はじめに
以下の記事で AWS CDK Python を使ったデプロイ方法について調べた。 今回は AWS CDK Python を使って実際に AWS AppSync をデプロイする方法を記載する。
AWS CDK Python のセットアップ方法については、上記記事を参考のこと。
実行環境など
- Ubuntu 20.04 LTS
- aws-cdk: 1.125.0 (build 67b4921)
- pipenv: version 2021.5.29
- デプロイ先: ap-northeast-1 (Tokyo) リージョン
AWS AppSync のデプロイ
この記事では以下の簡単なスキーマの GraphQL API をデプロイする。
type User {
name: String!
age: Int!
}
type Query {
hello: String
getUsers: [ User! ]
}
type Mutation {
addUser(name: String!, age: Int!): User
}
下準備
今回は GraphQL API のデータソースとして DynamoDB を、固定文字列を返すデータソースとして AWS Lambda を利用するため、Python 側でこれらを利用するように各サービス用のライブラリインストールを実施する。
$ pipenv install aws-cdk.aws-appsync aws-cdk.aws-dynamodb aws-cdk.aws-lambda
AWS AppSync サービスの構造
CDK のコードを記載する前に、AppSync の構造を簡単に説明する。 というのも、コードの記載をするときに構造を理解していると理解がしやすいためである。 主要コンテンツは以下の通りであり、GraphQL API の下に Schema, DataSource, Resolvers の3つがある。
-
GraphQL API: トップレベルコンテンツであり、エンドポイントを持つ
- Schema: GraphQL API に紐づくスキーマ定義
- DataSource: AWS AppSyncが連携する (AppSync外の) サービスの紐づけの定義。 例えば、どのような DynamoDB Table を利用するか、など
- Resolvers: Schema と DataSource を結びつけるルール定義。 Schema の入力を DataSource で定義されている各サービスで利用できる形に変換してやる必要があるため、この変換・対応を実現する部分
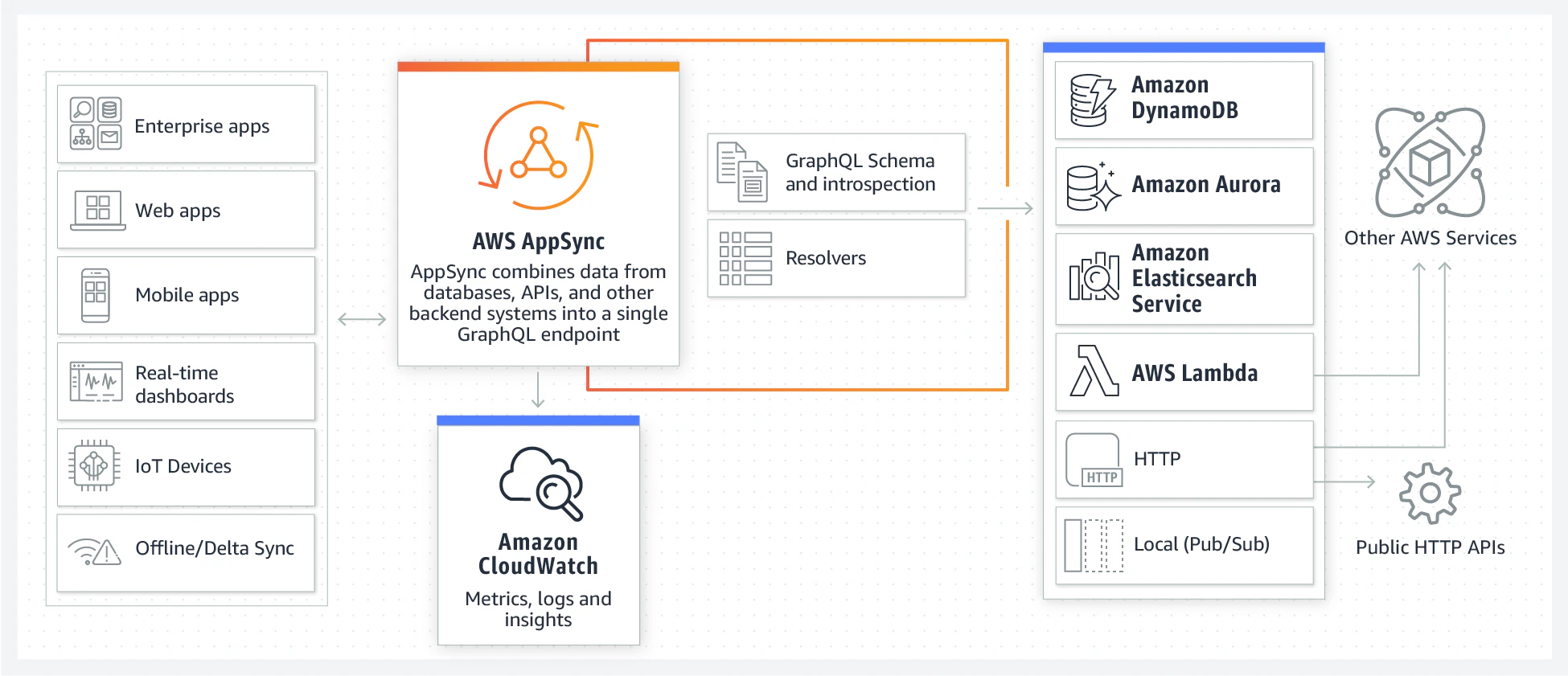
上記の図は AWS公式 からの引用であるが、この図からも分かるとおり DataSource は AppSync とは独立して存在できる。 あくまで、AppSync はこれらのデータソースを取得・操作するための外付けサービスとして存在する。
AppSync Stack の実装
cdk init app で初期化した後、以下のコンテンツを編集・追加した。 (*) がついているものが新規追加したものである。
.
├── cdk_appsync
│ └── cdk_appsync_stack.py
├── lambda (*)
│ └── fixed_string.py (*)
├── resolvers (*)
│ └── addUser.vtl (*)
├── schema.graphql (*)
schema.graphql
今回作成する GraphQL API のスキーマ定義を記載する。
これは先に記載したスキーマファイルと同じなので省略。
lambda/fixed_string.py
固定文字列を返す Lambda 関数であり、AppSync のデータソースとして用いる。
def handler(event, context):
return 'This is a fixed string!'
resolvers/addUser.vtl
AppSync のリゾルバーは Apache Velocity Template Language (VTL) を用いて記載する。 後に示すが、CDK 内に用意されているヘルパを使って Resolver を記載することもできるが、ここでは VTL を使った例を示すためにも準備した。
内容は以下の通り。
{
"version" : "2017-02-28",
"operation" : "PutItem",
"key" : {
"name": $util.dynamodb.toDynamoDBJson($ctx.args.name)
},
"attributeValues" : {
"age": $util.dynamodb.toDynamoDBJson($ctx.args.age)
}
}
