Amazon SageMaker
AWSを用いて機械学習を行ってみたかったので、
Amazon SageMakerというサービスを使ってみることにした。
SageMakerはre:invent 2017で発表されリリースされたばかりのフルマネージドなエンド・ツー・エンドの機械学習サービス。
機械学習のモデル開発プロセスを管理するためのサービスを提供し、モデル開発プロセスに伴う複雑で面倒な部分を肩代わりする。
機械学習をこれから始めようと考えているエンジニアの敷居を下げるだけでなく、データサイエンティストやAIエンジニア、機械学習のエキスパートが素早くモデルを構築し、スケーラブルなトレーニングと素早いリリース(デプロイ)を可能にする。
つまりAmazon SageMakerは、手軽に機械学習を行えるサービスという事である。
初心者の自分にとっては、非常にありがたい。
SageMakerの概要
SageMakerは「オーサリング」「トレーニング」「ホスティング」の3つのモジュールで構成されている。
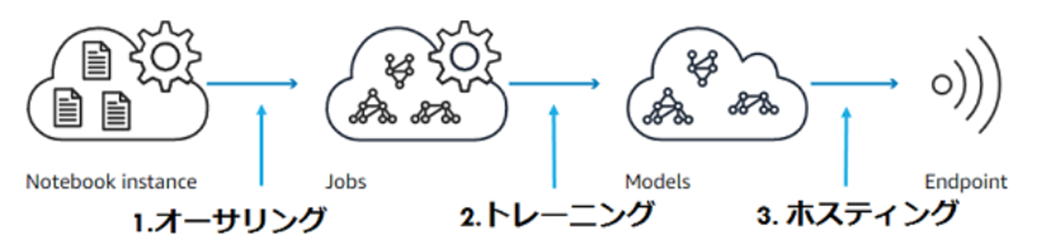
<オーサリング>
いわゆるデータセットの前処理の工程のこと。機械学習の9割はデータセットの前処理だ、と言われているほど重要な工程である。
Amazon SageMakerでは、Jupyter NotebookをCPUベースやGPUベースなど、クラウド上で利用状況に合わせて簡単にセットアップ&利用が可能となっている。
<トレーニング>
SageMakerが提供しているBuilt-inのアルゴリズムやDeep Learningフレームワーク、Dockerによる独自学習環境を使ってモデルをトレーニングすることができる。
生成したモデルはS3に保存される。
このモデルはそのままSageMakerにホスティングを出来るほか、AWS以外に持ち出してIoTデバイスなどにデプロイすることもできる。
<モデルホスティング>
構築したモデルをリアルタイムで使えるように、HTTPSエンドポイントが提供される。
SageMaker チュートリアル
とは言っても、なんとなく機械学習がやりたい!ってだけで機械学習が出来る程、現実は甘くはない。
なぜなら、自力で機械学習を行おうとするものなら
① 機械学習で使用するデータセット
② モデルの構築に必要な解析法やその周辺の知識
③ それ以前のデータの前処理などで必要となるPythonやライブラリの知識
以上が必要となるからである。
.
.
.
.
.
いや、困った。
機械学習やってみたいという軽い気持ちで挑戦してみようと意気込んだものの実際に何を解析したいとかは特にないし、なんなら今までプログラミングをサボってきたからPythonに関する知識もほぼ皆無である。
しかし、SageMakerにはチュートリアルが存在しており、そこにデータセット、
使用するライブラリやコードの書く手順などが事細かに説明されている。
簡単に言うと、そのチュートリアルに沿ってSageMakerを使えば知識0でも機械学習の一連の流れを体験する事ができ、その解析法の実用性についても学ぶ事ができるという事である。
XGboostを用いた銀行定期預金の見込み顧客の予測
それでは、今回実際に行うチュートリアルの概要について説明していく。
今回使用したチュートリアル(GitHubに掲載されている)☟
Targeting Direct Marketing with Amazon SageMaker XGBoost
このチュートリアルは、全て英語で書かれているが、日本語でこのチュートリアルを行っている人がいたので、そのページも参考にしている。☟
Amazon SageMakerを使って銀行定期預金の見込み顧客を予測【SageMaker +XGBoost 機械学習初心者チュートリアル】- codExa
今回使用するデータセットは、ポルトガルのとある銀行が実際に行った、電話による定期貯金のダイレクトマーケティングの結果である。各ユーザーの年齢や職業、さらには学歴などのデータがあり、ダイレクトマーケティングを行った結果、定期預金へお申し込みをした人は(ラベル=1)、お申し込みをしなかった人は(ラベル=0)が付与されている。
機械学習エンジニアなら、一度は耳にする初心者向けの非常に有名なデータセットらしい?(もちろん筆者は初めて知った。)
このデータセットに対して、XGboostという学習法を用いて解析を行い、顧客へのダイレクトマーケティングが成功するか否かを予測する。そして、その予測結果を実データと比較し、どれほどの精度で予測できたのかを検証するというのが本チュートリアルの大まかな流れである。
XGboostの概要
今回、モデルの構築を行う際に使用する解析法「XGboost」の概要を説明する。
XGBoostは、勾配ブーストツリーアルゴリズムのよく知られた効率的なオープンソースの実装である。勾配ブースティングは教師あり学習アルゴリズムで、より単純で弱いモデルのセットから推定のアンサンブルを組み合わせることで、ターゲット変数の正確な予測を試行します。XGBoost は、各種データタイプ、信頼関係、ディストリビューション、およびニーズに合わせて切り替え、調整できる大量のハイパーパラメータを堅牢に処理できるため、kaggle等の機械学習コンペティションにおいて非常に優れた結果を出している。
つまり、XGboostは最強の教師あり学習の手法である!って事で解釈しておいた。
最近では、LightGBMという学習法に王座を奪われつつあるらしいけど...w
教師あり学習って何?他の学習法も合わせて紹介
