前(name) や 価格(price) などの属性を持っている。
コアには、コア内のデータがどのような属性を持つかを定義するスキーマ(schema)がある。 スキーマの定義は managed-schema という Solr が管理するファイル内に記載され、利用者は API 経由 (あるいは、同様の機能を持つ管理コンソール経由) でスキーマを定義する (なお、schema.xml ファイルを使う方法もあるが、ここでは触れない)。
フィールド
スキーマにはどのようなデータがどのような型(Field)で入ってくるかを定義できる。 型の定義も schema 定義ファイルの中に記載されている。 型定義の例は以下の通り。
<!-- string 型の定義 -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true"/>
<!-- text_ja 型の定義 -->
<fieldType name="text_ja" class="solr.TextField" autoGeneratePhraseQueries="false" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" words="lang/stopwords_ja.txt" ignoreCase="true"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
明らかに後者の text_ja の方が複雑な定義になっているが、これは analyzer 部分を併せて定義していることが理由である。 Solr は特定の型のデータを登録するとき、同時に検索用のインデックスも作成する。 このインデックスの作成方法は言語ごと、あるいは分野ごとに適切な方法は異なるが、これを型定義のtokenizer や filter によって拡張可能にしている。
Solr でどのようにインデックス化されるかは、管理コンソールの Analysis 機能を使ってみることができる。 string 型と text_ja 型を比較すると、以下のように異なる結果が得られていることが分かる。
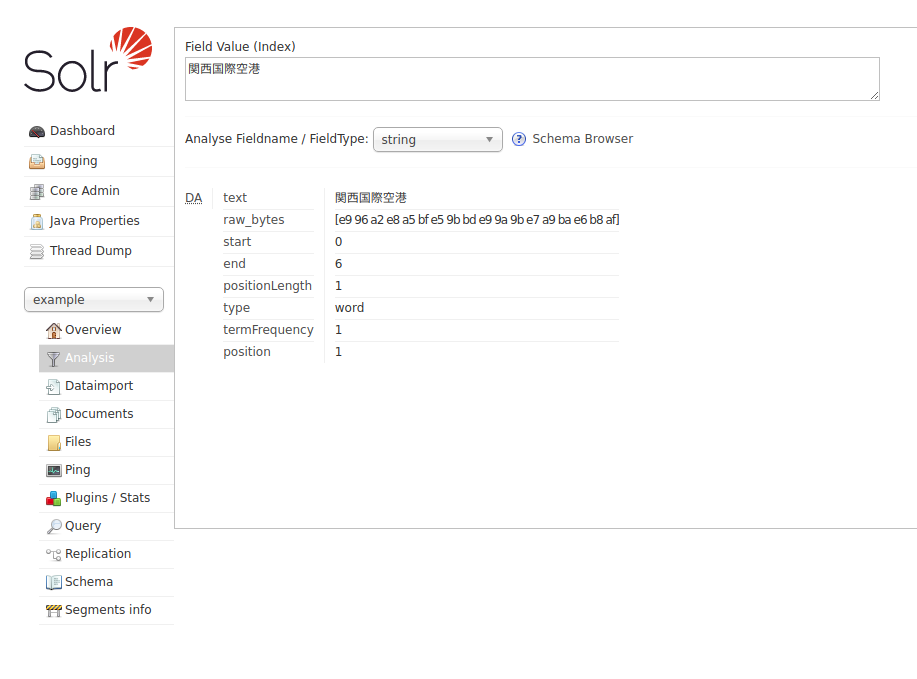
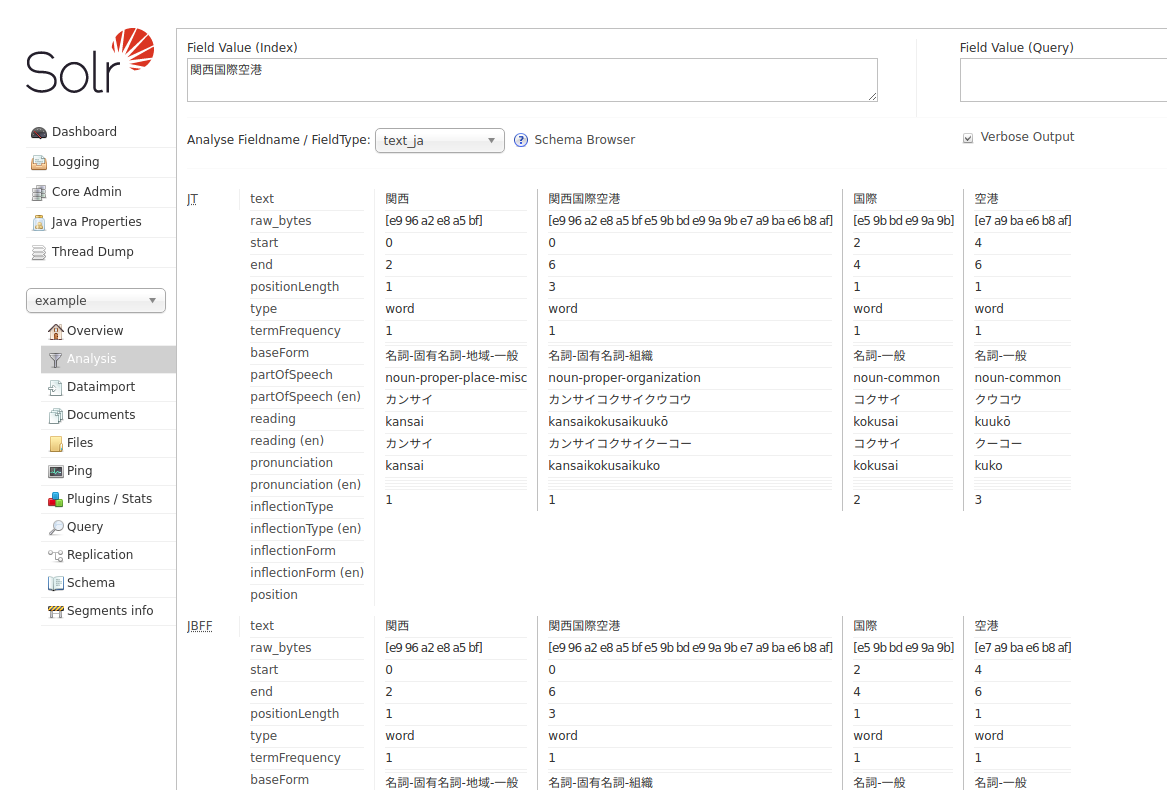
text_ja は後々に大量の Filter が続いているが、このなかで助詞などは取り除かれて検索用にどのようなインデックスが作られるかを確認できる。
この例だと、文字列「関西国際空港」という文字列を string 型と text_ja 型にそれぞれ登録してクエリで検索する場合、「関西」とだけ入力すると text_ja 型の場合のみ検索にヒットするようになる。
Analyzer の処理の流れは以下の記事などを参照。
ダイナミックフィールドとコピーフィールド
フィールドには固定名称のフィールドの他に、入力ソースと名称が一致した場合に自動的に新しいフィールドを定義する「ダイナミックフィールド」と、1つ以上のフィールドの情報をコピーして保持する「コピーフィールド」という概念がある。
ダイナミックフィールドは名称に * を含むフィールドで、データ登録時に一致するデータがある場合、自動的に新しいフィールドをダイナミックフィールドで定義した型で生成する。 例えば、*_sample というダイナミックフィールドが定義されている場合、data_sample というコンテンツが入力された場合、data_sample というフィールドが自動生成されて、ここにデータが登録される。
一方、コピーフィールドはソースフィールドのデータが入力された場合、同じデータを別のフィールドにコピーして登録するという機能である。 これは例えば、