これは DynamoDB とのマッピングテンプレートの実装で、putItem を実装した例になる。 その他にも DynamoDB の異なるオペレーション (GetItem や ListItem など) にも対応している。 どのように書くかはこちらを参照のこと。
cdk_appsync/cdk_appsync_stack.py
ここが本体。 以下のページなどを参考にして記載。
# !/usr/bin/python
# -*- coding: utf-8 -*-
from aws_cdk import (
core as cdk,
aws_lambda as cdk_lambda,
aws_appsync as cdk_appsync,
aws_dynamodb as cdk_dynamodb
)
from aws_cdk.aws_appsync import (
AuthorizationConfig, AuthorizationMode, AuthorizationType,
MappingTemplate
)
class CdkAppSyncStack(cdk.Stack):
def __init__(self, scope: cdk.Construct,
construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# GraphQL API と利用するスキーマの定義
graph_api = cdk_appsync.GraphqlApi(
self, 'HelloAppSyncFromCDK',
name='HelloAppSyncFromCDK',
authorization_config=AuthorizationConfig(
default_authorization=AuthorizationMode(
authorization_type=AuthorizationType.API_KEY
)
),
schema=cdk_appsync.Schema.from_asset('schema.graphql'),
xray_enabled=False
)
# DynamoDB DataSource を追加
data_table = cdk_dynamodb.Table(
self, "DemoTable",
partition_key=cdk_dynamodb.Attribute(
name="name",
type=cdk_dynamodb.AttributeType.STRING
)
)
data_source = graph_api.add_dynamo_db_data_source(
'demoDataSource', data_table)
# getUsers に全件取得の Resolver を付与 (プログラムベース)
data_source.create_resolver(
type_name='Query',
field_name='getUsers',
request_mapping_template=MappingTemplate.dynamo_db_scan_table(),
response_mapping_template=MappingTemplate.dynamo_db_result_list()
)
# addUser に vtl テンプレートの Resolver を付与 (VTLベース)
data_source.create_resolver(
type_name='Mutation',
field_name='addUser',
request_mapping_template=MappingTemplate.from_file(
'resolvers/addUser.vtl'
),
response_mapping_template=MappingTemplate.dynamo_db_result_item()
)
# hello に固定文字列を返す Lambda 関数の Resolver を付与
fixed_str = cdk_lambda.Function(
self, 'FixedStringLambda',
runtime=cdk_lambda.Runtime.PYTHON_3_8,
code=cdk_lambda.Code.asset('lambda'),
handler='fixed_string.handler',
environment={},
)
graph_api.add_lambda_data_source(
'FixedStringFn', fixed_str
).create_resolver(
type_name='Query', field_name='hello'
)
コードで特徴的と読めたのが、「データソースの (AppSync) 外部リソース定義 ( data_table や fixed_str など)」と「外部リソースとの紐づけ (add_xxxxxxx_data_source ) 」と「Resolver との対応の定義 (create_resolver)」がしっかりと別々になっていることである。 これは、AppSync の構造と位置づけを理解しているとすんなりと頭に入ってくると思う。
