最終目的
プログラミングを全くやったことがないという状態から,機械学習を行えるようになるまで,順に勉強する.
第三回目は,下記参照
機械学習のチューニングの流れ
学習モデルの性能を上げるために,チューニングを行う.
- 流れ :
- 学習方法の選択
- ライブラリのインポート
- 特徴量の作成と選定
- GridSearch
- 交差検証
- CVとLB
学習方法の選択
やってみないとわからないので,下記などの学習法から選んで使ってみる.
今回は特徴量の種類があまり多くないので,単純な学習法の方がうまくいくかもしれない.
下記のサンプルでは,ランダムフォレストを使用している.
学習法の例
- 深層学習(DNN)
- サポートベクター回帰(SVR)
- k近傍法回帰(k-NN回帰)
- 混合ガウスモデル回帰分析(GMR)
- ランダムフォレスト
- XGBoost回帰
- 回帰木
- 最小二乗線形回帰
ライブラリのインポート
下記のインポートでは,参考に回帰分析に使用可能な機械学習のライブラリを読み込んでいるが,
実際には,このうち使用する機械学習だけ読み込めば良い.
また,RMSE計算用の関数とランダムシード設定用関数を記述する.
ランダムシードを設定しておくことで,学習時の初期乱数が毎回固定され,パラメーターを変更した時などに検証しやすい.
※ 指定しないと毎回結果が変わる学習方法もある.
import pandas as pd
import numpy as np
import glob #ファイル読み込み用
import os
import random
import matplotlib.pyplot as plt #画像表示のライブラリ
import seaborn as sns
import tensorflow as tf
#回帰分析に使用できそうな関数を片っ端から読み込む.実際に使う際は,この中から必要なものを読み込む.
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet, SGDRegressor
from sklearn.linear_model import PassiveAggressiveRegressor, ARDRegression, RidgeCV
from sklearn.linear_model import TheilSenRegressor, RANSACRegressor, HuberRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR, LinearSVR
from sklearn.neighbors import KNeighborsRegressor
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor, ExtraTreesRegressor, HistGradientBoostingRegressor
from sklearn.ensemble import BaggingRegressor, GradientBoostingRegressor, VotingRegressor, StackingRegressor
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.cross_decomposition import PLSRegression
from tensorflow.keras.models import Sequential #モデル定義用
from tensorflow.keras.optimizers import Adam, Nadam,SGD #最適化アルゴリズム
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization #Kerasのレイヤーのインポート
from tensorflow.keras import backend as K #RMSEを定義するのに使用
from sklearn.model_selection import GroupKFold, GridSearchCV #交差検証用
#RMSEの計算用関数を定義
def root_mean_squared_error(y_true, y_pred):
return K.sqrt(K.mean(K.square(y_pred - y_true)))
#ランダムシード設定関数
def set_seed(seed=42):
tf.random.set_seed(seed)
np.random.seed(seed)
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
特徴量の作成と選定
訓練データごとにTimeを測っているため,ファイル名をカラムに追加してCSVファイルを読み込む.
テストデータは,ドライブサイクルと温度毎にnameをカラムに追加する.
df = pd.DataFrame()
for path in glob.glob(str("./data/train/*.csv")):
_df = pd.read_csv(path)
df = pd.concat([df, _df])
df['name'] = df["Chamber_Temp_degC"].astype(str) + '_' + df["Drive Cycle"]
df = df.reset_index(drop=True)
test_df = pd.read_csv("./data/test.csv")
tmp = 0
test_df['name'] = test_df["Chamber_Temp_degC"].astype(str) + '_' + test_df["Drive Cycle"]
print(test_df["name"].unique())
# 欠損値を0埋め
df = df.fillna(0)
test_df = test_df.fillna(0)
df
相関を見る.
sns.heatmap(
df.corr(),
linewidths=0.1,
vmax=1.0,
square=True,
cmap=plt.cm.RdBu,
linecolor='white',
annot=True
)
相関が高いのは,AhとWhだが,テストデータには含まれないため,これらは特徴量として使用できない.
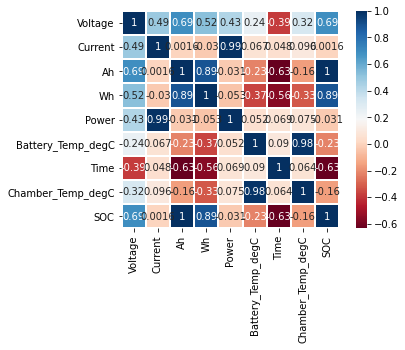
もう一度カラムの説明を見ると,Ahは測定された電流積算値とある.そこで,Currentの累積和が使える可能性を考える.

ついでに,ほかのいくつかのカラムの累積和も求める.
※ファイルごとにTimeが計測されているため,累積和はファイルごとに求める必要がある.
※ テストデータも同様に,Timeが0になるごとにnameを付けて,name毎に累積和を求める必要がある.