- 1つのデータを異なる方法で分析したい(=異なる型でデータを登録したい)
- 複数のフィールドの横断検索をするために、検索用のデータを1つのフィールドにまとめたい
と言ったユースケースで利用される。 複数のフィールドをソースに持つことができるので、コピー先のフィールドは multiValued 属性を持って複数のデータを持つようにするのが一般的である。
コア生成時のコンフィグとフィールド名なし検索の実現方法
Solr のコアを作成するときには、そのコアの初期コンフィグを設定できる。 初期で利用できるコンフィグセットは Docker であれば /opt/solr/server/solr/configsets 以下に配置されていて、初期だと _default と sample_techproducts_configs の2つがある。
Solr のチュートリアルをちゃんと読むと、このチュートリアル内では sample_techproducts_configs を使ってコアを作成していることが分かる。
これを Docker で実現したい場合、solr-precreate の第2引数にコンフィグセットのパスを指定してやればよい。 つまり、チュートリアルと同様のコンフィグセットを利用したコアを生成しつつ Solr コンテナを立ち上げる場合、以下のコマンドを利用する。
$ docker run --name solr --rm -p 8983:8983 solr:latest solr-precreate example /opt/solr/server/solr/configsets/sample_techproducts_configs
この設定を使っているのであれば、フィールド名指定なしで q=Game とだけしてもちゃんとデータが取得できている。