先程、XGboostは教師あり学習と言ったが、「教師あり学習」についてもよく分からないので、少し調べてみた。
機械学習には、「教師あり学習」「教師なし学習」「強化学習」3つの手法が存在している。
<教師あり学習>
教師あり学習は、正解のラベルや数値が分かっているデータをもとに構築された学習モデルを使って、コンピューターが学習していく手法。機械学習の学習手法の中でも最もシンプルであり、分類や予測において、人間が予め立てておいた予測に近い結果が得られやすいことが特徴。
使用例としては、取引における市場予測や、自社の商品をよく購入してくれるクライアントの推定が挙げられる。
<教師なし学習>
教師なし学習は、正解ラベルの付いていない入カデータから、共通する特徴を持つグループを見つけたり、データを特徴づける情報を抽出したりする学習手法。
代表的な使用例として、クラスタリングがある。クラスタリングはデータの中から似た特徴があるデータを自動で見つけて、何種類かのグループに分けるものである。
<強化学習>
強化学習は、教師あり学習や教師なし学習と異なり、結果が出るまでに時間がかかったり、多数の繰り返しが必要になったりするタスクに関して、実際に行動しながら最適な判断を見つけ出す手法。自動車の自動運転、ロボットの制御やAlphaGo(アルファ碁)に代表されるようなゲームに利用されている。
<参考文献>「機械学習」の3つの学習法(教師あり学習・教師なし学習・強化学習)とは? - sweeepマガジン
SageMakerチュートリアルの実際の流れ
前置きが長くなってしまったが、ここから実際どのようして解析を進めていくのかを説明する。
なお、SageMakerを使用する上で必要となるAWSのアカウントについては、AWS Educate Starter アカウントを採用した。
AWSのサービスを使用する際、基本的には料金が発生する。
ただ、AWS Educate Starterアカウントはデフォルトで数十ドル程度のクレジットが与えられている為、暫くの間実質無料でAWSのサービスを使えるのである。貧乏金欠大学生である筆者にとっては、非常に嬉しい特典である。
ただ、色々と規制が多く使えないサービスがあったりするので、そこは注意が必要である。詳しくは、後述する。
また、今回記述する解析の流れについてだが、筆者が失敗して行き詰った部分についても詳細に記述を行い、その解決手順についても説明する。
今後、自分と同じようにAWS Educate StarterアカウントでSageMakerに触れる人達の為に、この記事をトラブルシューティングとして活かしてもらいたいという思いもあったりする。
まず、始めに解析の手順をざっと説明すると下記のようになる。
⓪ AWS マネジメントコンソールの画面を開く
① Amazon S3 バケットを作成する
② Amazon SageMaker ノートブックインスタンスの作成
③ Jupyterノートブックを作成する
④トレーニングデータをダウンロード、調査、および変換する
⑤ モデルをトレーニングする
⑥ モデルのホスティング
⑦ モデルを検証する
それでは、1つ1つの手順について詳細に説明を行っていく。
非常に長くなってしまったので、軽く目を通してもらえればと思う。
⓪ AWS マネジメントコンソールの画面を開く(ここが意外と重要)
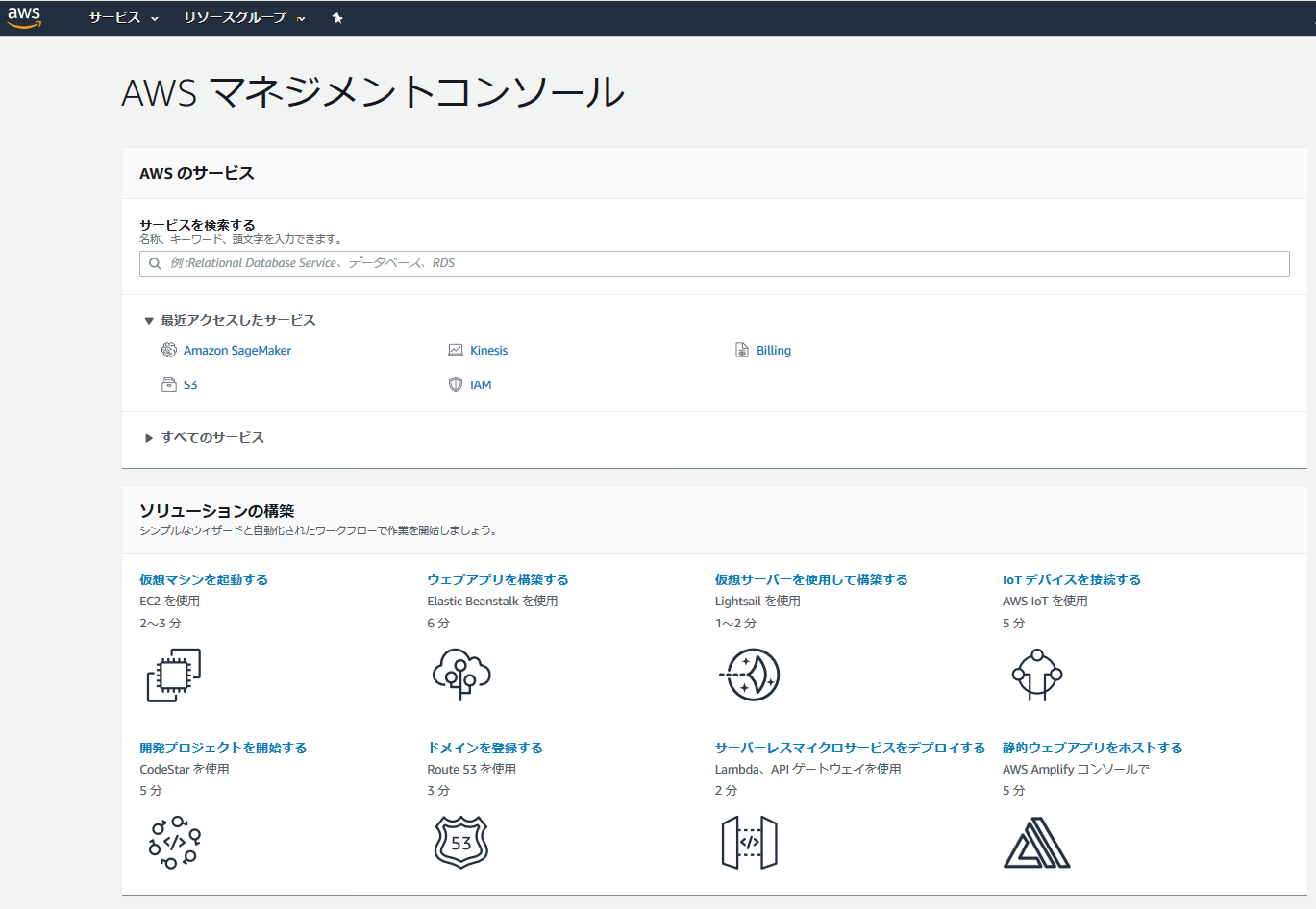
まず、AWS Educateのアカウントへのログインを行い、左上の「AWS Account」をクリックすると下のような画面へと遷移する。
その後は、画面の指示に従ってAWS Consoleを起動すると下のように「AWS マネジメントコンソール」の画面が開く。
「サービスを検索する」で検索して、自分の使いたいサービスを指定する。
今回は、「S3」と「Amazon SageMaker」を使用する。
.
.
.
.
.
初心者が順当に行けば、このような流れになるのだが、上述した通り「AWS Educate Starter アカウント」では、使えるサービスが限られているのだ!!!
AWS Educate Starter アカウントで使用できるサービス一覧
この一覧表を表を見ると、なんとSageMaker instanceが使用できないと書いてあるではないか。
つまり、「AWS Educate Starterアカウント」を作成したからといって「SageMaker」は、使用できないのである。
筆者は、最初それを知らずに進めていたら、「⑤ モデルをトレーニングする」の最後のモデルフィッティングのところで下記のようなエラーが出てしまっていた。
ClientError: An error occurred (AccessDeniedException) when calling the CreateTrainingJob operation: User: arn:aws:sts::780079846795:assumed-role/AmazonSageMaker-ExecutionRole-20191119T213649/SageMaker is not authorized to perform: sagemaker:CreateTrainingJob on resource: arn:aws:sagemaker:us-east-1:780079846795:training-job/xgboost-2019-11-19-13-34-49-653 with an explicit deny
それでは、これを解消するにはどうしたらいいのか?
