こちらはフロムスクラッチ Advent Calendar 2017の22日目の記事です。
はじめに
とくにネタが思いつかず、どうすればいいんだと思いながらおもむろにテレビを付けたとき・・・
弾ける笑顔で報道陣と話す松居一代さんの姿がありました。
あまり知らなかったのですが、どうやらこの方は今年1年、youtuberとしてなにかと世間を騒がせていた模様。
その弾ける笑顔を見たとき「ちょっと会いたくはないが何を考えているのか知りたい。」そう思うようになったのでございます・・・・
ということで今回の内容は松居一代の代替物をつくり、彼女の結婚観や人生観を聞いてみることにします。
実施する流れは以下のとおりです。ブログや実際に発したコメントから自然言語処理して、彼女にとっての結婚や人生に近い単語を引っ張り出だしてみようという寸法です。(クリスマスも近いのに何やってんだ私は・・・・)
- 松居一代さんのブログやyoutube、記者会見のコメントをスクレイピングする。
- 取得した文章をわかち書きにする
- 単語をベクトル変換する
- 「結婚」、「人生」に近い単語を取得する
松居一代さんのブログやyoutube、記者会見のコメントをスクレイピングする。
まずは元となるデータを取得します。材料はブログと実際に発しているコメントです。コメントについては奇特にも自身のブログに全文書き起こしとかしている人がいたので、その方のブログからそれぞれゲットします。以下の例はアメブロの内容を強引に取得しています。
スクレイピングには BeautifulSoup を使用しました。
使い方などは他の投稿などを参考にしていただければと思います。
参考: PythonとBeautiful Soupでスクレイピング
import urllib.request
from bs4 import BeautifulSoup
blog_list = []
# 松居一代の作成したblog数
MATSUI_BLOG_COUNT=587
# 松居一代のblogのURL Format
MATSUI_BLOG_URL='https://ameblo.jp/matsui-kazuyo/page-{}.html'
for i in range(1, MATSUI_BLOG_COUNT):
url = MATSUI_BLOG_URL.format(i)
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html, "lxml")
# divの要素を取得
div_list = soup.find_all("div")
for div in div_list:
try:
string_ = div.get("class").pop(0)
if string_ in "skin-entryBody":
blog_list.extend(div.contents)
break
except:
pass
f = open('matsui_blog.txt', 'w')
for blog in blog_list:
f.write(str(blog)+'\n')
f.close()
取得した文章をわかち書きにする
次に取得したブログやコメント情報を自然言語処理可能な状態にするため わかち書きにします。形態素解析のエンジンにはmecabを使います。
使い方などは他の投稿などを参考にしていただければと思います。
参考: mecabで分かち書きコマンド
mecab -Owakati matsui_comment.txt -o matsui_data.txt
単語をベクトル変換する
次にわかち書きした文章をインプットにして単語をそれぞれベクトル変換します。ベクトル変換にはgensimによるword2vecを利用しました。使い方などは他の投稿などを参考にしていただければと思います。
参考: Word2Vecを用いた類義語の抽出が上手く行ったので、分析をまとめてみた
from gensim.models import word2vec
import sys
sentences = word2vec.LineSentence('matsui_data.txt')
model = word2vec.Word2Vec(sentences,
sg=1,
size=200,
min_count=5,
window=10,
hs=1,
negative=0)
model.save('matsui_data.model')
「結婚」、「人生」に近い単語を取得する
作成したモデルを用いて「結婚」、「人生」の類義語を出力します。
from gensim.models import word2vec
import sys
import pandas as pd
model = word2vec.Word2Vec.load('matsui_data.model')
results = model.wv.most_similar(positive=[u'人生'],negative=[], topn=10)
pd.DataFrame(results,columns=("ワード","関連度"))
まずは・・・・「結婚」!
