大規模言語モデルと知識グラフについて
今回は、最近読んだ論文の中で印象に残ったものを紹介します。
あくまで、大まかなイメージをつかむもので詳細には踏み込みませんが、大規模言語モデルの長所と欠点、知識グラフの長所と欠点をそれぞれ説明した上で、お互いに補い合いながら事実に基づいた質問応答や推論などの言語タスクをこなしていく上での課題を取り上げたものになります。
まず査読前論文のarxivで共有されているUnifying Large Language Models and Knowledge Graphs: A Roadmapへのリンクを掲載します。
著作権の観点から、論文を読んだ上で私が理解したことや感じたことを中心に紹介していきますが、一部簡単な図などを引用する箇所もあります。
もし著作権者様やその関係者が問題だと感じられた場合は、お伝え頂ければ謹んで当該箇所を取り下げさせていただきます(今回引用した図は、そのままのものではなく私が作成した2次的な図になります)。
まず、現状における大規模言語モデルの長所と短所についてです。
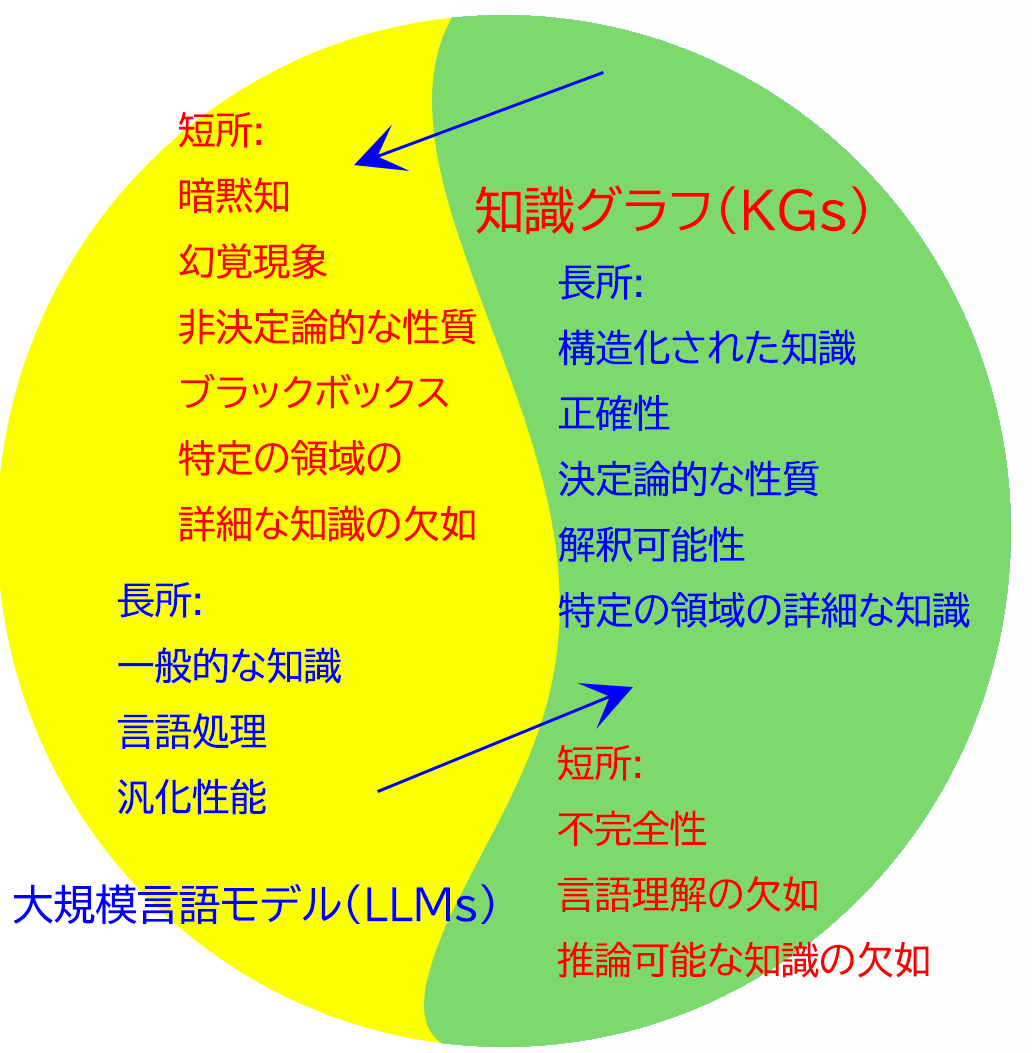
大規模言語モデルの長所・短所
長所:
・一般的な知識
・言語処理
・汎化性能
短所:
・暗黙知
・幻覚現象(言語モデルが事実とは異なる内容を創作する現象)
・非決定論的な性質(入力が同じでも必ずしも結果が同じにならない確率論的な性質)
・ブラックボックス
・特定ないしは固有の領域における詳細もしくは新たな知識の欠如
上記に挙げたような大規模言語モデルの持つ性質は、結果が重大な損失をもたらしうるようなミッションクリティカルな分野での大規模言語モデルの信頼性を大きく損なうものです。
大規模言語モデルは、自己アテンション機構を用いたトランスフォーマー型のニューラルネットワークを使用しているという性質から、出力される文章はあくまでも第一に確率統計学的に尤もらしい文章である事が最優先されるため、出力された文章が事実であるかどうかには、そもそも主眼が置かれていないという理由があります。
とはいえ無論、大規模言語モデルは学習の過程で事実を含む大量のテキストから学習しているため、その結果として事実を含む内容を生成することもまた事実で、この事が近年大規模言語モデル、例えばChatGPTやBERT、RoBERTA、T5、PaLM2といった大規模言語モデルが注目を浴びるようになった原因でもあります。
一方で古くからある分野として、構造化された知識を体系立てて組み立てる「知識グラフ」というものがあります。
知識グラフ(Knowledge Graphs)の長所・短所としては以下のようなものが挙げられます