再度、使用できるサービス一覧を見ると、「Machine Learning and AI」という「Classroom」を使用することで、StarterアカウントでもSageMakerが使用できるようだ。
AWS Educate Classroomsの紹介ページ(全て英語)
上記のページの内容を何となく翻訳してみたら、教育者がClassroomを開設し、独自のAWS Educate仮想教育スペースをセットアップした後に生徒を招待して、使用状況を確認する。的な事が書いてあったので、大学の所属している研究室の教授にClassroomを開設して頂いた。(ちなみに、Classroomの申請から開設まで割と早めに出来る。流石Amazon)
Classroomに招待されたら、AWS Educateのトップ画面左上にある「My Classrooms」を押すと、下図の様な画面に遷移する。
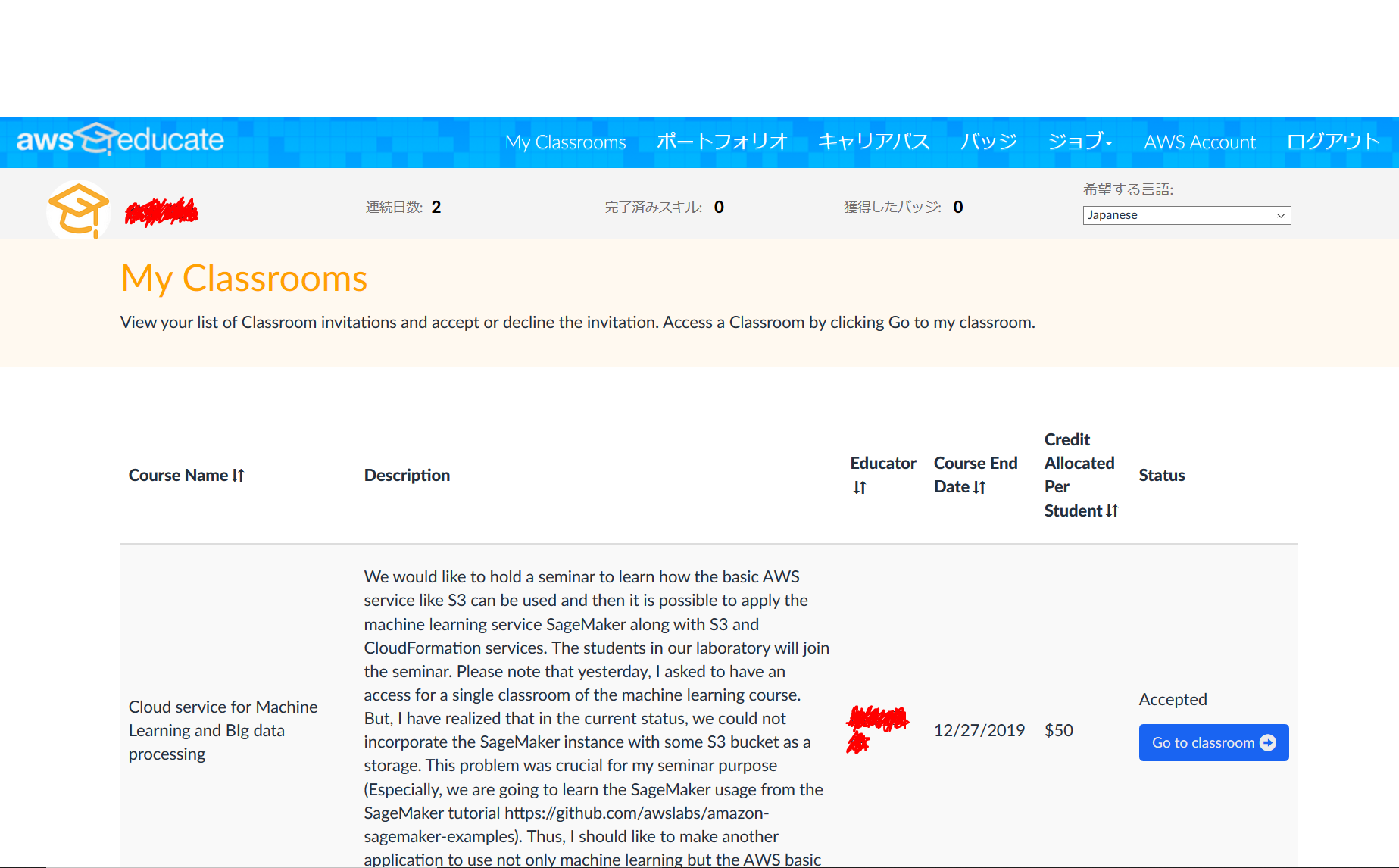
「Go to classroom」を押して、画面の指示に従って進めば、classroomのAWS マネジメントコンソールの画面へと行く事が出来る。
やっとこれで、始められる(泣
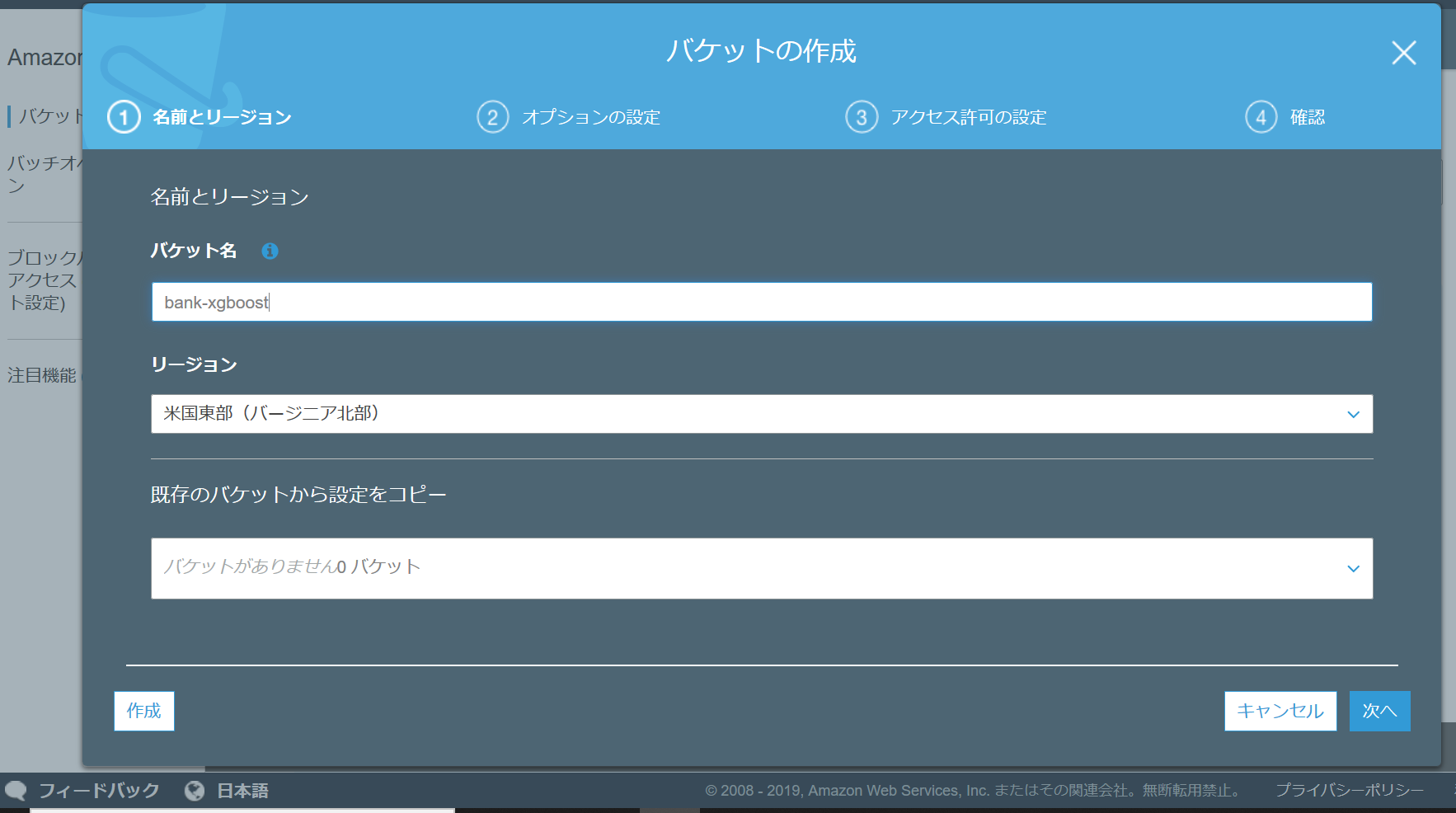
① Amazon S3 バケットを作成する
S3のサービスの画面に遷移すると下記の様になっている。左側にある「バケットを作成する」を押して作成。
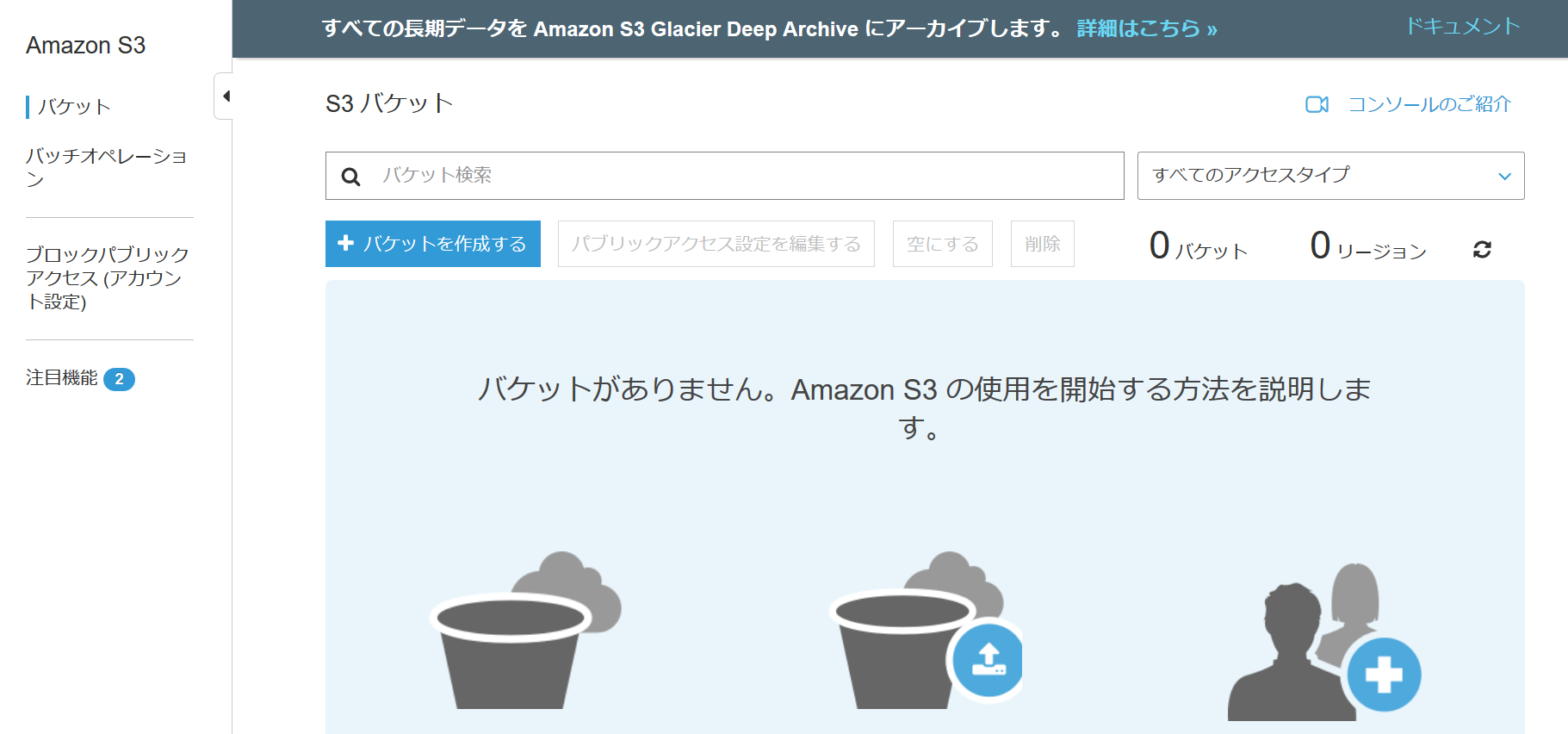
バケット名は、自由に命名して良い。今回は、「bank-xgboost」と命名した。ただし、既に使われている名前では、作成出来ないので注意が必要である。リージョンは、米国東部(バージニア北部)を指定。
※ ここで作成したバケットは、後で使うのでバケット名を覚えておく。
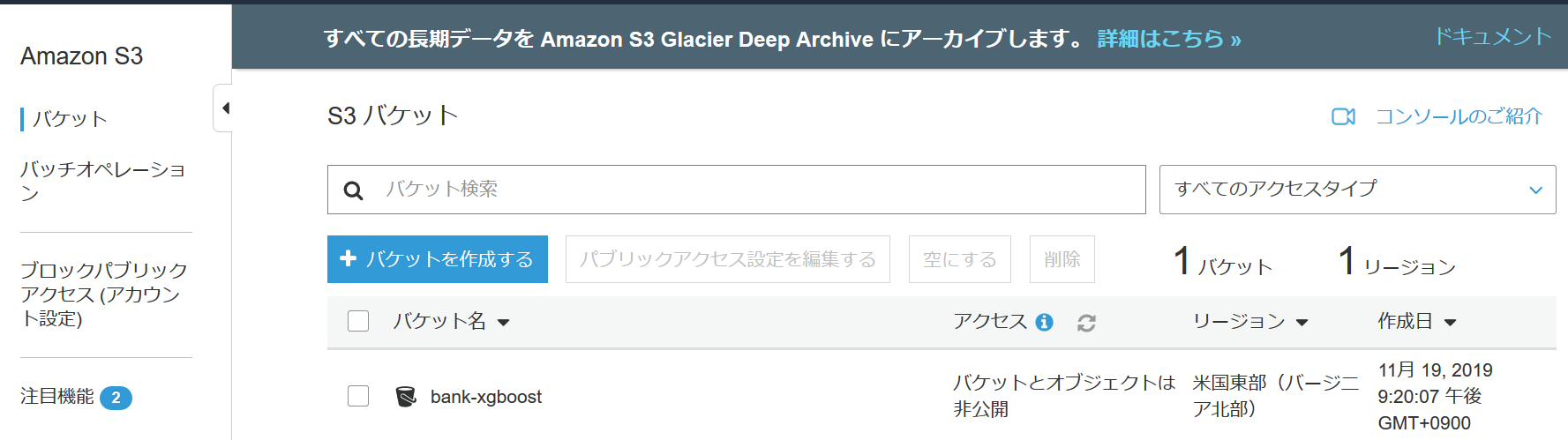
後は、特に何もせず画面の指示に従ってバケット作成を行う。バケットが作成されれば、下図の様にして自分の名付けたバケットが生成されているのが分かる。
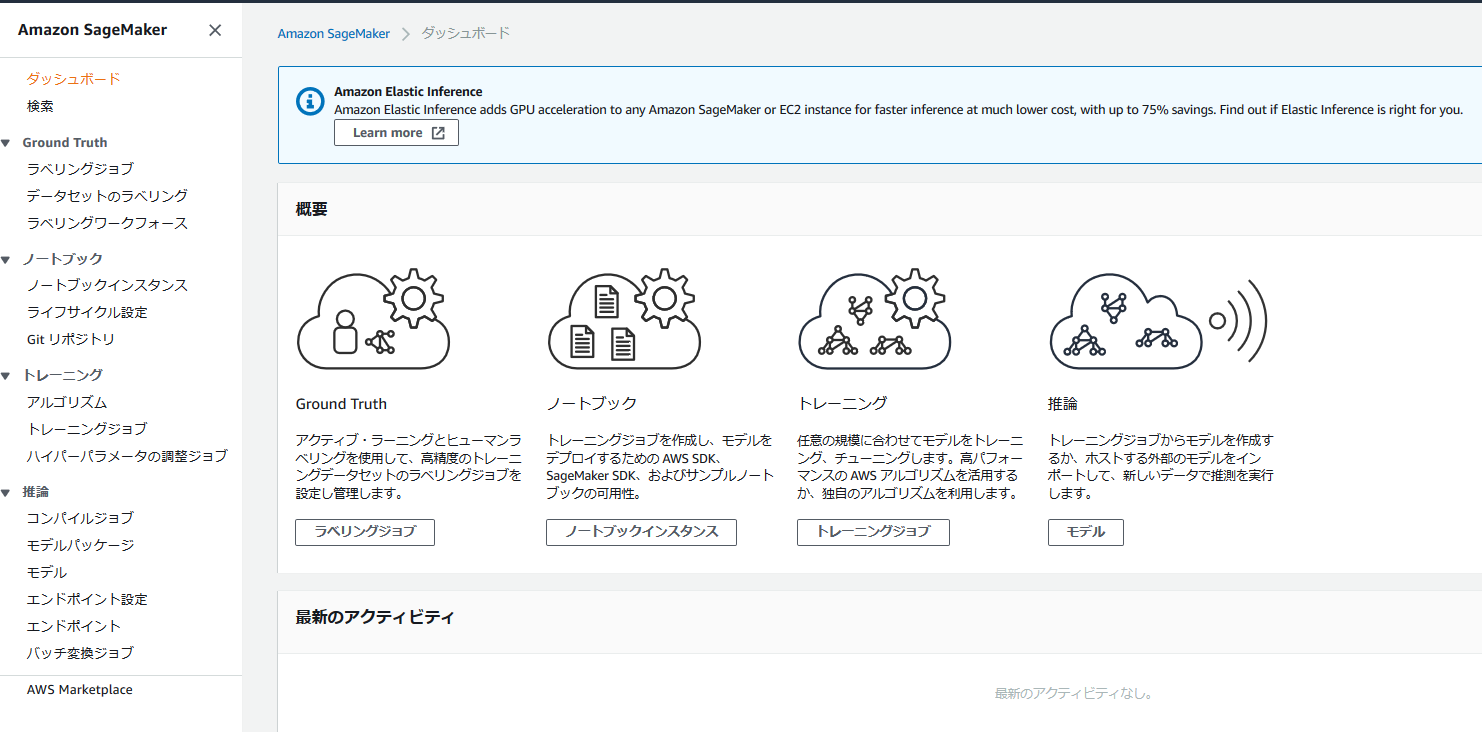