ここまで実装すれば、pipenv run cdk deploy でデプロイできる。
デプロイ後の動作検証
curl で動作検証を行ってみる。 今回は API Key を用いたセキュリティ対応を行っているため、エンドポイントの URL と API Key を AppScyn Console の設定から取得して用いる。
# 固定文字列を取得するクエリ: hello を発行
$ curl -s -X POST -H "Context-Type: application/json" /
-H "X-API-Key: ************************************" \
-d '{"query": "{ hello }"}' \
https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql | jq .
{
"data": {
"hello": "This is a fixed string!"
}
}
# ユーザーを追加する mutation
$ curl -s -X POST -H "Context-Type: application/json" /
-H "X-API-Key: ************************************" \
-d '{"query": "mutation { addUser(name: \"TestUser1\", age: 20) { name age } }"}' \
https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql | jq .
{
"data": {
"addUser": {
"name": "TestUser1",
"age": 20
}
}
}
# 全ユーザー取得するクエリ
$ curl -s -X POST -H "Context-Type: application/json" /
-H "X-API-Key: ************************************" \
-d '{"query": "{ getUsers { name age } }"}' \
https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql | jq .
{
"data": {
"getUsers": [
{
"name": "TestUser1",
"age": 20
}
]
}
}
# --------
# 再度ユーザーを追加
$ curl -s -X POST -H "Context-Type: application/json" /
-H "X-API-Key: ************************************" \
-d '{"query": "mutation { addUser(name: \"TestUser2\", age: 30) { name age } }"}' \
https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql | jq .
{
"data": {
"addUser": {
"name": "TestUser2",
"age": 30
}
}
}
# 全ユーザー取得するクエリ
$ curl -s -X POST -H "Context-Type: application/json" /
-H "X-API-Key: ************************************" \
-d '{"query": "{ getUsers { name age } }"}' \
https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql | jq .
{
"data": {
"getUsers": [
{
"name": "TestUser1",
"age": 20
},
{
"name": "TestUser2",
"age": 30
}
]
}
}
また、DynamoDB テーブルにデータが保存されていることも確認できる。

まとめ
ここでは簡単な AppSync API を AWS CDK Python を用いて定義し、デプロイした。 また、エンドポイントを利用した操作を確かめた。 基本的なことは AWS Management Console ベースであれば、よく使われるテンプレートの自動生成や、スキーマ定義から自動的にデータソース・リゾルバーを生成してくれる機能などがあるので、コンソールベースで簡単に手動でリソースを作成しつつ、必要な部分を切り出して AWS CDK に落とし込むとスムーズに作業が進められるように感じた。