知識グラフは大規模言語モデルほど近年注目を浴びるようになったものではなく、従来から存在した概念で、情報を整理し、関連性を明確にするためのデータ構造をイメージするといいでしょう。
それらは「事実」や「概念」といった「ノード」と呼ばれるものと、それらの間の関連を示す「エッジ」により構成されます。
知識グラフの長所と欠点
長所
・構造化された知識
・正確性
・決定論的な性質
・(人間にとって)解釈が可能な性質
・特定ないしは固有の領域における詳細もしくは新たな知識を持つこと
・進化する知識(時間の移り変わりと共に内容が変化していく性質のこと。常に新しい知識を持つ性質)
短所
・不完全性
・言語理解の欠如
特定の表現でのみ表され、人間にとって言い換え可能な他の表現でも同様に正しいのかどうか分かりにくい性質
・推論によって自明な事実
これは直接文章には書かれていないものの推論によって導く事が出来る新たな事実を、自動的に捉える能力に限りがあるという意味になります。
ここまでの要約
この大規模言語モデルと知識グラフの長所と短所は相互補完的であり、この2つを有意義に組み合わせるもしくは相乗効果を得るような使い方をすることで、大規模言語モデルの長所を最大限に活かし、知識グラフの持つ解釈可能性や正確性を担保しつつ、柔軟な言葉の言い回しを用いても質問に正確に答えられるようになるという将来の研究のロードマップを示したものが本論文の要旨になります。
この2つの技術をどのように組み合わせるのがよいかというのは、学者の間でも意見が分かれるところで完璧な解決策への道は示されていませんが本論文では主に、
"KG-enhanced LLMs" 「知識グラフにより強化された大規模言語モデル」
"LLM-augumented KGs" 「大規模言語モデル拡張型知識グラフ」
"Synergized LLMs + KGs" 「相乗効果型・大規模言語モデルと知識グラフ」
の3つを軸にして将来の研究のフォワードルッキングな展望を示しているものとなります。
上記の3つのうち比較的実用化が進みつつある(ないしは最も実用化が進んでいる)ものが、知識グラフの情報を拡張する「LLMs-augmented KGs」で、関連性のある文章を大規模言語モデルに提示して、提示した文章に記載された事実から、質問者の質問に応答するいわゆる検索(リトリーブ)といわれる分野になります。
大規模言語モデルと知識グラフの相互補完性については興味深い点もあるため、また機会があったら触れようかと思います(正確さを目指すあまり、身構えてしまって新規記事の掲載がなかなか進まないのは最新技術で解決出来ないものでしょうか💧)