② Amazon SageMaker ノートブックインスタンスの作成
Amazon SageMakerのサービスの画面に遷移すると下記の様になっている。
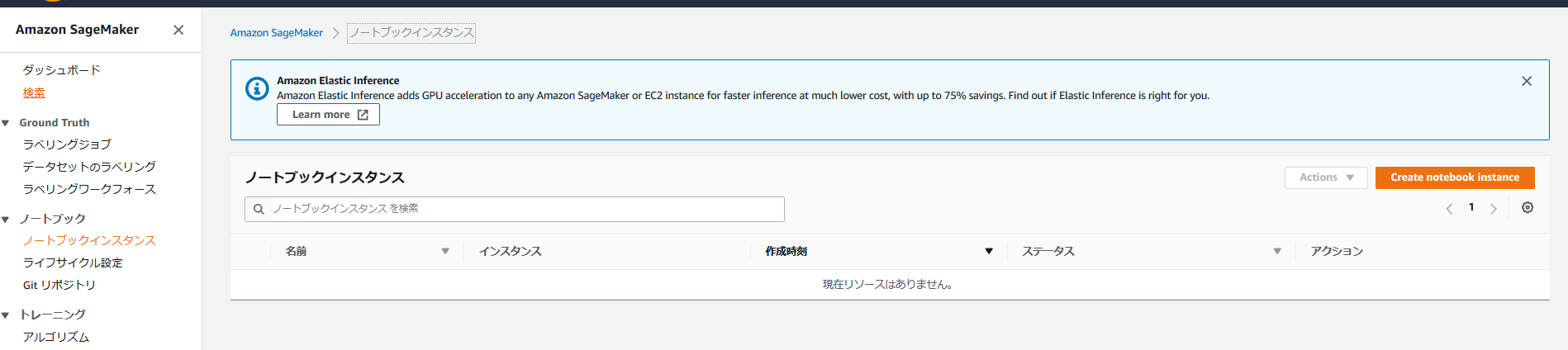
上図の「ノートブックインスタンス」を押すと、下図へと遷移する。
「Create notebook Instance」を押してノートブックインスタンスの作成へ進む。
インスタンス名は、自由に命名して良い。今回は、「bank-tutorial」と名付けた。
ノートブック構築のインスタンスのタイプは、「ml.t2.medium」でデフォルトのまま。
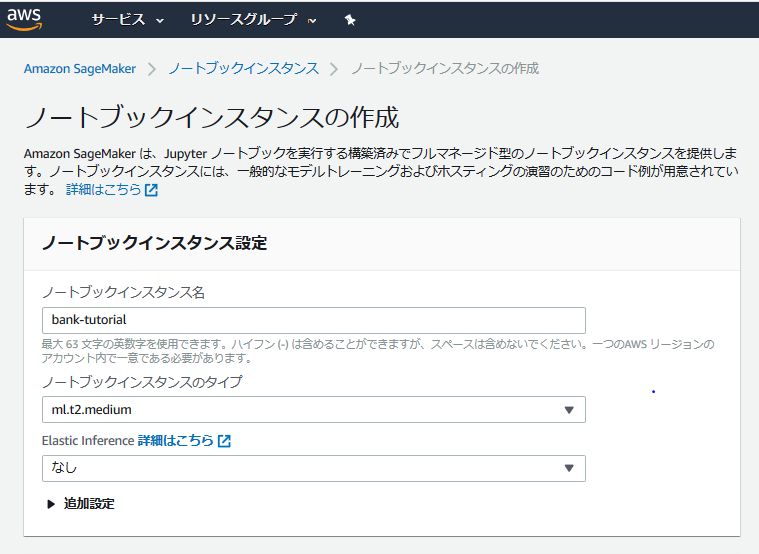
「ノートブックインスタンス設定」の下にある「IAMロールを作成する」では、指定するS3パケットを「任意のS3パケット」に指定し、ロールの作成を行う。
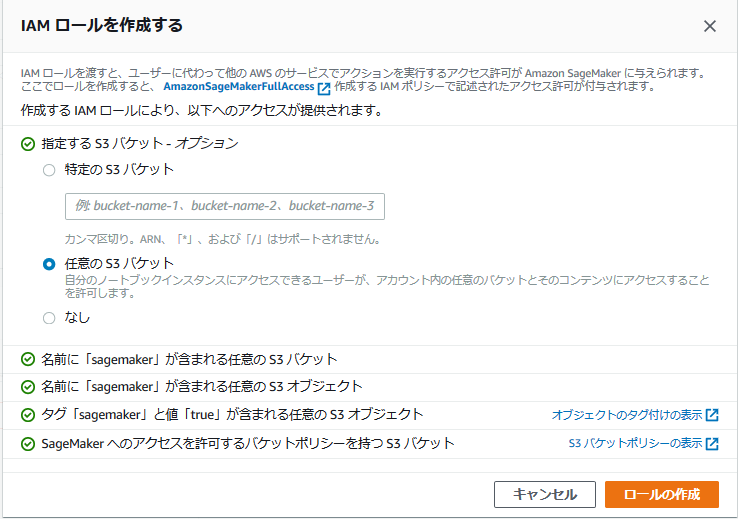
IAMロールの作成が出来たら下図の様になるので、右下の「ノートブックインスタンスの作成」を押して作成完了となる。
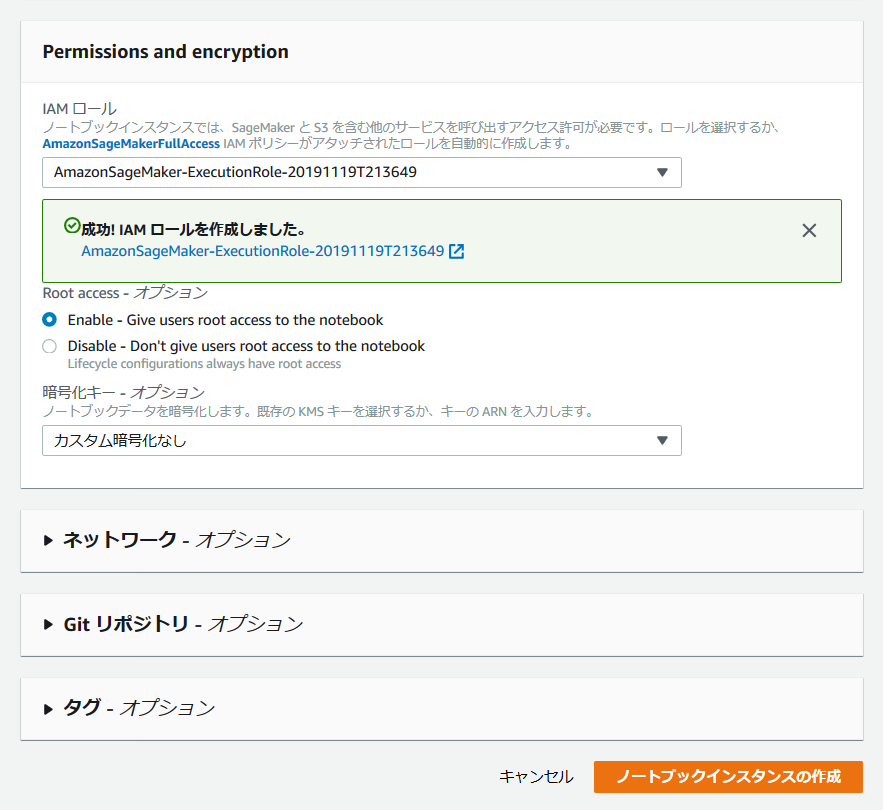
作成直後は、ステータスが「Pending」となっているが、5分程経過すれば、「InService」となり、次のステップへと進める。
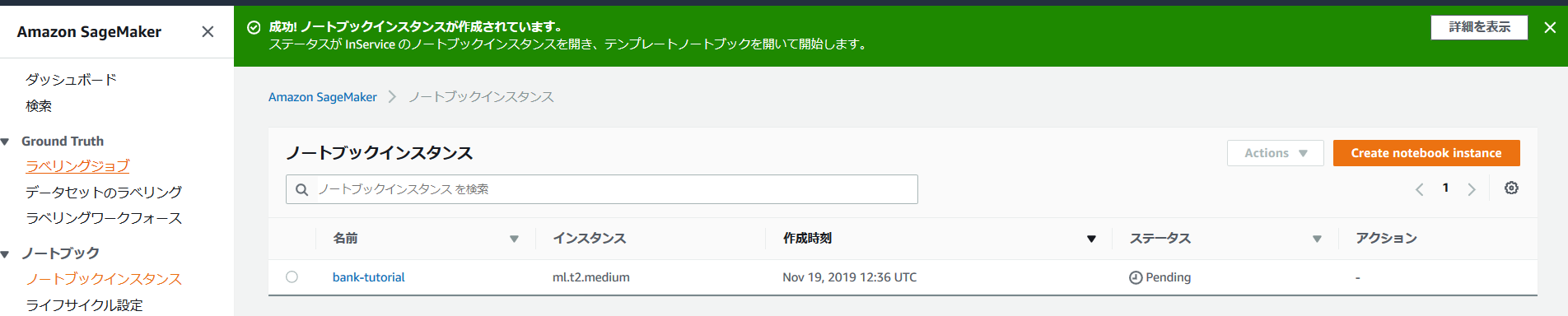
③ Jupyterノートブックを作成する
ステータスが「InService」となったら、「Open Jupyter」を押して、Jupyterノートブックのトップ画面へと遷移する。
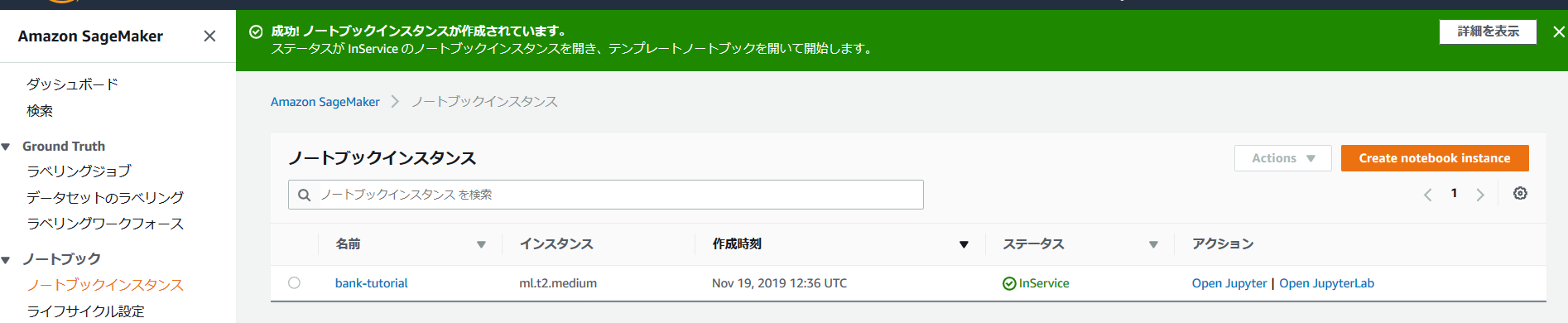
Jupyterノートブックのトップ画面に行ったら、右上の「new」で「conda_python3」を指定し、ノートブックを作成すると下図の様になる。

必要な設定変数とライブラリのインポートを行う。下記のbucketの項目は、先程決めたS3のバケット名へ変更を行う。また、SageMakerとS3のリージョンが異なると動かないので、リージョンが同じか注意が必要。