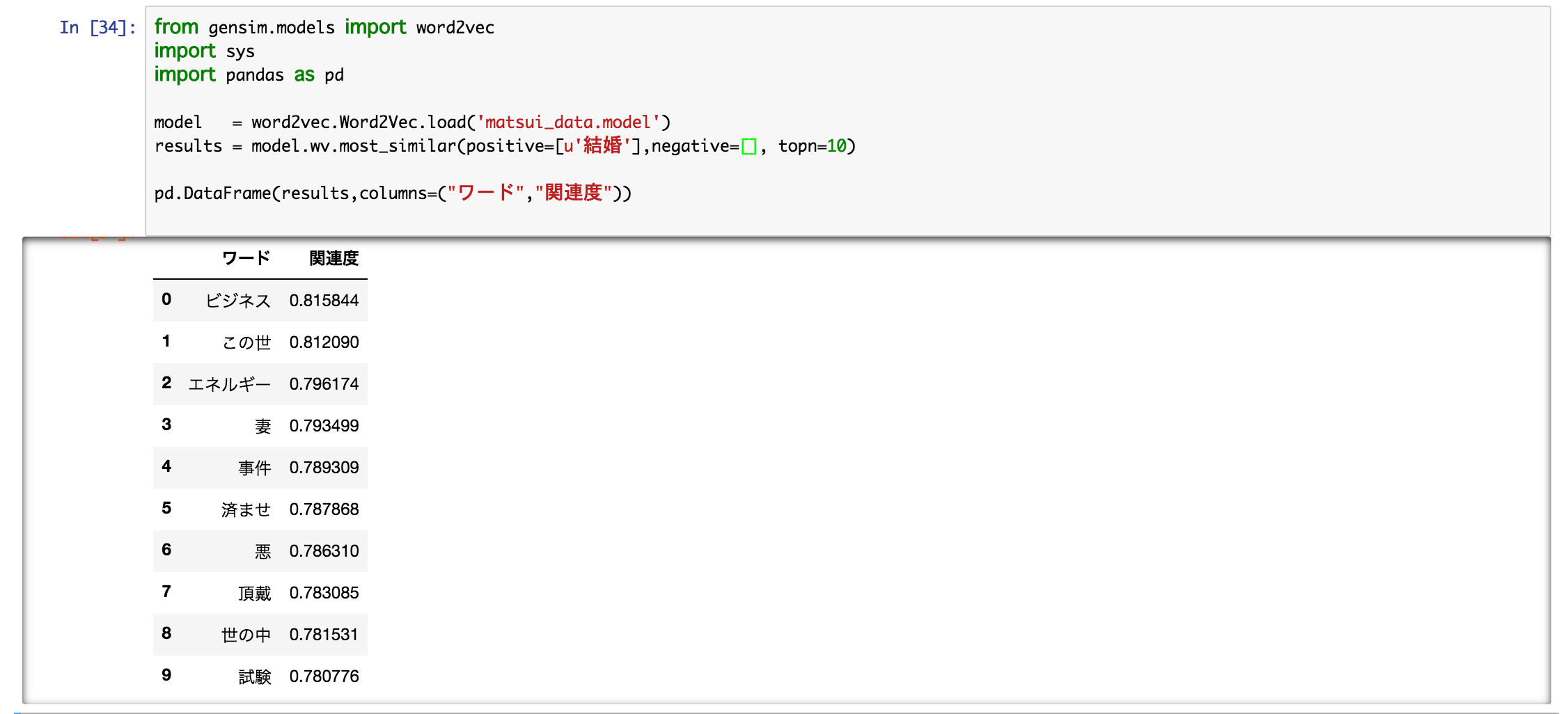
ビジネス・・・・
悪・・・・
事件・・・・・
ざわ・・・・・ざわ・・・・・・・・
はい、とてもグルービーでございます・・・・
続きまして・・・「人生」!
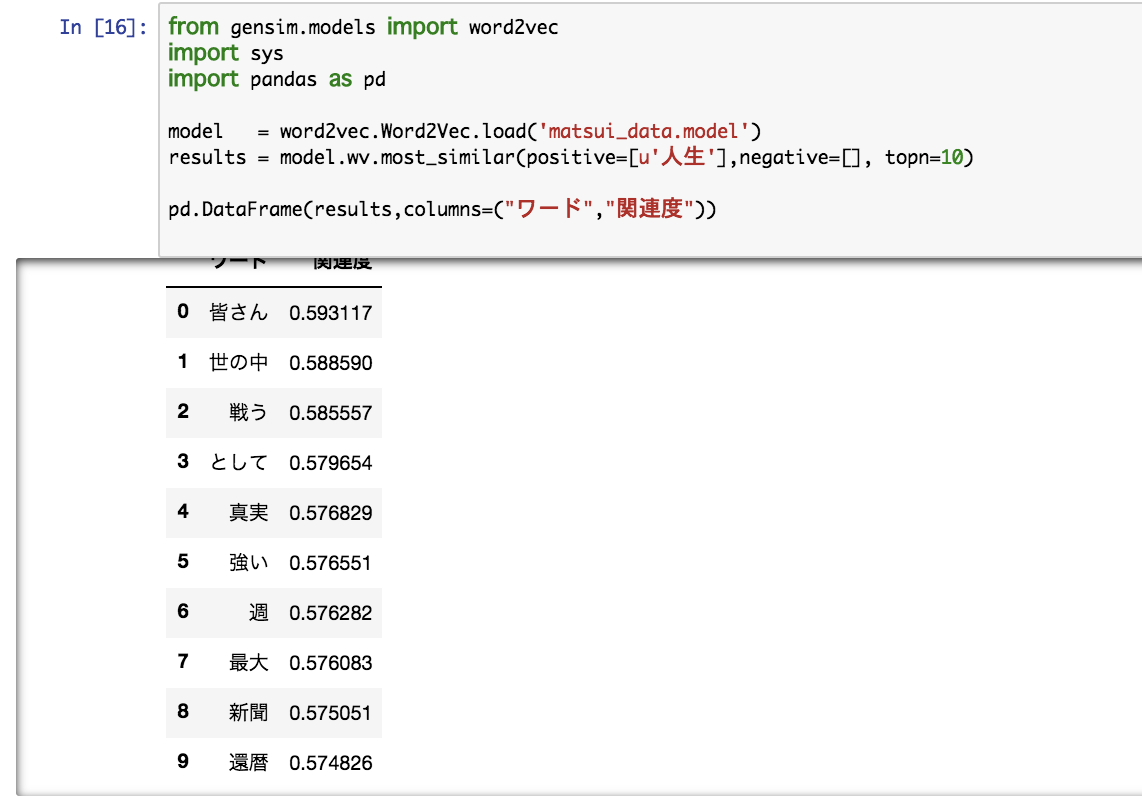
ざわ・・・・
はぁはぁ・・・・まだまだいきましょう。
単語をベクトルに変えるということは演算が可能なのです。ということで「結婚」から「夫」を引いてみたいと思います!