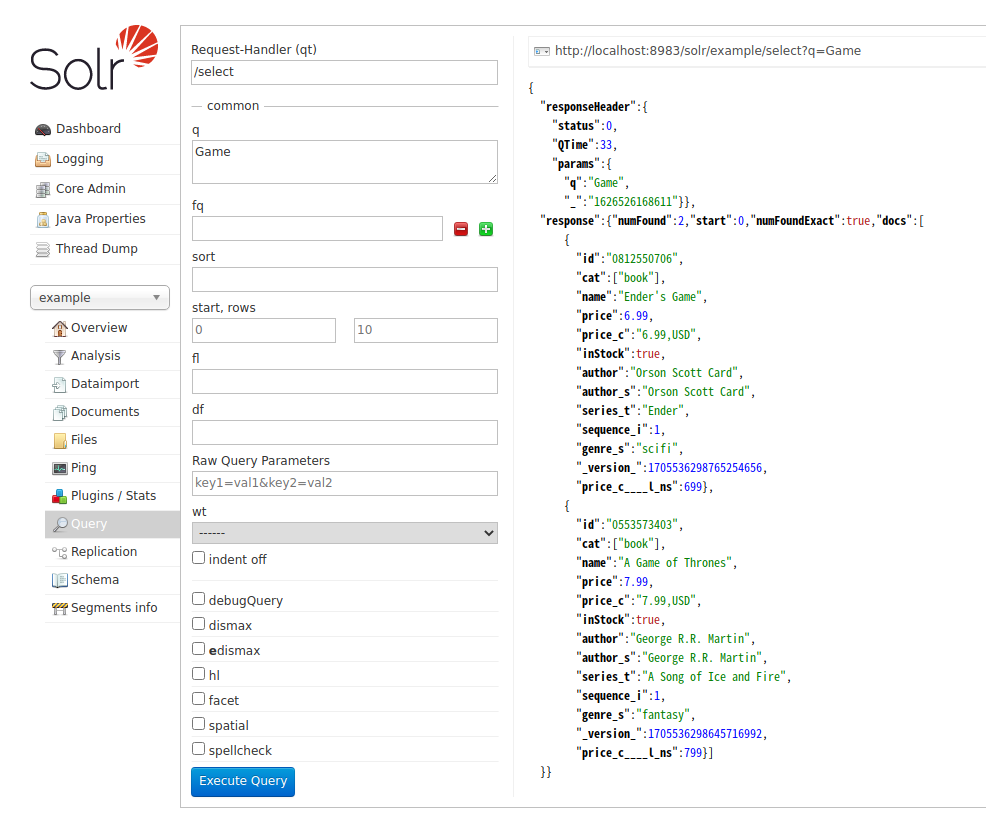
なぜこの設定だとOKかというと、以下の様な仕組みになっているためである。
-
- コアの設定
solrconfig.xml内で/selectへのリクエストハンドラに以下のような記載がある。 この記載によって/selectを発行する場合にdf=textが暗黙的に入力された状態になる
- コアの設定
<initParams path="/update/**,/query,/select,/tvrh,/elevate,/spell,/browse,update">
<lst name="defaults">
<str name="df">text</str>
</lst>
</initParams>
なお、df パラメータは検索するデフォルトフィールドを指定するためのパラメータである。
-
-
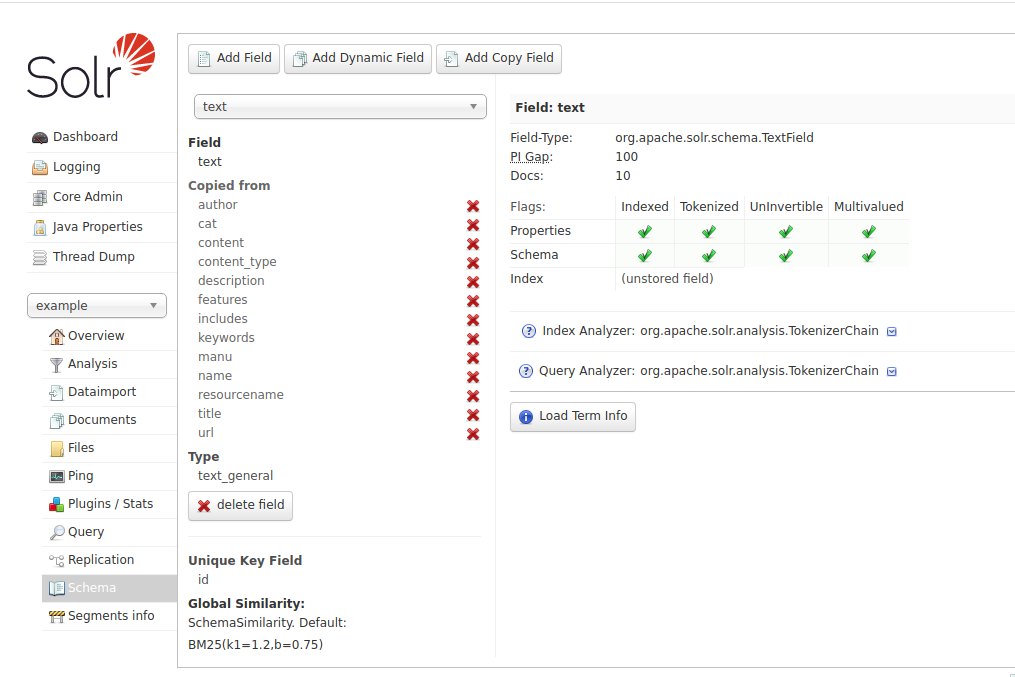
managed-schema内でtextというフィールドはコピーフィールドになっており、入力された様々なデータをコピーしてくるようになっている
-
-
- そのため、フィールド名を入力しない場合はデフォルトで
textフィールドが検索対象とされる。textフィールドは検索のための様々なデータがコピーされ、それら全てがインデックス化されて検索対象となっているフィールドなので、外から見ると複数のフィールドの横断検索ができているように見えている
- そのため、フィールド名を入力しない場合はデフォルトで
まとめ
Solr公式のチュートリアルが SolrCloud から始まっているので Docker の公式イメージで動かそうとしたら初期のコンフィグの違いなどで色々と悩んだため、その疑問に回答できるように色々と調査した結果を書き記した。
これから Solr を使ってみる人の理解の手助けとなれば幸いである。