prefixで指定したフォルダがS3へ新しく作られる。特に変更は必要ないが、適宜変更しても問題はない。
最後にboto3とIAMのroleの宣言を行う。boto3だが、AWSが開発したPythonとAWSの各種サービスを統合するライブラリとなっている。
セルの実行は、Shift + Enterで行う。実行が完了したら、下図のIn[1]のようにナンバリングされていく。時々、セルの名前がIn[*]となることがあるが、それはセルの実行に時間がかかっているだけなので、暫く待ってから次のステップへと進む。
# S3のバケット名を下記に設定してください
# S3のプレフィックスを設定(変更は不要です)
bucket = 'bank-xgboost'
prefix = 'sagemaker/xgboost-dm'
# IAMのroleの宣言
import boto3
import re
from sagemaker import get_execution_role
role = get_execution_role()
次に、今回のモデル構築に使う必要なライブラリ各種をにインポートする。
機械学習の定番となるNumpy、Pandas、Matplotlibに加えて、ipython(Jupyter Notebook)で表などをプロッティングするモジュール、さらにSageMakerのPython SDKもインポートする。
import numpy as np # 行列演算および数値処理用に
import pandas as pd # 表形式データの変更用に
import matplotlib.pyplot as plt # 図などの視覚化のため
from IPython.display import Image # notebookに画像を表示するため
from IPython.display import display # notebookで出力を表示するため
from time import gmtime, strftime # SageMakerのモデル、エンドポイントなどのラベル付け用に
import sys # notebookへの出力の書き込み用に
import math # 天井関数用に