※Timeの間隔が一定ではないので,単純な累積和だと本当はダメかもしれない.Timeの間隔を考慮するべきか.
columns = ['Battery_Temp_degC', 'Chamber_Temp_degC', 'Current', 'Power', 'Time', 'Voltage'] #累積和を求めるカラムを決める
cumsum_df = pd.DataFrame({
'name': df['name'].values,
'SOC': df['SOC'].values
})
#累積和を求める
cumsum_df = pd.concat([
cumsum_df,
df.groupby('name')[columns].cumsum().add_prefix('cumsum_')
], axis=1)
#累積和の相関関係を確認
sns.heatmap(
cumsum_df.corr(),
linewidths=0.1,
vmax=1.0,
square=True,
cmap=plt.cm.RdBu,
linecolor='white',
annot=True
)
相関関係を見るとCurrentとPowerの累積和について,相関値が高い.

# 特徴量作成
#use_colum = ['Current', 'Power', 'Time', 'Voltage']
use_colum = ['Current', 'Power'] #累積和を使用する特徴を決める.
#use_colum = ['Current']
X = df.groupby('name')[use_colum].cumsum()
test = test_df.groupby('name')[use_colum].cumsum()
y = df['SOC']
all_df = pd.concat([X, test])
X = (X - all_df.mean()) / all_df.std()
test = (test - all_df.mean()) / all_df.std()
GridSearch
GridSearchCVを使ってベストパラメーターを選定する.
※ 非常に時間がかかる上にメモリの消費も激しいので注意
※ ここでは,計算時間短縮のため,確認するパラメーターを雑に設定しているので,注意
※ search_paramsは学習法によって異なるので,その点にも注意
m = RandomForestRegressor() #学習法を変更する場合はここを変更する
# m = LinearRegression() #最小二乗線形回帰
# m = Pipeline([('poly', PolynomialFeatures(degree=3)),('linear', LinearRegression())]) #多項式
# m = KNeighborsRegressor(n_neighbors=3) #k近傍回帰
set_seed(42)
#検証するパラメータをリストとして,登録.学習法によってパラメーターは違う
search_params = {
'n_estimators' : [1, 2, 3],
'max_features' : [1, 2],
'random_state' : [42],
'n_jobs' : [1],
'min_samples_split' : [11, 12, 13],
'max_depth' : [11, 12, 13]
}
gsr = GridSearchCV(
m,
search_params,
scoring = 'neg_mean_squared_error',
cv = 2,
n_jobs = -1,
verbose=3
)
gsr.fit(X, y)
#ベストパラメータを表示
gsr.best_estimator_
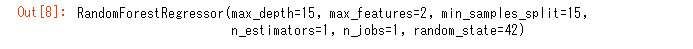
交差検証
交差検証は,標本データを分割し、その一部を解析し、残る部分でその解析のテストを行い、解析自身の妥当性の検証・確認に当てる手法である.
未知のデータに対する予測精度を検証するため,疑似的に未知データを作り検証することで,過学習が起きていないかの指標ともなる.
上記で,求めたベストパラメーターを使用して交差検証を行い.そのデータの平均を求め,SOCの予測値とする.
#GridSearchCV自体に交差検証の機能がついているが,分かりやすくするために交差検証を別途行っている.
models = []
#交差検証で計算した値を格納する変数を定義
train_check = pd.DataFrame(np.zeros(len(X)))
kf = GroupKFold(n_splits=3) # cross validationはGroupKFoldで行う.n_splitsは交差検証の回数を設定する.
for fold, (tr_idx, va_idx) in enumerate(kf.split(X, y, df['name'])):
x_train, y_train = X.iloc[tr_idx], y[tr_idx]
x_valid, y_valid = X.iloc[va_idx], y[va_idx]
set_seed(42)
m = gsr.best_estimator_ #ベストパラメータの関数.best_estimatorを計算してない場合は,ここに学習方法の関数を設定する.
m.fit(x_train, y_train) #学習させる
p = m.predict(x_valid)
p = pd.DataFrame(data=p)
p.loc[p[0] < 0] = 0
p.loc[p[0] > 100] = 100
train_check.iloc[va_idx] = p
models.append(m)
score = root_mean_squared_error(y, train_check[0]) #検証したスコアを表示
print(score)
交差検証の結果はRMSEが0.1536ほど
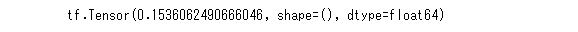
交差検証の結果を平均化し結果を出力.
#交差検証で計算した値の平均を最終的な値とする
SOC_data = pd.DataFrame([model.predict(test) for model in models]).mean(axis=0)
SOC_data
結果をCSVファイルに書き込み.
#CSVファイルに書き込み
csv_data = pd.DataFrame(data=SOC_data, columns=["SOC"])
csv_data.loc[csv_data['SOC'] < 0, 'SOC'] = 0 #0~100の値に変更
csv_data.loc[csv_data['SOC'] > 100, 'SOC'] = 100
csv_data.reset_index(inplace=True)
csv_data = csv_data.rename(columns={'index': 'ID'})
csv_data.to_csv("./data/submission.csv", index=False)
CVとLB
CVとは,今回の交差検証で算出したスコアのことである.
LBとは,投稿先での暫定スコアである.
LBでは,最終的なスコアを算出するテストデータの一部で暫定スコアを計算するため,本来の値と異なる.
そこため,CVの値を信頼する場合が多い.