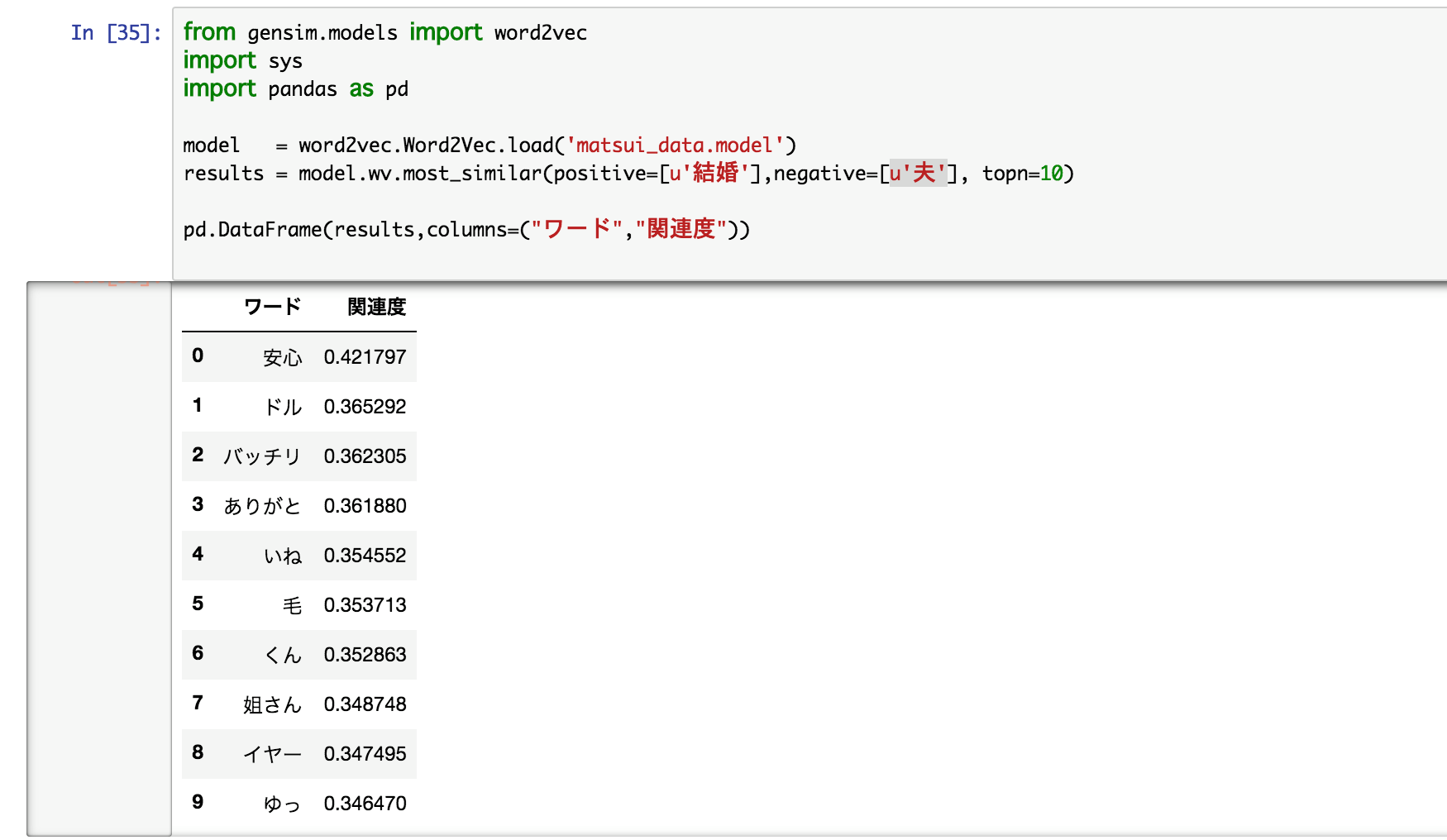
安心
ざわ・・・ざわ・・・・・
ソリッドの聞いた素晴らしい回答です。「イヤー」と「ありがと」も個人的にはツボです。
最後に
そこまで大きなデータをインプットさせてないので大した結果は得られないかと思いましたが、思った以上にくせのある回答になって驚きでございました。
さてとメリクリまでのこり3日・・・・
終盤の大事な場面でカジュアルになんて投稿をぶつけてしまったんだと少々の反省を込めつつ・・・
後続の3名に委ねたいと思います。
あとは頼んだ!じゃあの!