import json # ホスティング出力の解析用に
import os # ファイルパス名を操作するために
import sagemaker # Amazon SageMakerのPython SDKを用いることで、多くのhelper functionsが提供される
from sagemaker.predictor import csv_serializer # 推論時にHTTP POSTリクエストの文字列を変換する
④トレーニングデータをダウンロード、調査、および変換する
カルフォルニア大学アーバイン校のサイトにてデータセットが公開されているので、そこから直接取得する。wgetでURLから直接ダウロードして、unizipする。
# カルフォルニア大学アーバイン校の公開URLからデータセットをダウロード
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip
!unzip -o bank-additional.zip
ダウンロードしたこのcsvファイルのデータセットを、Pandasのデータフレームとして読み込む。
# bank-additional-full.csvをdataへ格納
data = pd.read_csv('./bank-additional/bank-additional-full.csv', sep=';')
# Pandasの最大表示カラム数と行数の設定を変更
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_rows', 30)
# 最初の10行を表示
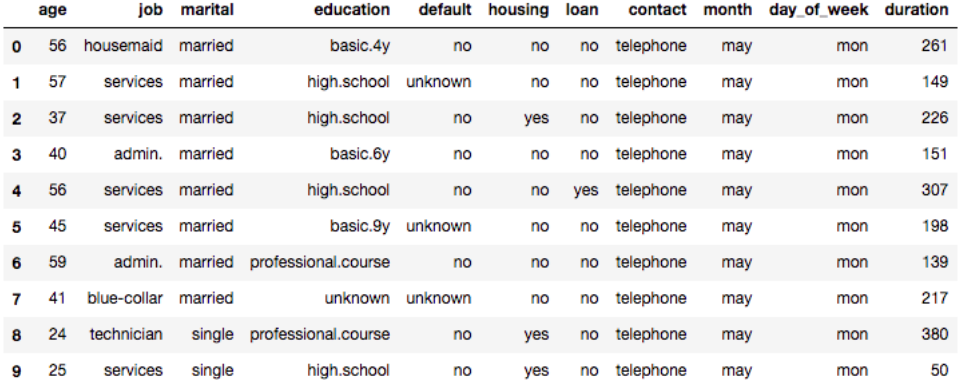
data.head(10)
データセットの最初の10行を表示させてみると、顧客の情報が格納されている事が分かる。項目の概要の一部を紹介する。
・age – 顧客の年齢
・job – 仕事のカテゴリ
・marital – 結婚ステータス
・education – 学歴
・default – クレジットの支払遅延のステータス
・housing – 不動産ローンの有無
・loan – パーソナルローンの有無 などなど...
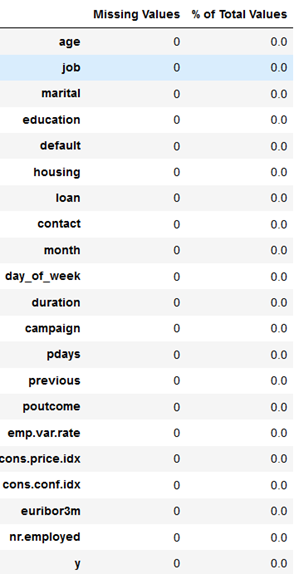
欠損データの確認を行う。欠損データがあると、その対処もまた別に議論する必要があるので、色々面倒である。
# データフレームの欠損データをまとめるテーブルの関数
def missing_values_table(df):
mis_val = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum()/len(df)
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
return mis_val_table_ren_columns
# dataに欠損があるかどうか確認
missing_values_table(data)
下図を見ると、データの欠損が1つもない事が観測できる。
流石、銀行のデータセット。
次に、データクレンジング(データセット前処理)を行う。
ほぼ全ての機械学習のプロセスで、データセットのクレンジングは必須の工程となっている。
今回は、4種類の前処理を行う。
① pdaysから連絡の取っていない顧客を抽出する
pdays(最後に連絡をとってから何日経過したか)は「999」のデータが非常に多く、前回から連絡を取っていない顧客が大半と言える。999日(つまり連絡を取っていなかった顧客)を「1」としてそれ以外を「0」とするデータ処理をする。
② jobから現在職についてない顧客を抽出する
job(職業)の項目には、unknown(不明)を含む12種類ある。この項目には、「student(学生)」や「unemployed(失業中)」など現時点で職についてない顧客が含まれている。そこで、現在働いているか、働いていないかを切り分けて新しく「not_working」(働いていない)という項目を追加する処理を行う。
③ カテゴリカルデータをダミー変数化する
数値ではないデータの数値化の手法をダミー変数という。
例えば、今回のデータで言うと、予測ターゲットの「y」ですが、持っている値が「yes」「no」となっている。これをダミー変数化すると、もともと一つの項目「y」が2つの項目「y_yes」と「y_no」に分裂して、各値に応じて「0」「1」が付与される。
④ 予測モデルに組み込まない項目の削除
最後に外部環境要因の指標(emp.var.rate)など、今回のトレーニングで使わない項目をpd.dropでデータフレームから削除する。
# 以前にコンタクトがなかった人を判別する新しい項目の追加
data['no_previous_contact'] = np.where(data['pdays'] == 999, 1, 0)
# 職業から「職についていない人」(学生など)のフラグを追加
data['not_working'] = np.where(np.in1d(data['job'], ['student', 'retired', 'unemployed']), 1, 0)
# カテゴリカルデータをダミー変数化
model_data = pd.get_dummies(data)
# 今回のモデルで使用しない項目を削除
model_data = model_data.drop(['duration', 'emp.var.rate', 'cons.price.idx', 'cons.conf.idx', 'euribor3m', 'nr.employed'], axis=1)
前処理が完了したら、次はデータを訓練データ、検証データ、テストデータの3つに分ける作業を行う。
なぜ分けるのかについてだが、簡単に言うと何度も学習させてモデルの精度を高めさせたいから、くらいの見解に今回はしておく。
# 前処理したmodel_dataをランダムにソートして3つのデータフレームに分ける
train_data, validation_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data)), int(0.9 * len(model_data))]) # Randomly sort the data then split out first 70%, second 20%, and last 10%
次がデータ前処理の最終ステップとなる。Amazon SageMaker XGBoostのコンテナのデータフォーマットは、libSVMとなっている。libSVMフォーマットだが、feature(特徴量)と予測ターゲット(目的変数)を別々のアーギュメントにしなくてはならないので、その処理を行う。
最後に、boto3経由でAWS S3へ、この訓練データセット(libSVM形式)を送っておく。
# libSVMファイルの書き出し
dump_svmlight_file(X=train_data.drop(['y_no', 'y_yes'], axis=1), y=train_data['y_yes'], f='train.libsvm')
dump_svmlight_file(X=validation_data.drop(['y_no', 'y_yes'], axis=1), y=validation_data['y_yes'], f='validation.libsvm')
dump_svmlight_file(X=test_data.drop(['y_no', 'y_yes'], axis=1), y=test_data['y_yes'], f='test.libsvm')
# Boto3を使ってS3へファイルをコピーする
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'train/train.libsvm')).upload_file('train.libsvm')
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'validation/validation.libsvm')).upload_file('validation.libsvm')
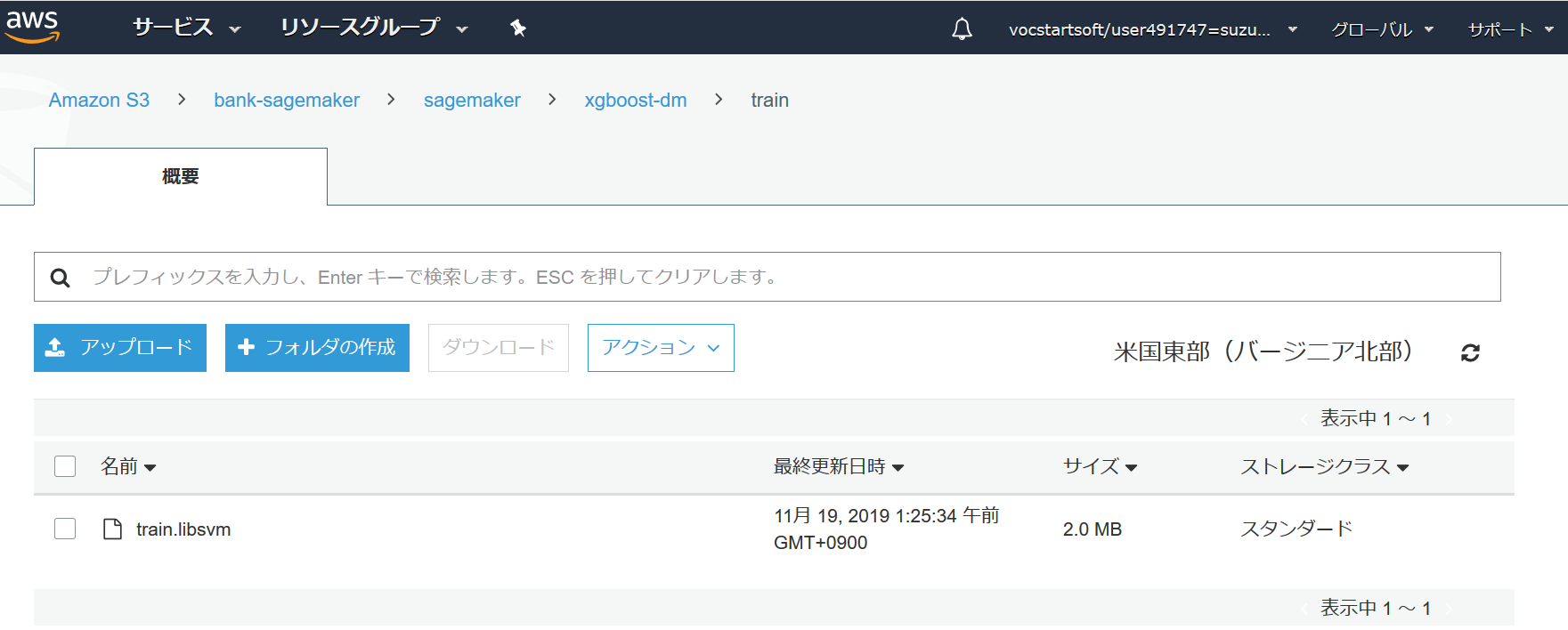
これで、最初に指定したAWS S3のバケットに新しく「sagemaker」というフォルダーが作成された。
下記の図のように、 S3 > バケット名 > sagemaker > xgboost-dm > train のディレクトリーにtrain.libsvmが新規作成されていれば、ここまで問題なく進められている。
⑤ モデルをトレーニングする
前処理が完了したので、次はいよいよXGBoostを使ってモデルの構築を行う。
まずは、Amazon SageMakerのXGBoostのためのECRコンテナの場所を指定し、訓練データ(libSVM)とS3の連携を行う。
# SageMaker XGBoostのためのECRコンテナを指定
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'}
# 訓練データとS3を連携してあげる
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(bucket, prefix), content_type='libsvm')
s3_input_validation = sagemaker.s3_input(s3_data='s3://{}/{}/validation/'.format(bucket, prefix), content_type='libsvm')
次はSageMakerのEstimatorへ必要なパラメーターとハイパーパラメーターの指定をしてあげて、フィッティングを行う。下記コードだが、トレーニング用のインスタンスとして、 「ml.m4.xlarge」を使用している。処理は、約10分程度で完了する。
# SageMakerのセッション
sess = sagemaker.Session()
# sagemakerのestimatorへ必要項目を指定
xgb = sagemaker.estimator.Estimator(containers[boto3.Session().region_name],
role,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(bucket, prefix),
sagemaker_session=sess)
# ハイパーパラメーターの指定
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
silent=0,
objective='binary:logistic',
num_round=100)
# モデルフィッティングと出力先の指定(S3)
xgb.fit({'train': s3_input_train, 'validation': s3_input_validation})
処理が上手く行けば、下記の様な文言が出てくる。
2019-11-18 16:36:46 Uploading - Uploading generated training model
2019-11-18 16:36:46 Completed - Training job completed
Training seconds: 63
Billable seconds: 63
⑥ モデルのホスティング(ここも重要ポイント)
フィッティングが終わったら、次にモデルホスティングを行う。下記のコードでは、 「ml.t2.medium」のインスタンスを利用している。これも処理完了まで約10分程度かかる。
# ml.t2.mediumのインスタンスでデプロイ
xgb_predictor = xgb.deploy(initial_instance_count=1,
instance_type='ml.t2.medium')
.
.
.
.
.
このモデルホスティングについてだが、筆者は最初「ml.c4.xlarge」インスタンスでのデプロイを試みていた。上述の参考にしているページのコードがそうなっていたからだ。
しかし、下記の様なエラーが出てしまった。
ResourceLimitExceeded: An error occurred (ResourceLimitExceeded) when calling the CreateEndpoint operation: The account-level service limit 'ml.c4.xlarge for endpoint usage' is 0 Instances, with current utilization of 0 Instances and a request delta of 1 Instances. Please contact AWS support to request an increase for this limit.
簡単に訳すと、このアカウントのリソースが限度に達したので、AWSサポートに問い合わせて上限解放して、的な事が書いてあった。
流石、Starterアカウント。
リソースが少ない...
Amazon SageMakerのインスタンス料金のページに色々なインスタンスが掲載されていたので、色々試してみたのだが、モデルのデプロイに関しては、ml.t2.mediumインスタンスしか上手く行かなかった。
だとしても、とりあえず使用するインスタンスは、
・構築**「ml.t2.medium」**
・トレーニング**「ml.m4.xlarge」**
・デプロイ**「ml.t2.medium」**
という組み合わせにしておけば、最後まで詰まることは無かったので、今後同じような事をStarterアカウントで行う人がいれば是非参考にして欲しい。
(料金が安い=リソースをあまり使わない インスタンスを採用するとリソースの上限に引っ掛からない?)
ちなみに、AWSサポートにメールで上限解放が出来ないか問い合わせてみたところ、無料枠のStarterアカウントでは、そもそも上限解放が出来ないとの事...
⑦ モデルを検証する
最初のステップとして、評価で使うデータの渡し方と受け取り方を指定してあげる。テストデータだが、現在はSageMakerノートブックのインスタンス上にNumpy配列として置かれている。これをHTTP POSTリクエストで予測モデルに送るために、SageMakerの「serializer」を使ってシリアライズ化して、さらにcontent_typeも指定しておく。
# データの受け渡しのための設定を行っておく
xgb_predictor.content_type = 'text/csv'
xgb_predictor.serializer = csv_serializer
次に、前のステップで作成したtest_dataを500行ずつの小さいバッチに小分けして、XGBoostのエンドポイントで予測を行い、Numpyの配列として出力する。
# 500行ごとの小バッチに区切ってxgb_predictorで予測算出する
def predict(data, rows=500):
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = ''
for array in split_array:
predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')])
return np.fromstring(predictions[1:], sep=',')
# 前項目で作成したtest_dataからターゲット項目を削除して予測を出力
predictions = predict(test_data.drop(['y_no', 'y_yes'], axis=1).as_matrix())
# 予測と正解データの比較テーブル
pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions), rownames=['actuals'], colnames=['predictions'])
これで、予測した値がpredictionsとしてNumpy配列に格納された。
最後に、Pandasを使って、実際の正解データと予測した「predictions」の結果をテーブルにする。
.
.
.
.
.
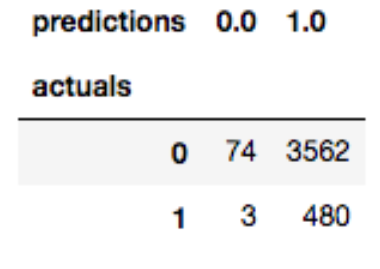
今回の予想結果は、上図のようになった。
このままでは、見にくいので下表のようにして纏めた。

これを読み解くと、
Yesと答える人が77人いると予測したが、実際にその77人の中にYesと答えた人は、3人しかいないという事である。
更には、Noと予測した人の中に、実はYesと答えていた人が480人もいたという結果であった。
今回は、あまり精度の良い解析結果とは言えないが、今回はとりあえず機械学習に触れてみるという感じだったので...
特徴量の調整やハイパーパラメーターの調整など、予測精度を改善する余地はまだまだありそう。
まだ最後に重要な作業。
本チュートリアルが終わったら、余計な料金が発生しないように、今回作成したエンドポイントを削除しておく。
# 作成したエンドポイントの削除
sagemaker.Session().delete_endpoint(xgb_predictor.endpoint)
筆者は、これに加えて、SageMakerの管理画面で「モデル」「エンドポイント」「ノートブック」の状況が確認できるので、不必要なものは適宜、削除をしておいた。
最後に
今回、Amazon SageMakerのチュートリアルを行ってみて、SageMakerの使い方や機械学習のやり方、知識などを少しだが身につけられたのではと思う。
今回行ったチュートリアル以外にもまだまだあるので、暇があれば是非とも挑戦してみたい。
ほかのチュートリアル一覧(英語) ☞ Amazon SageMaker Examples
まだ、機械学習のスタートラインにやっと立てたという感じなので、これからも色々な事をインプットし、今回のようにQiitaにまたアウトプット出来たらと思う。
稚拙な文章だったと思いますが、読んで頂き有難う御座いました。